
What Gemma 4 12B Is and Why It Matters
Gemma 4 12B is a 12‑billion‑parameter, encoder‑free, multimodal AI model from Google that runs on consumer laptops, bringing on-device AI models for text, images, and audio into practical everyday use without needing dedicated accelerators or cloud connectivity. Designed as a middle‑tier option in the Gemma 4 family, it fills the gap between lightweight mobile models and heavyweight data center systems. The model’s headline feature is its ability to run local AI inference on machines with 16GB of RAM or VRAM, turning a standard multimodal AI laptop into a capable assistant for coding, document analysis, and media understanding. For users, this means they can run advanced AI workflows locally, with lower latency and more privacy than cloud‑only setups. For developers, Gemma 4 12B opens a path to build lightweight AI models and applications that can be deployed directly on consumer hardware.
Encoder-Free Architecture: Multimodal Without the Overhead
Most multimodal AI models depend on separate vision and audio encoders, which add memory overhead and latency before the core language model ever runs. Gemma 4 4 12B takes a different path: it feeds multimodal data straight into a single decoder‑only transformer, removing those intermediate stages. For images, a slim 35‑million‑parameter embedder slices inputs into 48×48 pixel patches and maps them into the model’s hidden space with a single matrix multiplication plus positional embedding, replacing a 27‑layer vision transformer with around 550 million parameters. For audio, the model slices 16 kHz waveforms into 40‑millisecond frames and projects them directly into the same space as text tokens, skipping a separate encoder entirely. This unified design keeps memory use low, and means the same weights handle text, image, and audio inputs, which simplifies fine‑tuning and adapter‑based customization for local AI inference.

Near 26B Performance on a 16GB Multimodal AI Laptop
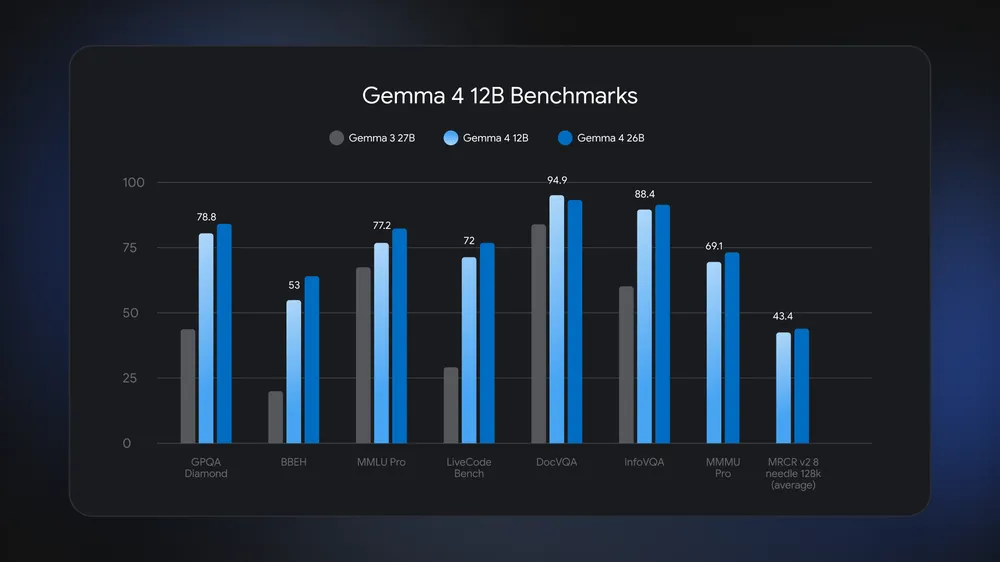
Gemma 4 12B has been engineered to sit close to Google’s larger Gemma 4 26B Mixture of Experts model in benchmarks, while using roughly half the memory footprint. According to Google, the 12B model “runs locally on any laptop with 16GB of system RAM or VRAM” and stays close to the 26B model on tasks such as multistep reasoning and document understanding. It also outperforms the older Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA, despite its smaller size. Multi‑Token Prediction (MTP) drafters are enabled by default, using spare compute cycles to anticipate future tokens and increase generation speed. Together, these design choices turn Gemma 4 12B into one of the most capable lightweight AI models that can be run fully on-device, closing the gap between compact laptop models and heavyweight cloud systems.
Agentic Workflows and Google AI Edge Integration
Beyond benchmarks, Gemma 4 12B is built for agentic workflows, where the model does more than answer prompts and can carry out multi‑step tasks. Google describes it as “designed to bring agentic, multimodal intelligence directly to your laptop,” with support for speech recognition, speaker diarization, code generation, image understanding, and even video analysis. Through Google AI Edge, users can build and experiment locally on everyday machines, using the model to generate and execute scripts, process data, or assemble webpages and tools. One demo shows Gemma 4 12B turning a natural language prompt into Python code that renders a PNG chart of the top 10 girl names across two years. Because the same weights handle all modalities, adapters like LoRA can tune the entire multimodal loop in one pass, making it easier to craft specialized on-device AI models without cloud training pipelines.
From Cloud-Centric AI to Practical On-Device Models
Gemma 4 12B shows a broader shift from cloud‑only AI toward local AI inference that runs on ordinary consumer hardware. Its weights, available under the Apache 2.0 license on platforms such as Hugging Face and Kaggle, come in under 18GB, keeping deployment approachable for developers. The model is already supported by tools like LiteRT‑LM, llama.cpp, and OpenAI‑compatible servers, and appears in Google AI Edge apps for on-device coding and voice dictation. Enthusiasts have praised the encoder‑free approach for making it easier to share and process images and audio without separate files or preprocessing. For end users, this means a multimodal AI laptop can now handle tasks that once demanded cloud GPUs. For developers, Gemma 4 12B provides a concrete template for future lightweight AI models that prioritize efficiency, privacy, and practical on-device AI applications over raw scale.





