What Claude Opus 4.8 Is and Why Its Top Ranking Matters
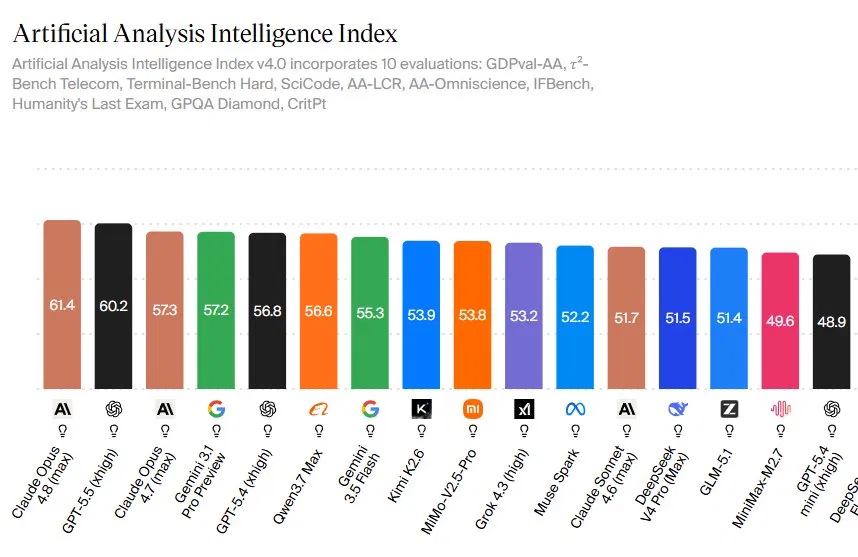
Claude Opus 4.8 is Anthropic’s latest flagship large language model, designed for long, autonomous work and tuned for reliability, which has now ranked as the most capable AI system on several independent benchmarks by combining strong reasoning, coding, and real‑world task performance into a single model. Artificial Analysis reports that Claude Opus 4.8 tops the Artificial Analysis Intelligence Index v4.0 with a score of 61.4, ahead of GPT-5.5’s 60.2 and Claude Opus 4.7’s 57.3. The index pools ten AI model benchmarks, including Humanity’s Last Exam, GPQA Diamond, Terminal-Bench and CritPt, giving a broad picture of capability rather than a single-task snapshot. This narrow lead reflects consistent strength rather than one spectacular domain. For users and enterprises evaluating AI model benchmarks, the message is clear: the new Claude Opus 4.8 stands at the front of the current frontier.
Benchmark Wins: From Coding and Tools to Real-World Tasks
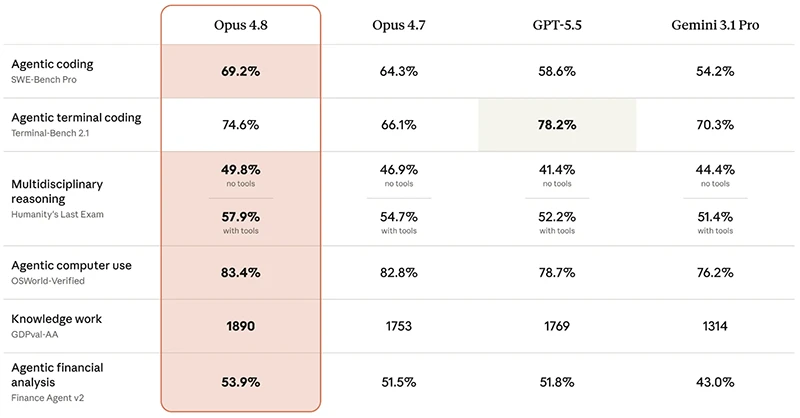
Claude Opus 4.8’s benchmark story is strongest where work looks most like real jobs. On the GDPval-AA benchmark for real-world task execution with web and shell access, it records an Elo of 1890, a 137‑point jump over Opus 4.7 and 121 points ahead of GPT-5.5’s 1769. This implies an approximate 67% win rate in head‑to‑head comparisons against GPT-5.5 at high effort. According to Artificial Analysis, "Opus 4.8’s score of 1890 at its ‘max’ effort setting represents a +137-point improvement over its predecessor, Opus 4.7." Anthropic’s own numbers show a 69.2% score on SWE‑Bench Pro for agentic coding, ahead of GPT-5.5’s 58.6, plus leading scores on Humanity’s Last Exam with tools and OSWorld‑Verified for computer use. The only major area where GPT-5.5 keeps an edge is Terminal‑Bench 2.1, where it scores 78.2 to Opus 4.8’s 74.6.

Efficiency, Reliability, and Real-World Performance Gains
Anthropic’s Anthropic AI release positions Claude Opus 4.8 as not only stronger, but more efficient and reliable than Opus 4.7. On GDPval-AA, it completes tasks with about 15% fewer turns and 35% fewer output tokens than its predecessor, even though it still uses roughly 30% more turns than GPT-5.5 to finish the same workloads. For enterprises, this means higher success rates and fewer retries, balanced against slightly longer or more interaction-heavy sessions. Anthropic reports that Opus 4.8 is about four times less likely than Opus 4.7 to let flaws in its own code pass without comment, and notes lower rates of deceptive behavior and misalignment. Early testers describe it as sharper in judgment on agentic tasks. In practice, this points to more reliable AI agents for codebase-wide changes, structured research, and operational automation that must maintain safety and follow instructions closely.
Positioning Against GPT-5.5 and the Coming Mythos-Class
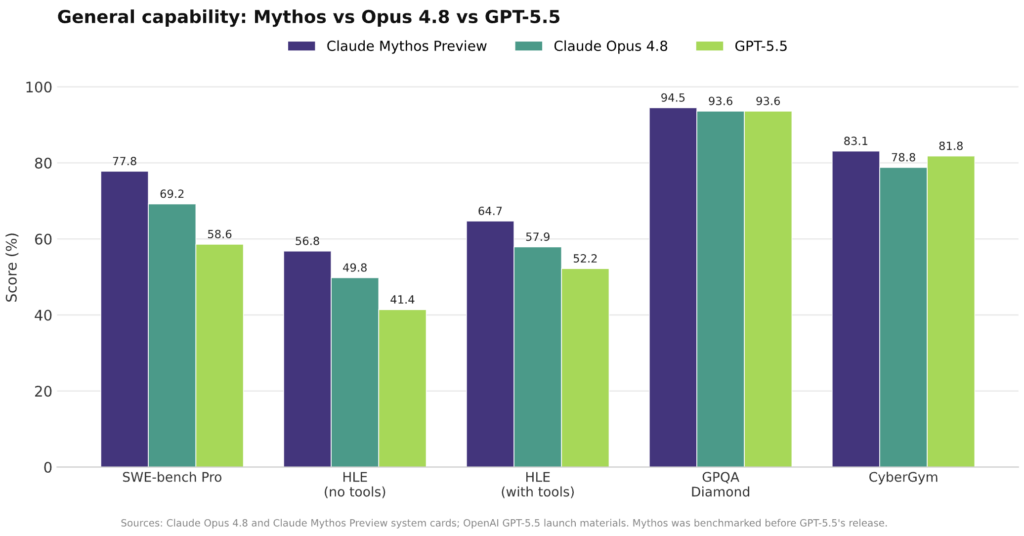
Independent AI model benchmarks now frame Claude Opus 4.8 as the top general-purpose model, yet Anthropic is already signaling what comes next. On Anthropic’s internal AECI index, Opus 4.8 sits between Opus 4.7 and Claude Mythos Preview, suggesting a modest but real general-intelligence gap to the Mythos tier. Mythos pulls further ahead on demanding software work, scoring 77.8 on SWE‑Bench Pro compared with Opus 4.8’s 69.2 and GPT-5.5’s 58.6, while staying roughly tied with Opus 4.8 and GPT-5.5 on GPQA Diamond and USAMO-style reasoning. Anthropic plans to roll out Mythos-class models to all customers, widening access beyond early Project Glasswing participants. Meanwhile, GPT-5.5 remains competitive, especially in terminal-focused tasks and efficiency. For buyers, the GPT-5.5 comparison now hinges less on raw intelligence and more on trade-offs between speed, token use, and the specific workloads each model will handle.
Product Strategy: Fast Mode, Dynamic Workflows, and Enterprise Access
Anthropic’s Claude Opus 4.8 launch is as much a product strategy shift as a model upgrade. The model is available at the same price as Opus 4.7, with a new Fast Mode that runs Opus 4.8 at about 2.5× the speed and at one‑third of the previous cost, controllable via the /fast command in Claude Code. Dynamic Workflows, currently in research preview for Claude Code Enterprise, Team, and Max plans, allows the model to plan large projects, spin up hundreds of parallel subagents, and verify outputs before returning results. Anthropic notes that Opus 4.8 can now handle codebase‑scale migrations across hundreds of thousands of lines of code from kickoff to merge. Alongside this, new controls let users tune how much effort the model spends per task. With Mythos-class models promised for all customers, Anthropic is trying to make frontier‑level capability standard rather than a niche flagship option.





