
What Claude Opus 4.8’s Effort Selector Does
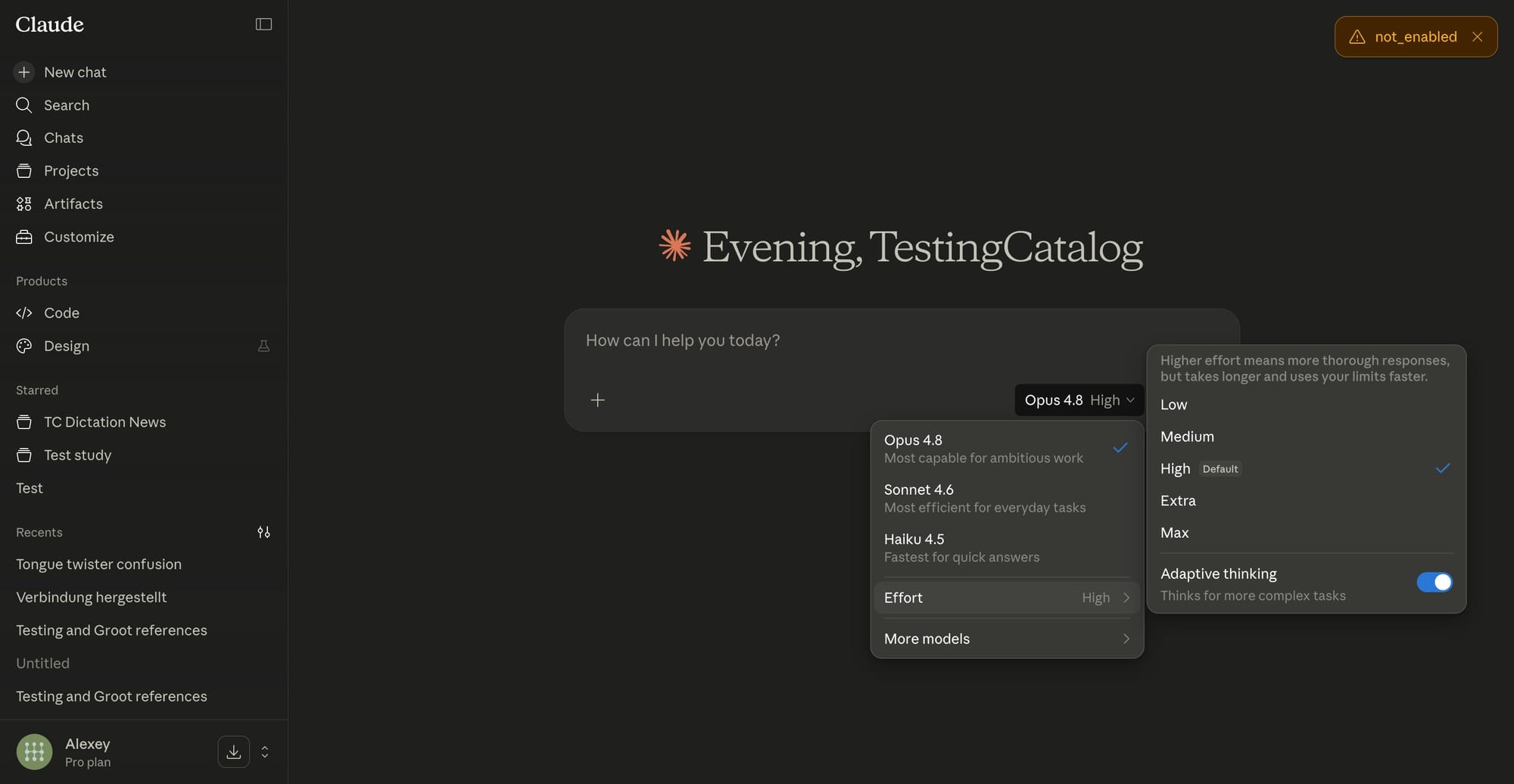
Claude Opus 4.8’s effort selector feature is a control that lets users decide how much computational reasoning the AI applies before responding, trading speed and cost against depth and accuracy in a transparent way. Sitting alongside the model picker on claude.ai, this AI reasoning control exposes five levels: Low, Medium, High (the default), Extra, and Max. Low effort favors fast mode AI responses for short questions, routine email drafts, and straightforward tasks where speed matters more than nuance. At the other end, High and Max ask Claude to think through multi-step problems more carefully, which is better for complex reasoning, detailed analysis, or comparisons. The effort selector does not change the model itself; instead, it hands the decision about how hard the system should think back to users, across all plan types.
Fast Mode: 2.5x Speed at One-Third the Cost
Anthropic pairs effort control with a new fast mode for Claude Opus 4.8 that targets time-sensitive work. Fast mode keeps the same core model but runs at higher throughput, which is particularly useful when Low or Medium effort is selected for smaller tasks. According to Anthropic, “Fast mode now delivers responses at 2.5 times the previous speed at a third of the former cost.” That combination makes it appealing for chatty sessions, bulk drafting, and code experiments where you care more about rapid iteration than maximal accuracy. Power users can toggle fast mode in Claude Code with a simple command, with API access available through Anthropic’s account channels. Together, fast mode and the effort selector give a clearer dial between speed and resource use, so users can tune performance to each query instead of living with one default setting.
Balancing Speed and Accuracy for Different Tasks
The effort selector feature in Claude Opus 4.8 is designed to match different workflows rather than push a single "smartest" mode. Low and Medium effort at fast mode are suited to quick summaries, meeting notes, repetitive customer responses, or simple code snippets where a near-correct answer is adequate and you can manually review results. High, Extra, and Max effort levels shine when accuracy and reasoning depth matter more than latency: multi-step coding tasks, legal-style analysis, long-form reports, or thorny data questions. Higher effort consumes rate limits more quickly because the model spends more time thinking and self-checking before it replies, so the trade-off is explicit. Users who previously toggled between different models to guess at depth now gain AI reasoning control within a single model family, choosing per-question how much care Claude should apply.
Improved Coding, Reasoning, and Self-Checking
Beyond effort control, Claude Opus 4.8 delivers updates aimed at developers and advanced users who care about reliability. Benchmarks show improved coding, reasoning, and agentic capabilities, and Anthropic notes that Opus 4.8 is about four times less likely than its predecessor to let flawed code pass unflagged. The model now carries out more rigorous self-checks, which pairs naturally with higher effort levels: Max effort can mean extra internal verification before a final answer. Early partners have reported better judgment in practical knowledge work and in structured, rule-bound domains such as legal-style tasks. These upgrades are available on both claude.ai and the API, so teams can standardize on a single model while choosing different effort settings for unit tests, production tooling, and exploratory coding sessions. The result is a more predictable line between fast experimentation and careful, review-ready output.
Dynamic Workflows and the Future of Effort Control
For enterprise users, Opus 4.8 adds dynamic workflows in Claude Code, currently in research preview for higher-tier plans. These workflows let Claude plan a large job, spin up hundreds of parallel sub-agents in one session, and verify outputs before returning a consolidated answer. The Messages API now accepts system entries inside the messages array, so developers can change instructions mid-task without breaking caching, which helps with live updates to permissions, token budgets, or environment context. Together with effort control, these agentic abilities show a direction where users specify not only what they want but how carefully and at what scale the AI should work. As Anthropic continues to refine alignment and safety, the effort selector in Claude Opus 4.8 looks like a template for future AI reasoning control, where depth becomes an explicit, adjustable parameter.





