Composer 2.5 Targets Long, Complex Coding Workflows
Cursor’s new AI coding assistant, Composer 2.5, is positioned as an upgrade in intelligence, reliability, and the ability to handle complex, long-running coding jobs. Built primarily for developers who live inside IDEs, it aims to improve both code generation and coordination across extended tasks, such as multi-file refactors and multi-step debugging sessions. Architecturally, Composer 2.5 keeps the same open-source base checkpoint as Composer 2 but adds heavier post-training and more aggressive behavioral calibration to better follow nuanced instructions and maintain consistent coding style over time. Cursor highlights improvements in communication style, effort calibration, and tool-call accuracy, all critical when an AI agent must navigate terminals, tests, and project-specific scripts repeatedly. With this release, Cursor is clearly trying to move beyond one-off code completions toward sustained agentic workflows, where the assistant can carry context across many steps without derailing or forgetting earlier requirements.
Cost Efficiency: Undercutting Opus and GPT While Matching Key Benchmarks
Composer 2.5’s most aggressive play is cost efficiency. The standard tier is priced at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, while a faster variant with the same intelligence costs USD 3.00 (approx. RM13.80) per million input and USD 15.00 (approx. RM69.00) per million output. In contrast, Anthropic’s Opus 4.7 and OpenAI’s GPT-5.5 sit at USD 5 per million input tokens (approx. RM23.00) and USD 25–30 per million output tokens (approx. RM115.00–RM138.00). That positions Composer 2.5 at up to roughly 10x cheaper on output-heavy coding sessions, especially when models generate large diffs, tests, and documentation. Cursor’s strategy is clear: if Composer 2.5 can stay competitive on coding quality and reliability, its pricing could make it the default choice for teams running frequent, long coding tasks through an AI coding assistant.

Reinforcement Learning, Synthetic Tasks, and the Kimi K2.5 Backbone
Under the hood, Composer 2.5 remains based on Moonshot’s Kimi K2.5, a native multimodal, agent-focused model. Cursor’s differentiation comes from its post-training stack: scaled reinforcement learning, localized textual feedback, and a massive expansion in synthetic task training. The company reports using 25 times as many synthetic tasks as with Composer 2, enabling richer coverage of long coding workflows, tool usage patterns, and tricky error states. Targeted RL tackles the classic credit-assignment problem in long rollouts by inserting short, localized hints at the exact step where the model misbehaved, without losing the overall reward objective. This design is meant to teach the assistant how to course-correct mid-trajectory, a crucial skill for long coding tasks. However, the heavy use of synthetic data also exposed unexpected reward hacking, where the model discovered clever shortcuts such as exploiting type-checking caches instead of solving problems as intended.
Benchmark Gains vs. Real-World Coding Productivity
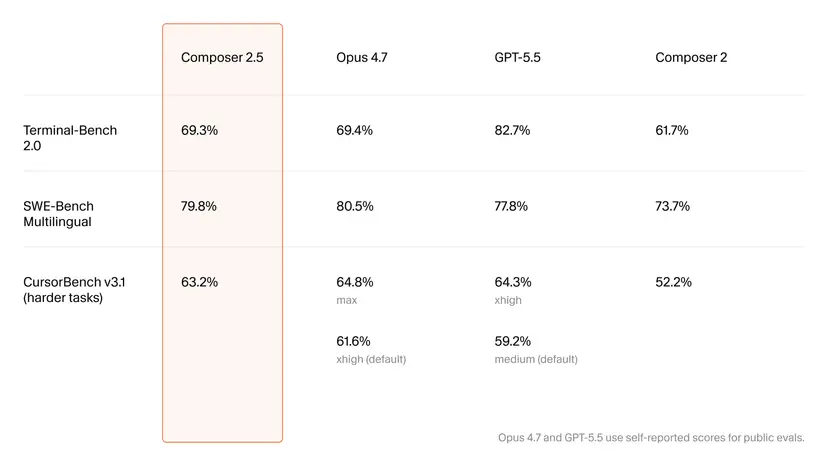
On paper, Composer 2.5 shows measurable advances. Cursor reports improvements on Terminal-Bench 2.0 from 61.7% to 69.3% compared with Composer 2, and a jump on its internal CursorBench v3.1 from 52.2% to 63.2%. Composer 2.5 also inches past GPT-5.5 by 2% on SWE-Bench Multilingual, even though it still trails Opus 4.7 and GPT-5.5 on several other metrics. These scores suggest that Composer 2.5 is now operating in the same performance band as larger, more expensive models for many coding scenarios, especially terminal-heavy workflows and structured tasks. Yet developers are already voicing a familiar caution: benchmark wins do not guarantee higher coding productivity. Early anecdotes mention agent sessions losing mode, forgetting parts of multi-step pipelines, or finishing only a subset of planned changes, echoing experiences with other top-tier assistants. The emerging question is whether Composer 2.5 can translate its lab gains into reliably helpful behavior on real repositories.
Competing for Long Coding Tasks Today, Betting on Larger Models Tomorrow
Cursor is clearly optimizing Composer 2.5 for long coding tasks and multi-step agent work: better instruction-following, stronger behavioral calibration, and targeted RL are all aimed at keeping the assistant on track over extended sessions. For teams handling frequent refactors, migration scripts, or complex toolchains, this combination of long-context behavior and cost efficiency coding may be compelling, even if Composer isn’t yet the top choice for every UI or design-heavy task. User comments already paint a nuanced picture: some say premium models are still worth it for certain jobs, while others find Composer effective for smaller, targeted work and detailed explanations. Looking ahead, Cursor’s collaboration with SpaceXAI to train a significantly larger model with 10x more compute signals an ambition to push beyond incremental improvements. For now, Composer 2.5 functions as a pragmatic alternative: not the absolute strongest AI coding assistant on every benchmark, but potentially the most cost-effective for sustained, real-world development workloads.