What Gemma 4 12B Brings to Local AI Inference
Gemma 4 12B is a 12‑billion‑parameter multimodal AI model designed for local AI inference, letting laptops process text, images, and audio directly without depending on cloud servers, so users gain lower latency, more privacy, and practical edge AI models that run on everyday hardware. Google DeepMind built Gemma 4 12B to run on consumer machines with 16GB of system RAM or VRAM, using about half the memory of the larger Gemma 4 26B model while staying close to it on benchmark performance. The weights, published under the Apache 2.0 license, are available on platforms like Hugging Face and Kaggle and occupy just under 18GB. Positioned between phone‑oriented E2B/E4B variants and heavyweight data‑center models, Gemma 4 12B targets users who need capable multimodal AI on a multimodal AI laptop without specialized accelerators or cloud infrastructure.

Architectural Efficiency: Multimodal Without Heavy Encoders
Gemma 4 12B’s efficiency comes from a streamlined multimodal design that removes the separate vision and audio encoders common in many edge AI models. Instead of running images through a large vision transformer stack, it uses a compact 35‑million‑parameter embedding module that slices images into 48×48 pixel patches and maps them into the model’s hidden dimension with a single matrix multiplication and positional embeddings. That small component replaces 27 vision transformer layers and roughly 550 million parameters found in other Gemma 4 variants, cutting memory use and latency. For audio, Gemma 4 12B skips a dedicated encoder altogether. It segments 16 kHz audio into 40‑millisecond frames and projects the raw waveform directly into the same vector space used for text tokens. This unified pathway allows the model to handle speech recognition, speaker diarization, image understanding, video analysis, and code generation with fewer components and a smaller footprint.
LiteRT-LM Optimization and Multi-Token Prediction Speedups
LiteRT-LM adds a second layer of speed to Gemma 4 through LiteRT-LM optimization focused on large language model workloads. Built on LiteRT, formerly TensorFlow Lite, it is tuned for devices with limited memory and varied hardware, using advanced quantization plus accelerated XNNPACK and MLDrift kernels. Its standout feature is native support for Gemma 4 Multi-Token Prediction drafters, which use speculative decoding to guess several future tokens at once. According to Google, this yields up to 2.2x faster inference for Gemma 4 E4B and 1.6x for Gemma 4 E2B. LiteRT-LM keeps both the main model and MTP drafter on the same hardware unit, ensuring shared KV cache and activations stay in local memory and avoiding cross‑device synchronization delays. Prefill and decode stages reportedly run 1.8x to 3.7x faster than competing frameworks such as llama.cpp, MLX, Cactus, and ONNX.

Framework Expansion: Swift, Kotlin, C++, and JavaScript
The practical impact of Gemma 4 12B and LiteRT-LM depends on how easily developers can adopt them. LiteRT-LM addresses this by expanding beyond its initial Kotlin and C++ support to add new Swift and JavaScript APIs. That means developers can integrate local AI inference into Android apps, iOS apps, web experiences, and desktop tools using familiar languages. A specialized orchestration layer manages optimized pipelines, reducing CPU‑GPU data transfers while handling multi‑token prediction, KV cache saving and restoring, and session management for long conversations. For experimentation, a command‑line interface supports desktop workflows, while a mobile app shows on‑device usage. Together, Gemma 4 12B and LiteRT-LM let teams build multimodal AI laptop applications that stay responsive and memory‑efficient, without requiring heavy server infrastructure or bespoke runtime engineering.
Why Local AI Inference Matters for Privacy and Latency
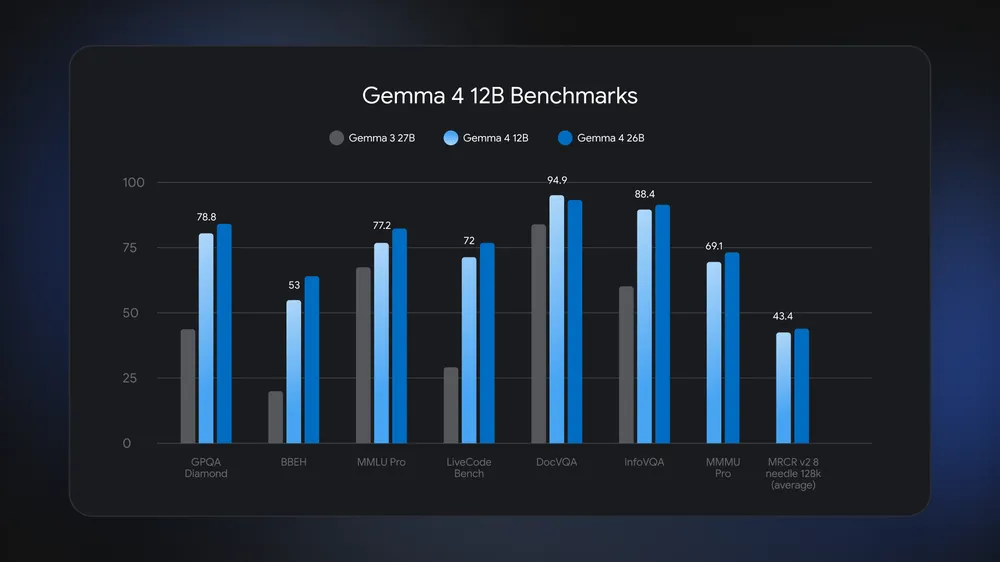
Running Gemma 4 12B locally on a multimodal AI laptop has clear benefits for privacy, latency, and resilience. Data such as documents, images, or audio recordings never leave the device, which is essential for users handling sensitive information or working offline. Local AI inference removes the round‑trip delay to remote servers, so multistep reasoning, agentic workflows, and rich multimodal tasks feel more responsive. Google reports Gemma 4 12B outperforms the earlier Gemma 3 27B on benchmarks like GPQA Diamond, MMLU Pro, and DocVQA, showing that local edge AI models no longer mean a steep quality compromise compared to larger cloud models. Combined with LiteRT-LM optimization and Multi-Token Prediction, users gain fast, capable assistants that run on standard 16GB machines, even as memory prices climb. This shift brings frontier‑class AI experiences closer to everyday personal computing.




