LLM Inference Optimization: From Wasted Compute to Targeted Efficiency
LLM inference optimization is the set of hardware-aware techniques that cut wasted computation, memory use, and latency when large language models generate outputs, so each GPU operation contributes to useful work instead of padding, recomputation, or idle time. As organizations scale up generative applications, the gap between theoretical model performance and real-world throughput has become impossible to ignore. GPUs are powerful, but they are also blunt instruments if fed inefficient workloads. Rectangular tensors ignore the ragged nature of language, while naïve serving stacks keep reprocessing the same long contexts on each user query. The result is high AI inference costs, low GPU memory efficiency, and infrastructure that struggles under business demand. Two emerging ideas now stand out: smarter sequence packing techniques that keep GPUs busy on real tokens, and memory engines that preserve processed context so it never needs to be recomputed.
Padding Overhead: When GPUs Multiply Zeros Instead of Tokens
Standard batching strategies in popular frameworks expose a silent tax on every inference call: padding overhead. When variable-length prompts share a batch, most systems pad every sequence to the longest input, then run attention and matrix multiplies across the full rectangle. In practice, that means the GPU spends a large fraction of its time multiplying zeros with zeros. One engineer described it as “the computational equivalent of paying a chef to cook an empty plate,” and measurements from the WarpGroup-Backend project show how large the penalty can be. By removing padding waste and organizing inputs more carefully, the C++ backend reported up to 2.08× throughput on an H100 and 5.89× on a GTX 1080. For operators chasing LLM inference optimization, padding is no longer a minor annoyance; it is a first-order driver of compute waste and inflated AI inference costs.
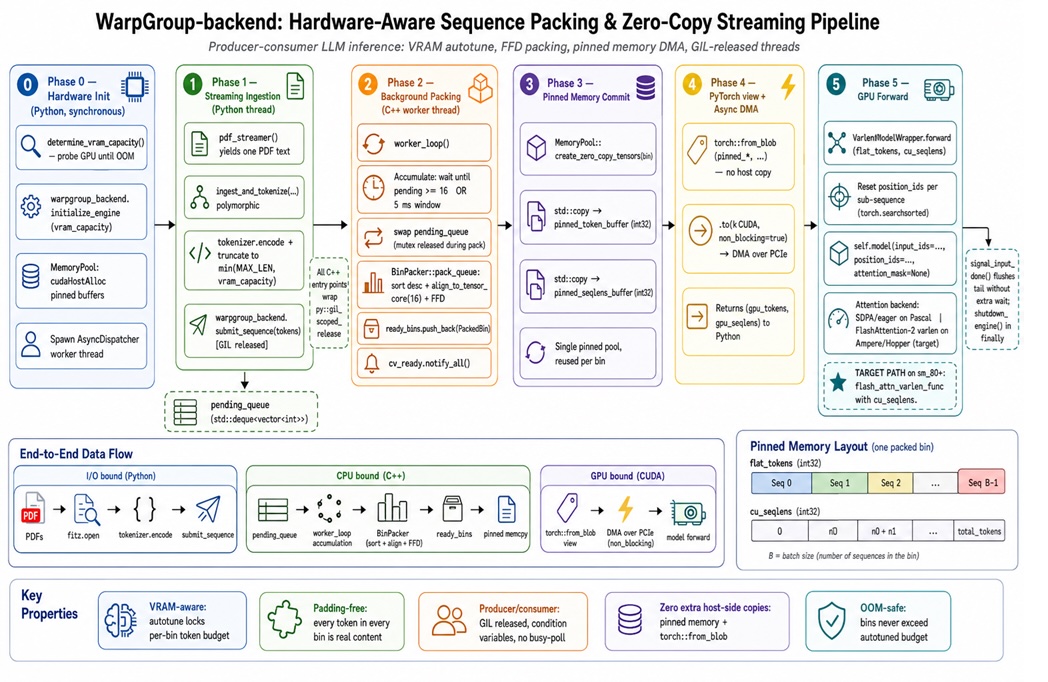
Hardware-Aware Sequence Packing Techniques Boost GPU Utilization
WarpGroup-Backend offers a concrete example of hardware-aware sequence packing techniques that translate directly into better GPU memory efficiency and utilization. Instead of padding each document to the batch maximum, it concatenates variable-length sequences into a single long ribbon and relies on variable-length attention kernels, such as FlashAttention-2’s flash_attn_varlen_func, to keep tokens from different sequences apart. Under the hood, it treats batching as a bin-packing problem: sequences are sorted, rounded to tile-friendly lengths (for example, multiples of 16 tokens), and packed into bins sized by empirical VRAM measurements, not guesses. This bin packing runs in C++ and uses background threads so Python’s GIL does not bottleneck the hot loop. The outcome is fewer out-of-memory failures and GPUs that spend more time on real tokens instead of padding, improving throughput without changing the underlying model.

Memory Engines Attack Redundant Context Recomputation
Padding is not the only source of waste in LLM inference. In many enterprise deployments, the largest recurring cost is redundant recomputation of long contexts. Every time a user asks a new question about the same document, most systems force the model to reread that entire text from scratch, rebuilding the key-value cache on every query. Corbenic AI’s Taliesin memory engine targets this waste directly by saving the processed context and restoring it later, bit-identical to a fresh pass through the model. According to Corbenic AI, Taliesin turned a more-than-two-minute context prefill on a $0.69-per-hour graphics card into a restore time under seven seconds, a 21-times speedup without accuracy loss. Tests shuttling AI memory between an Ampere A6000 and an Ada Lovelace RTX 4090 showed 64 of 64 tokens identical to the originating card, supported by SHA-256 verification.

Efficiency Pressure and the Future of Enterprise AI Economics
The rise of hardware-aware sequence packing and cryptographically verified memory engines signals a shift in how enterprises think about GPU fleets. Early adoption focused on model size and headline capabilities; now, budget pressure forces teams to ask how many useful tokens per second they obtain from each card. Techniques that cut padding, reduce redundant prefill passes, and improve GPU memory efficiency give operators a clear path to lower AI inference costs without retraining or changing models. WarpGroup-Backend shows what careful bin packing and VRAM-aware scheduling can do at the kernel boundary, while Taliesin shows how avoiding repeated context work can accelerate long-context applications up to 21×. Together, these systems hint at a future where serving stacks treat compute as scarce, reuse as much work as possible, and make LLM inference optimization a core design goal rather than an afterthought.





