Enterprises Push for Cheaper, Safer AI Agents
Enterprises are racing to embed AI agents into workflows, but two constraints keep surfacing: runaway token spend and fragile security models. Traditional stacks were designed for humans, assuming slow interaction, manual credential handling, and explicit oversight of every action. Autonomous agents break these assumptions, operating at machine speed and running for long periods without direct supervision. This gap is driving demand for open-source AI agents that combine token cost reduction with robust enterprise AI security. OpenSquilla and OpenShell are emerging as complementary answers to this challenge. One focuses on model routing optimization and memory efficiency to avoid unnecessary inference costs. The other rebuilds the runtime layer as a sandbox-first environment that isolates agents from host systems. Together, they showcase how open-source infrastructure can deliver both cost transparency and defense-in-depth for production AI deployments.
OpenSquilla: Model Routing Optimization and Token Cost Reduction
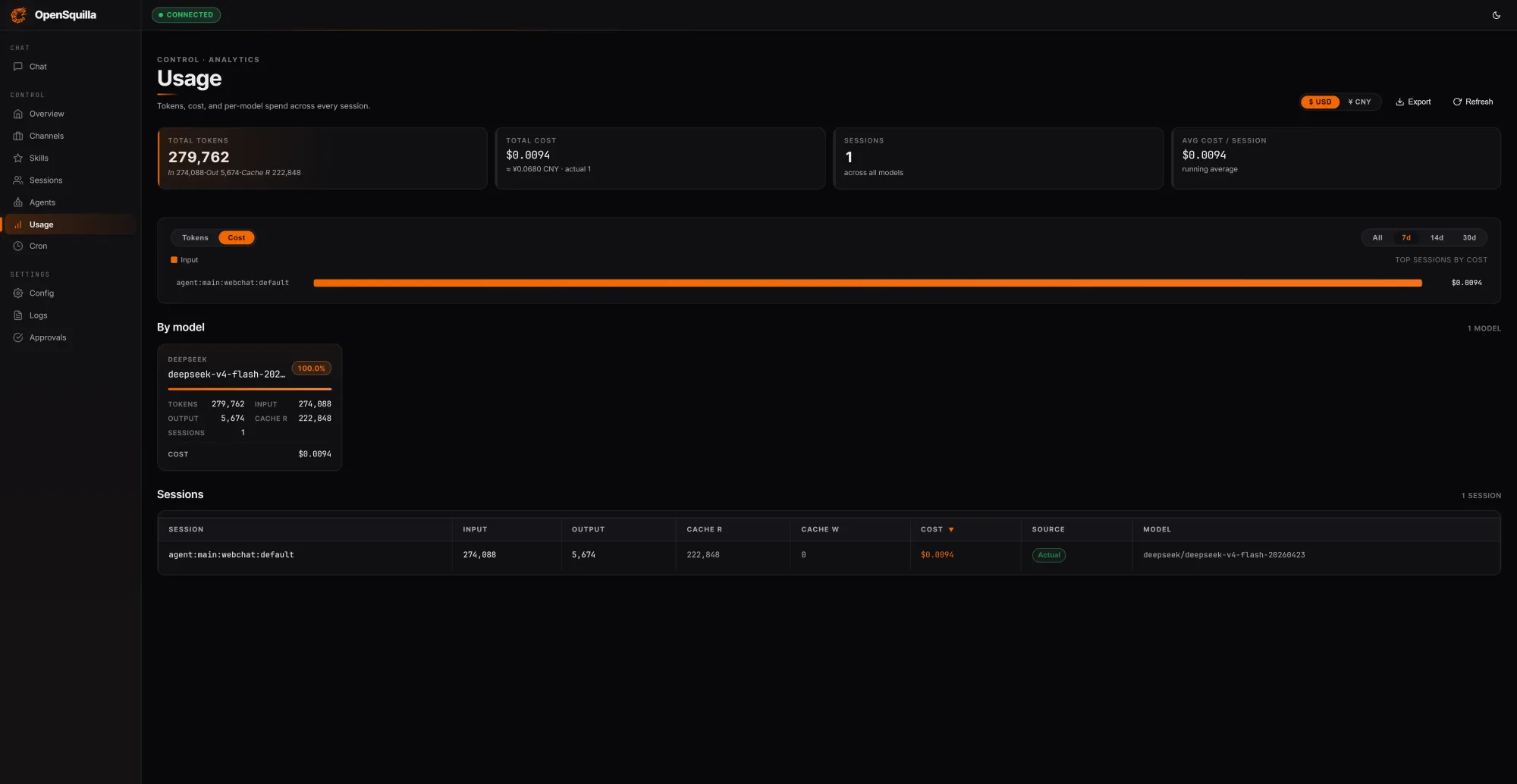
OpenSquilla introduces a self-hostable agent runtime designed explicitly to stop agents from burning tokens they do not need to spend. Instead of sending every request to a single, heavyweight model, it applies model routing optimization using an ML classifier. The classifier blends hand-crafted signals such as message length, presence of code blocks, and keyword patterns with embedding-based semantic features to score complexity. Simple queries route to cheaper models, while deep reasoning is reserved for genuinely complex tasks. In internal tests, three prompts totaling 279,762 tokens cost USD 0.0094 (approx. RM0.04), with 222,848 tokens—about 80% of input—served from cache by reusing context across turns. Skills load on demand rather than bloating every context window, and quota hooks plus per-call cost tracking are built-in so teams can automatically detect and throttle overspend in real time.
Four-Tier Memory Architecture for Efficient Context Management
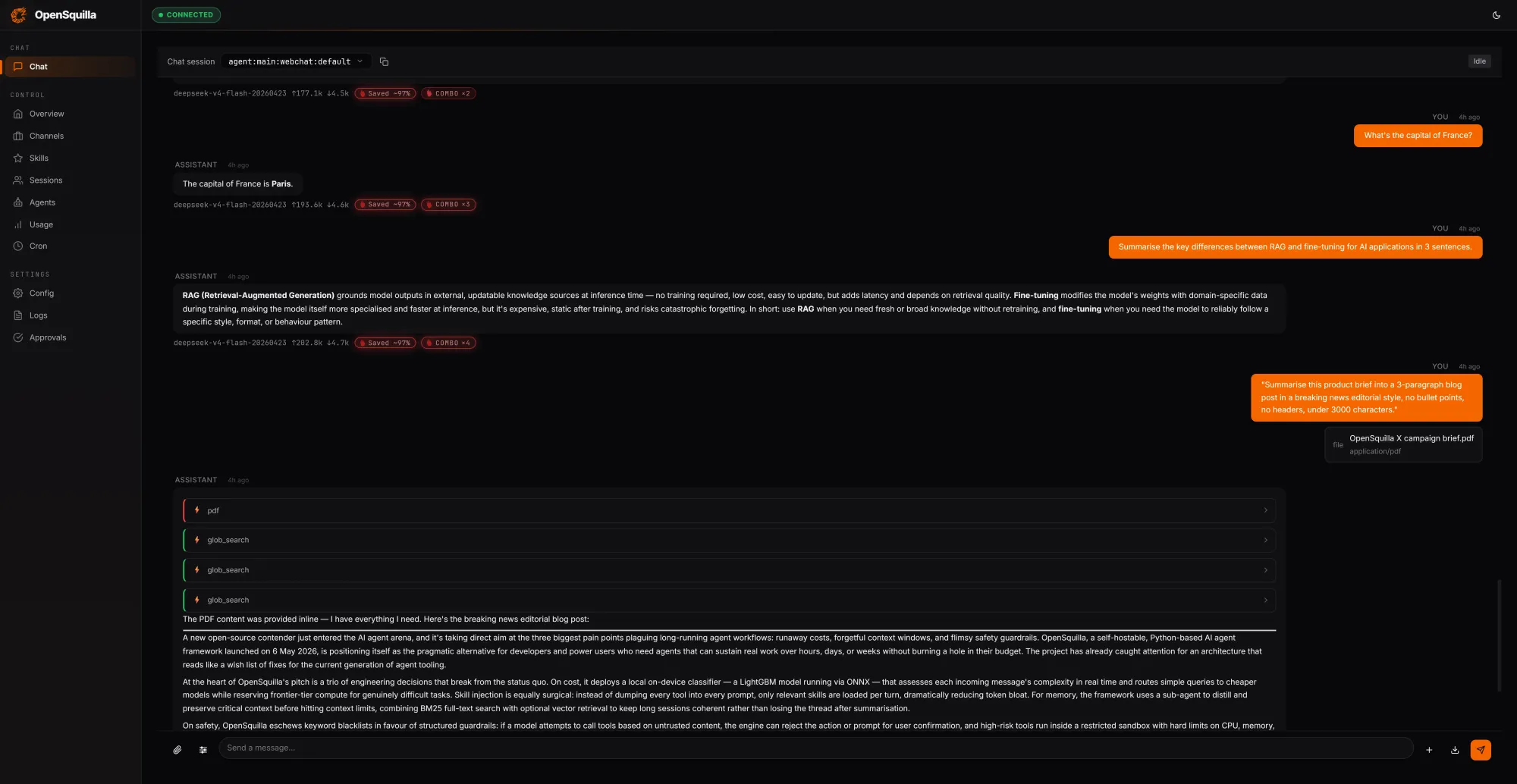
Beyond routing, OpenSquilla tackles context bloat with a four-tier memory architecture modeled on human cognition. Working memory holds the current task, while episodic memory captures experiences and causal relationships across sessions. Semantic memory stores long-lived facts and rules, and raw memory serves as an audit log and retraining base. Retrieval runs vector-semantic search in parallel with BM25 full-text search, with embeddings computed locally via bundled ONNX inference to keep data on-device. Frequently recalled items are promoted into a “hot” memory set, while temporal decay lets stale information fade unless marked as evergreen. Every 24 hours, a consolidation process—dubbed Memory Dream Consolidation—reorganizes scattered memories into denser knowledge structures. This design lets enterprises retain necessary context without repeatedly reloading entire histories, contributing directly to token cost reduction while preserving agent performance on long-horizon tasks.
OpenShell: Syscall-Level Sandbox for Enterprise AI Security
While OpenSquilla optimizes inference, OpenShell focuses on enterprise AI security by rethinking how agents interact with infrastructure. Built as an Apache 2.0 secure runtime, OpenShell gives every agent, along with its harness and model, its own sandbox. A gateway outside each sandbox maintains credentials and session state, handling authentication for external services such as ServiceNow, Salesforce, or Workday. The agent never directly holds keys, and if something goes wrong—prompt injection or an attempt to run arbitrary commands—the blast radius is contained inside the sandbox. Policy enforcement happens below the application layer using Linux kernel primitives like seccomp, eBPF, and Landlock, avoiding the collision of multiple bolt-on security products. OpenShell runs across desktops, Kubernetes, micro-VMs, and cloud infrastructure, and is intentionally model- and framework-agnostic, enabling tools like Claude Code and Codex to operate safely at machine speed.
ServiceNow, LangChain and the Case for Open-Source AI Agents
Early enterprise adoption is signaling that these open-source stacks are ready for production. LangChain, whose frameworks underpin a large share of enterprise agent projects, is contributing directly to the OpenShell GitHub repository, reinforcing its position as a common runtime layer. At ServiceNow’s Knowledge 2026 conference, Nvidia and ServiceNow spotlighted OpenShell as the core security architecture for Project Arc, a long-running autonomous desktop agent for knowledge workers. Project Arc uses OpenShell as its secure runtime, ties into ServiceNow’s Action Fabric for governance and auditability, and connects with ServiceNow AI Control Tower for lifecycle oversight. In parallel, OpenSquilla’s transparent routing, caching, and quota enforcement give enterprises detailed visibility into inference behavior and spend, reducing reliance on opaque proprietary platforms. Together, these projects illustrate how open-source AI agents can deliver vendor independence, cost control, and security without forcing organizations to compromise on capability.