Near-Frontier Performance at a Fraction of the Cost
Gemini 3.5 Flash arrives as a Flash-series model that performs like a frontier system. On the independent Artificial Analysis Intelligence Index, it scores 55, landing within two points of Anthropic’s flagship Claude Opus 4.7 and just five points behind GPT-5.5. What makes this noteworthy is not only the score, but the economics behind it. Google prices Gemini 3.5 Flash at USD 1.50 (approx. RM6.90) per million input tokens and USD 9.00 (approx. RM41.40) per million output tokens, while GPT-5.5 launched at USD 5.00 (approx. RM23.00) input and USD 30.00 (approx. RM138.00) output. That puts Flash at roughly one-third the per-token price of its primary rival. In practical terms, developers and enterprises can target near-frontier AI model performance comparison outcomes while dramatically lowering inference costs, especially for high-volume workloads like assistants, internal tools, and continuous agents.

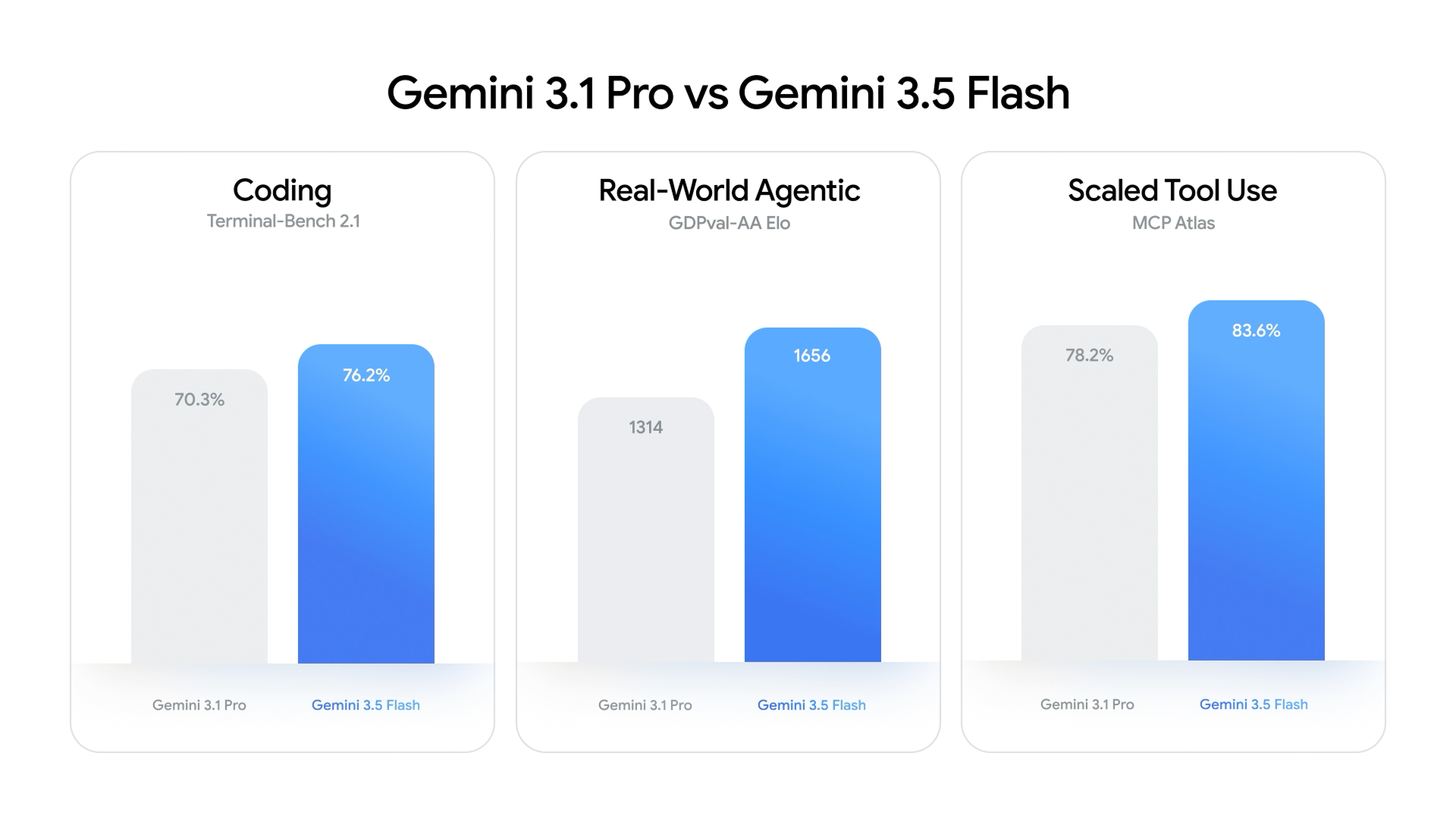
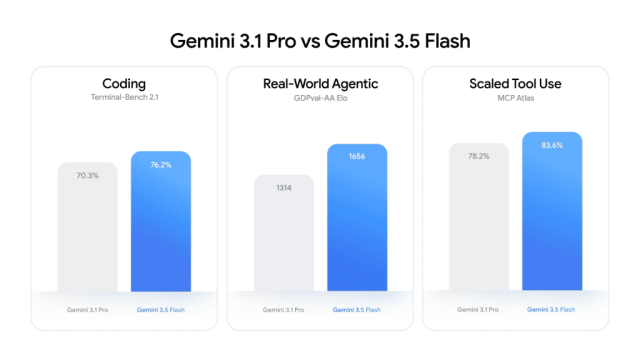
Outpacing Rivals on Coding and Agentic Benchmarks
Despite belonging to the traditionally ‘fast and cheap’ Flash tier, Gemini 3.5 Flash posts coding benchmark results that surpass Google’s own Pro line. On Terminal-Bench 2.1, a coding benchmark, it scores 76.2% versus Gemini 3.1 Pro’s 70.3%. Its agentic AI capabilities show a similar jump: on GDPval-AA, which tracks real-world agentic tasks, Gemini 3.5 Flash reaches an Elo score of 1656 compared with 3.1 Pro’s 1314. For scaled tool use, measured by MCP Atlas, it scores 83.6% against 3.1 Pro’s 78.2%. These gains move Google from incremental improvements to a clear step-change in agent reliability and autonomy. Crucially, Gemini 3.5 Flash is designed for long-horizon tasks: it can plan across large codebases, orchestrate subagents in parallel, and maintain complex workflows, narrowing the gap with Anthropic and OpenAI on real-world, multi-step automation.
Speed and Cost: The New Economic Baseline for AI Agents
Speed is where Gemini 3.5 Flash further reshapes AI model economics. Google CEO Sundar Pichai says the model delivers 289 tokens per second, roughly four times faster than comparable frontier models. Combined with its lower price per token, this throughput changes the cost structure of running agents at scale. Rather than reserving high-intelligence models only for occasional queries, developers can now afford to keep agents continuously active: monitoring pipelines, triaging support tickets, refactoring code, or validating data. Because many tasks—routing, tool calling, state checks—do not require maximal intelligence, a fast, relatively inexpensive model that still offers strong reasoning can handle most of the workload. This leaves more expensive models for only the hardest problems, reducing total cost per task while keeping responsiveness high, a critical factor for interactive tools and production-grade automation.
From ‘Fast Answer’ to Agentic Default Across Google Products
Gemini 3.5 Flash also marks a strategic pivot in Google’s Flash line: from simple speed to autonomy. Historically framed as a practical, lower-latency option for quick chatbot responses, Flash is now positioned as the engine for agentic workflows. Google describes 3.5 Flash as its strongest model yet for agents and coding, and has made it the default powering the Gemini app and AI Mode in Search. It also underpins Gemini Spark, a personal AI agent that runs continuously to take actions on a user’s behalf. On the developer side, 3.5 Flash integrates with Google’s Antigravity platform, enabling the deployment of multiple subagents in parallel. This shift pulls Flash closer to workflows where software acts—planning, executing, and iterating—rather than merely explaining. In effect, Gemini becomes a cross-product layer for autonomous tasks rather than a single chatbot destination.

Implications for Developers and the AI Model Landscape
For startups and enterprises, Gemini 3.5 Flash reframes how to evaluate AI platforms. The question is no longer just which model tops a leaderboard, but which delivers the best balance of intelligence, latency, tool integration, and AI model pricing for real workloads. A Flash-tier model that matches or nearly matches frontier benchmarks makes it economically viable to embed AI in more parts of a product: customer support agents, internal operations tools, sales workflows, or code assistants. Google’s broader stack—Gemini API, Google AI Studio, Antigravity, and Vertex AI—lowers friction for prototyping and deployment on the same model family. While Anthropic and OpenAI still lead in some frontier metrics, Gemini 3.5 Flash’s blend of near-frontier intelligence, fourfold speed gains, and aggressive pricing pressures rivals to respond. The competitive race is shifting from spectacular demos toward sustainable, production-grade agent platforms.