
Why Storage Architecture Matters More Than You Think
For time-series workloads, storage architecture often has more impact on cost and query performance than the choice of database engine itself. Every system that tracks metrics, events, or sensor readings ultimately needs to answer the same questions: how quickly can you write new points, how efficiently can you scan a time range, and how cheaply can you retain history? In a time-series database storage design, the core knobs are row layout, compression timing, and partitioning strategy. Together, they determine how many bytes each datapoint consumes, how much data your queries must scan, and how easily you can age out old information. Because time-series data is highly repetitive—timestamps, identifiers, and metrics repeating millions of times—small per-row inefficiencies add up quickly. Organizations that treat storage as an afterthought often end up with ballooning storage bills and sluggish dashboards, even when they are using otherwise capable database technology.

Row Layout: Flat vs. Normalized Series Identity
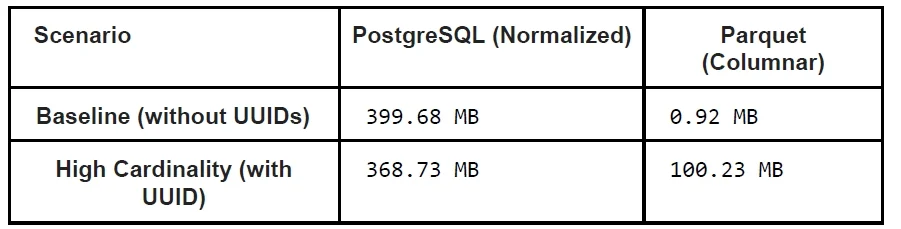
Row layout is the first major lever for query performance tuning and storage efficiency. A flat schema stores every dimension—such as device, location, and region—on every row. This is simple to query, but it repeats long strings millions of times. A normalized layout instead separates series identity into a metadata table and references it via a compact series ID. In one PostgreSQL experiment with about 2.8 million rows and one thousand series, this approach reduced time-series storage by roughly forty-two percent while preserving similar range-read performance and even improving some aggregates. The key is that the series ID is much smaller than the full dimension set, and the dimension bytes are stored once per unique series instead of per row. However, normalization only helps when dimensions are repeatable; if you include high-cardinality fields like request IDs in the identity, the number of series approaches the number of rows and the benefit collapses.

Compression Timing: Balancing Space Savings and Read Speed
A storage compression strategy for time-series data must weigh when and how aggressively to compress. Compressing data early—on ingest or shortly after—can dramatically shrink disk footprint and I/O, especially when combined with normalized layouts and columnar formats. However, heavily compressed segments can be slower to query if they must be decompressed for every dashboard refresh or alert evaluation. Delaying compression keeps recent data in a more query-friendly format, at the cost of higher near-term storage usage. Many systems implicitly introduce a tiered approach: hot data remains less compressed and fully indexed for low-latency analytics, while older partitions are compressed more tightly or moved to columnar storage. The right timing depends on your access patterns: if most queries target the last few hours, it makes sense to optimize that window for speed and treat historical partitions as a space-optimized, slightly slower analytics tier.
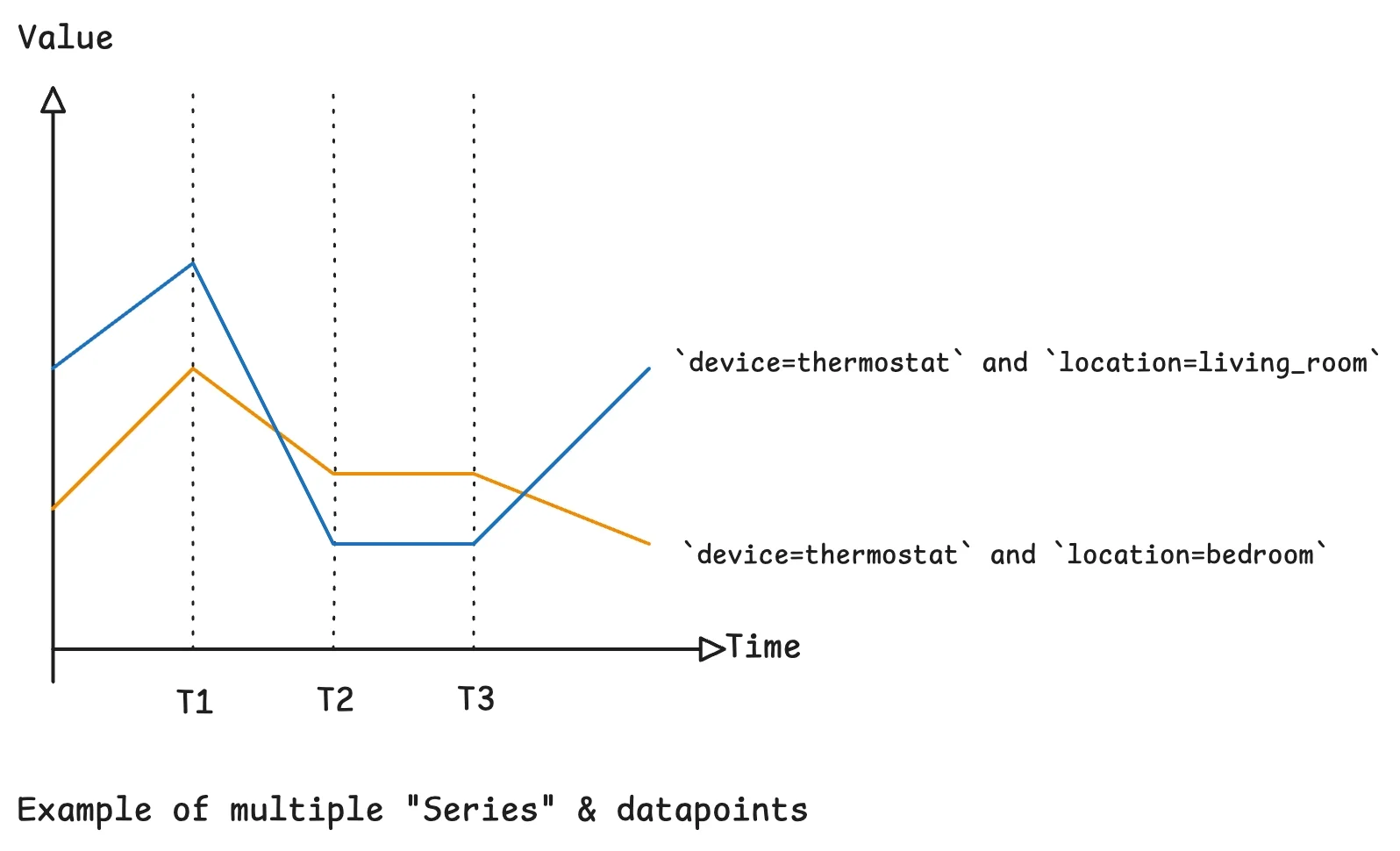
Partitioning Strategy: Time First, Then Identity
Database partitioning optimization is especially powerful for time-series workloads because queries almost always include a time filter. Time-based partitioning lets you prune entire chunks of data quickly and expire old partitions in constant time, instead of deleting rows one by one. The downside is that writes concentrate on the current time window, creating a hotspot. Introducing a second partitioning axis—often series identity or a hash of it—distributes writes more evenly and narrows the amount of data each query scans. This two-dimensional approach also enables better parallel processing, since different partitions can be scanned concurrently. When combined with thoughtful indexing on dimensions and metrics, partition pruning reduces both CPU and I/O for common queries. The practical outcome is faster dashboards and alerts, plus simpler retention management, all driven by how you slice the time and identity space in your storage design.
Designing Around Real Query Patterns
Effective time-series database storage design starts from actual query workloads, not abstract best practices. Before committing to a row layout, storage compression strategy, or partitioning scheme, you should map out the questions engineers, analysts, and automated systems ask most often. If typical queries group by stable tags like device and location, those belong in normalized series identity and indexed dimensions. If you routinely join on per-event IDs, you may accept higher cardinality in exchange for analytic flexibility. Similarly, if alerts mostly target the last hour, prioritize fast scans over aggressive compression for that window, while pushing older data into compressed, downsampled rollups. A clear understanding of access patterns—time ranges, filters, aggregations, and required retention—turns storage decisions into deliberate trade-offs instead of guesswork. The result is a time-series storage architecture that cuts costs and boosts query speed where it matters most.