
Why AI Inference Speed Suddenly Matters
AI inference speed is the rate at which a model turns input into output, often measured in tokens per second, and it now directly shapes which tools feel instant, which workflows scale, and which products users keep returning to in real-world environments. Speed has moved from a niche model performance benchmark to a frontline competitive metric. The gap between the fastest AI models and slower options is no longer academic: when one model streams answers hundreds of tokens per second and another stalls, support agents, coding copilots, and customer chatbots all feel the difference. Faster responses raise completion rates, keep users in the flow, and allow many more parallel conversations per server. As companies scrutinize AI budgets, they compare not only quality and cost, but the speed-per-dollar they get under production loads.
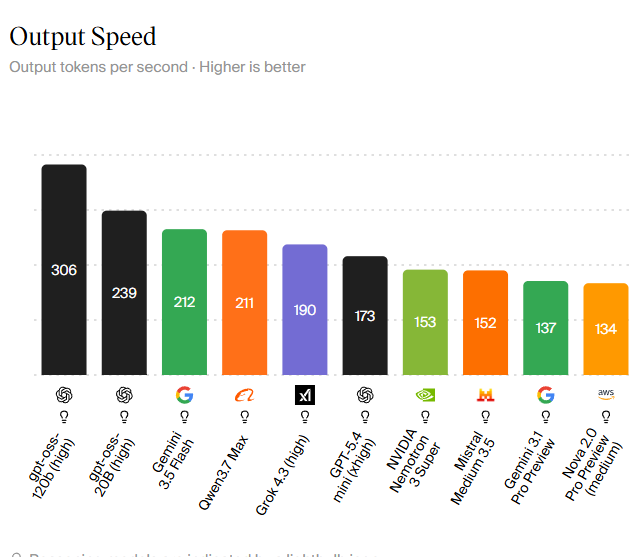
Who Tops the Charts: The Fastest AI Models Today
Recent benchmarks show a sharp spread in AI inference speed across leading models. At the front, GPT-oss 120B on a high-compute tier reaches 306 tokens per second, putting it ahead of the rest of the fastest AI models list. The smaller GPT-oss 20B variant follows at 239 tokens per second, showing how infrastructure scale can push even compact models. Google’s Gemini 3.5 Flash records 212 tokens per second and combines that with strong capabilities for agent-style tasks, while Alibaba’s Qwen3.7 Max is almost identical at 211 tokens per second. Grok 4.3 (high) from xAI hits 190 tokens per second, and GPT-5.4 Mini on an extra-high tier delivers 173 tokens per second, tuned for scaled deployments. These numbers highlight that speed is now a clear model performance benchmark, not a footnote.
Real-World AI Latency and What Developers Choose
Benchmarks tell one story; real-world traffic tells another. OpenRouter, which routes requests across many providers, has become a useful proxy for which fast models developers trust at scale. According to OpenRouter token volume data, DeepSeek leads usage with 3.1 trillion tokens and a 16.3% share, driven by its R1 and V4-Pro models that match strong benchmarks at far lower cost than some premium rivals. Anthropic holds 15.5% of tokens, reflecting steady demand for Claude in high-stakes reasoning, coding, and agentic tasks. Google’s Gemini family takes 13.2%, powered by long-context and multimodal use cases, while OpenAI accounts for 8.7% as developers weigh brand strength against rising competition. Xiaomi’s 8.6% share underlines how device ecosystems can push huge volumes. In practice, developers balance AI inference speed, price, and capability rather than chasing raw tokens-per-second alone.
Use-Case Specific Speed: Fastest Overall vs Fastest for You
The fastest AI models on paper are not always the fastest for your workload. A model that streams 300+ tokens per second on a standard benchmark might slow under long-context prompts or heavy tool-calling, while a slightly slower model could complete shorter, focused tasks faster end-to-end. Gemini 3.5 Flash, for example, combines over 200 tokens per second with strengths in agentic behavior, so it can shorten multi-step flows rather than single responses alone. Meanwhile, mini-class models like GPT-5.4 Mini aim for high throughput at reduced cost, often winning in scenarios with many concurrent, lightweight calls. Developers need to run their own model performance benchmarks against representative prompts: coding sessions, retrieval-augmented chat, or structured data processing all stress models differently. The “fastest” choice is the one that minimizes real-world AI latency for your specific pattern of calls.
Balancing Speed, Capability, and Cost in Production
Speed is only one axis. In many production systems, the sweet spot is speed-to-capability-to-cost. DeepSeek’s V4-Pro shows how this triangle is shifting: on the Artificial Analysis Intelligence Index, it costs USD 1,071 (approx. RM4,600) to run the benchmark compared with USD 4,811 (approx. RM20,700) for Claude Opus 4.7, while still leading open-weights models on agentic scores. For companies processing billions of tokens, that difference compounds. Fast mini models shine for routing, autocomplete, and quick classification, where slight accuracy gaps are acceptable. Premium, slower models still matter when one incorrect answer breaks a workflow, such as complex coding or financial reasoning. The practical strategy is dynamic: route simple calls to cheaper, faster engines, reserve high-end models for difficult prompts, and continuously measure real-world AI latency and output quality instead of assuming one model fits every task.





