When RAG Precision Tuning Backfires
New research from Redis shows that RAG precision tuning can quietly erode the very retrieval accuracy teams rely on. When embedding models are fine‑tuned for "compositional sensitivity" – distinguishing near‑identical sentences with different meanings, such as flipped negations or subject–object swaps – dense retrieval generalisation drops. Smaller models lose around 8–9% performance, while a widely used mid‑size RAG embedding model suffers about a 40% collapse in retrieval accuracy. The catch is that standard fine‑tuning metrics look excellent: the model gets better at rejecting near‑misses on the specific training task. But its ability to retrieve the right documents across unrelated topics quietly degrades and only shows up in production. For agentic AI pipelines, where one bad retrieval can trigger a chain of wrong tool calls or business actions, this is not a minor regression – it is a systemic reliability risk for enterprise copilots, internal chatbots and decision support tools.
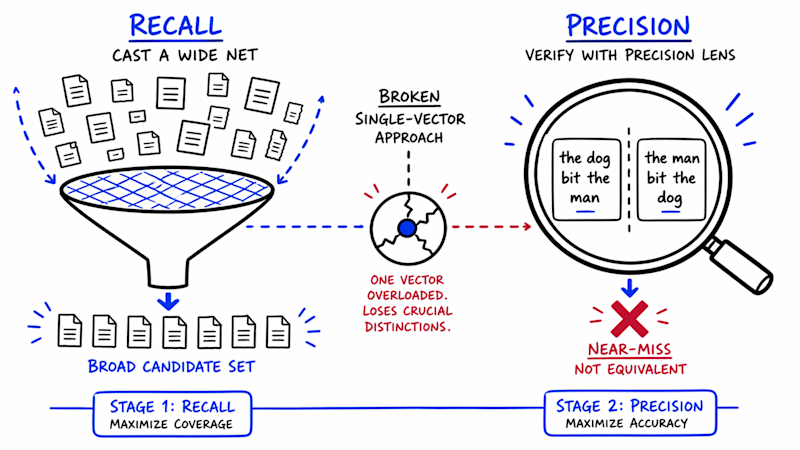
RAG, Embeddings and the Precision–Recall Trap
Retrieval‑Augmented Generation pairs a retriever with a generator. The retriever converts queries and documents into vectors and fetches the closest matches from a vector database; the generator (an LLM) then reasons over those snippets to answer the user. RAG embedding models are therefore the gatekeepers of what the LLM is even allowed to see. By design, dense retrievers juggle a retrieval accuracy tradeoff between precision and recall. Precision tuning tries to avoid “almost right” passages that subtly contradict the query. But the Redis work shows that when a model is trained hard to separate structurally different sentences, it spends representational capacity that previously helped it cluster broadly related documents. Precision improves on edge cases like negations, yet recall falls as less obvious but still relevant documents drift away in vector space. In practice, users see confident answers grounded in an increasingly narrow, and sometimes wrong, slice of your knowledge base.
Why Hybrid Search RAG and Bigger Models Don’t Magically Save You
A common response to retrieval problems is to mix dense and keyword search in hybrid search RAG, or simply adopt a larger embedding model. The research suggests neither is a guaranteed fix. Keyword search shines when the issue is missing or rare terms; here, the failure mode is structural, not lexical. Sentences like “Rome is closer than Paris” versus “Paris is closer than Rome” share almost identical tokens, so a keyword layer cannot disambiguate them after the embedding model has already retrieved the wrong passage. Likewise, scaling up model size or vector dimensions does not address the underlying geometry. The competing objectives – fine‑grained compositional sensitivity and broad topical generalisation – still occupy the same representational space. Teams in Malaysia and across ASEAN building enterprise search, legal assistants or financial copilots on proprietary corpora should assume that “just add hybrid search” or “upgrade the model” will not automatically restore healthy recall.
Agentic AI Pipelines: From Single Wrong Answer to Cascading Failure
Agentic AI pipelines amplify the stakes of RAG precision tuning. In a simple chatbot, a retrieval miss usually means one wrong answer. In an agentic workflow – for example, an AI that interprets an internal policy, drafts an email, then opens tickets or updates records – that same miss can cascade through several steps. The Redis study also found that not all error types benefit equally from compositional training: negation and spatial flips improve, but binding errors, such as who owes what in a contract, barely move. Those are precisely the kinds of mistakes that hurt banks, insurers, telcos and government agencies. For organisations in Malaysia modernising internal knowledge systems, this should be a governance concern. If your copilot can silently omit relevant but less “obvious” documents, it may comply with the wrong policy, misassign responsibilities or overlook exceptions that local regulations require you to honour.
Safer Tuning and Evaluation for RAG Embedding Models
To avoid breaking retrieval while chasing precision, teams need more rigorous evaluation for RAG embedding models. First, go beyond simple top‑k accuracy on the fine‑tuning task. Maintain a broad, domain‑diverse retrieval benchmark and track recall and coverage across topics you did not train on. Include stress tests: negations, role swaps, temporal changes and subtle contractual bindings drawn from your own Malaysian and regional documents. Second, test your full pipeline, not just the retriever. Use end‑to‑end evals where agents must complete realistic tasks using internal data, and monitor how often they depend on missing or incorrect context. Third, prefer light or multi‑objective tuning that explicitly regularises for generalisation, and keep a frozen baseline model as a safety reference. Finally, choose vector databases and hybrid search setups for scalability and latency, but do not treat them as substitutes for careful measurement of the retrieval accuracy tradeoff introduced by precision tuning.