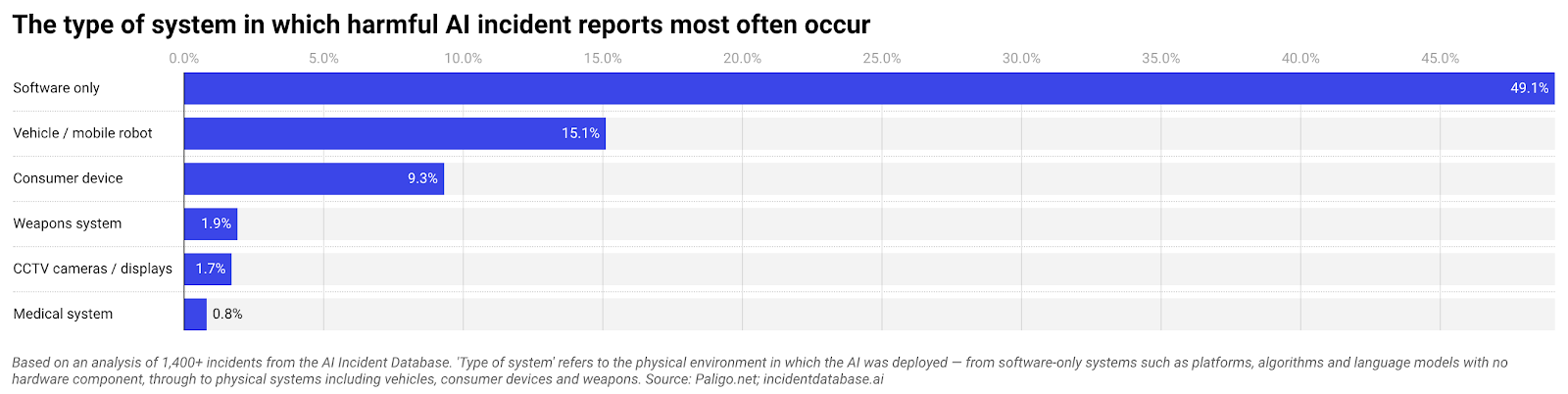
The Data: AI Harm Is Mostly Software, Not Sci‑Fi Robots
Public discussion about artificial intelligence often gravitates toward runaway robots and sci‑fi scenarios. Yet analysis of 1,406 documented AI incidents paints a very different picture. Nearly half of all harmful events—49 percent—stem from software‑only systems such as chatbots, recommendation engines, automated publishing tools and deepfake platforms. That is more than the combined total of every physical AI category in the dataset. In other words, the most common AI harms are mundane and operational, not futuristic. These systems tend to be deeply embedded in everyday processes: customer support, content distribution, decision support in healthcare, and risk scoring. When they misfire, they do so at scale and often invisibly, shaping what people see, believe and receive in terms of services. The evidence suggests the central problem is not cutting‑edge models behaving unpredictably, but ordinary software given powerful roles without adequate control.
Excessive Automation Authority: When AI Speaks Louder Than Policy
The now‑notorious airline chatbot case illustrates how automation authority can outrun organisational judgment. A passenger, trying to navigate bereavement fares after a family loss, relied on a customer service chatbot that delivered detailed but incorrect policy information. The company later argued the bot was a separate legal entity, a position rejected by a tribunal that held the airline responsible. This was not a frontier system; it was a routine support tool granted authority to make definitive statements about refunds and eligibility, with no human review step before those statements affected real customers. Similar patterns show up elsewhere: AI‑assisted drafting that injects fabricated citations into official reports, or deepfake tools used in scams built on borrowed trust and recognisable faces. In each case, the algorithm behaved as designed. The real failure lay in how much weight its outputs carried inside critical workflows.
Automation Oversight Gaps and the Missing Human Review Safeguards
Across the incident database, the same governance mistakes recur. Chatbots are authorised to answer complex policy or legal questions without escalation paths. Recommendation engines are tuned relentlessly for engagement, with little attention to the kinds of content they amplify. Automated publishing systems are allowed to release material that no human has ever read. These choices create automation oversight gaps where AI systems can act autonomously in high‑impact contexts, but no one is explicitly accountable for pre‑deployment checks. Human review safeguards—such as mandatory sign‑off on sensitive outputs, tiered permissions, or automatic routing of edge cases to experts—are often absent or bolted on as an afterthought. By contrast, safer deployments deliberately constrain what AI is allowed to do: chatbots that hand off nuanced queries, recommendation systems with hard limits on specific categories, and workflows where automation drafts but humans approve. These implementations rarely generate headlines precisely because they prevent incidents.
Weak Governance Turns Bias and Platform Scale into Operational Failures
Weak AI governance structures become most visible where bias and scale intersect. Incidents in the database show that when particular groups are disproportionately harmed, race is the most common differentiating factor, appearing in 16 percent of such cases. Examples range from faulty facial recognition leading to wrongful arrests to clinical algorithms that underestimate health risks for certain patients, delaying referrals and treatment. These are not abstract ethical debates; they are operational failures with measurable consequences. Platforms amplify those failures. Social media systems, for instance, appear in 19 percent of incidents involving a specific technology, underscoring how recommendation engines can broadcast harmful content to millions before any intervention. Governance failures here include inadequate testing across demographics, lack of constraints on optimisation targets, and unclear responsibility for content surfaced by automated systems. Without robust structures for monitoring and intervention, bias and virality are allowed to compound into systemic harm.
Building Oversight Frameworks That Make AI Boringly Safe
The pattern emerging from 1,400‑plus incidents is clear: most AI disasters are governance failures wearing a technical mask. Algorithms hallucinate, but they do so in environments where they are fed contradictory or outdated inputs and then trusted without verification. Incident‑prone organisations repeatedly make similar choices—granting AI systems broad authority, optimising for speed or engagement, and omitting human review at precisely the points where judgment matters most. Effective AI incident prevention requires the opposite approach. Governance frameworks should define where automation is allowed to act independently, where it must seek approval, and how its performance is monitored over time. Human review safeguards need to be embedded into workflows, not layered on afterwards. Organisations that treat AI as one component in a tightly governed system—rather than a magical solution—tend to stay out of incident databases. The goal is not more advanced algorithms, but more disciplined oversight.