What LLM inference optimization means in practice
LLM inference optimization is the set of engineering techniques that reduce wasted computation, improve token generation speed, and raise GPU throughput acceleration by aligning model workloads with hardware behavior. Instead of treating every request as a fixed rectangle of tensors, optimized systems handle ragged, variable-length sequences in a way that keeps GPUs busy on useful work, not padded zeros. This matters because padding-heavy batches make GPUs spend billions of operations on tokens that carry no information, inflating latency and costs at scale. By combining smarter batching on the host side, sequence packing techniques in the runtime, and low-level kernel choices like variable-length attention, modern stacks can raise effective tokens-per-second by multiple factors without changing model weights. As LLMs move into production, these gains often translate directly into being able to serve more users on the same hardware.
Killing padding waste with sequence packing
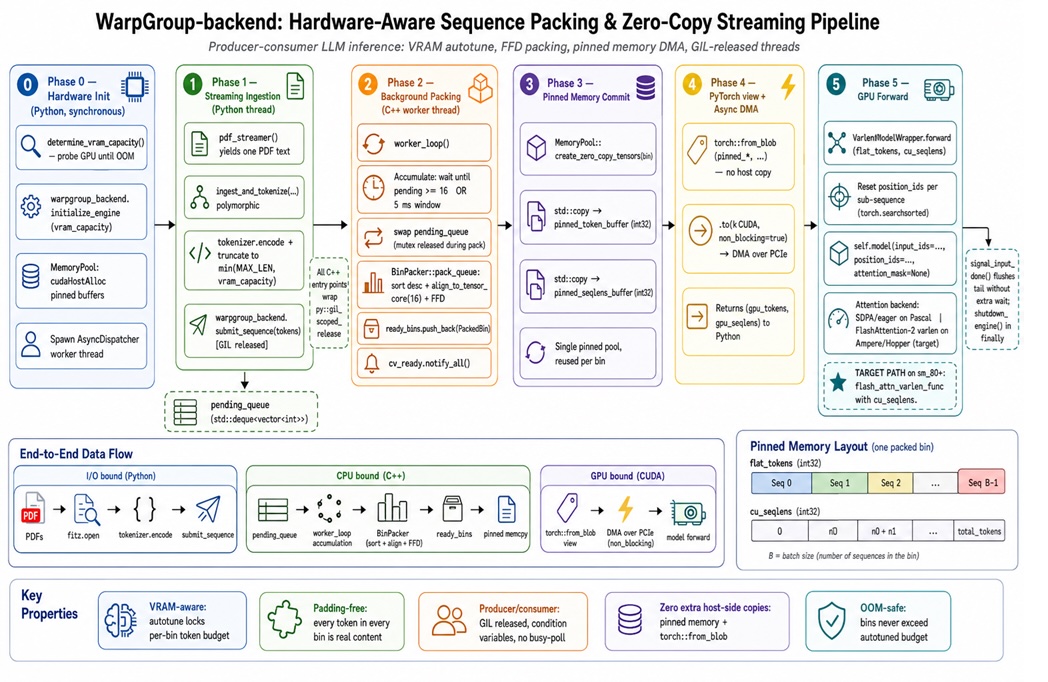
Traditional LLM batching pads every sequence to match the longest in the batch, turning real inputs into rectangles that are easy for GPUs but expensive for wallets. The WarpGroup-Backend article describes how this leads to “your GPU getting paid by the hour to do pretend work” when it multiplies zeros for thousands of padded tokens. A sequence packing technique avoids this by concatenating variable-length sequences into a single ribbon and relying on variable-length attention primitives, such as FlashAttention-2’s flash_attn_varlen_func, to enforce correct token boundaries. The core algorithm resembles First-Fit Decreasing bin packing: sort sequences by length, place each into the first bin with enough room, and open new bins as needed. In tests, this C++ backend delivered up to 2.08× throughput on an H100 and 5.89× on a GTX 1080, while also preventing out-of-memory crashes.
Hardware-aware batching, VRAM limits and real-world GPUs
Sequence packing only works well when it respects the messy limits of real hardware. WarpGroup-Backend treats usable VRAM as a quantity that must be measured, not guessed, probing how many tokens a given model and GPU can hold before out-of-memory and then backing off for safety. It also aligns sequence lengths to multiples of 16 tokens so Tensor Core kernels and attention implementations operate near their best-efficiency shapes. Another key choice is moving bin packing out of Python and into a C++ backend that releases the GIL and runs in background threads. That change keeps tokenization and GPU feeding in parallel, rather than serialized. Combined with pinned-memory transfers and an asynchronous dispatcher, this kind of hardware-aware batching turns a formerly rectangular, padding-heavy workload into a steady stream of dense, compute-efficient ribbons, making LLM inference optimization a practical engineering discipline rather than a theoretical ideal.
Breaking the 1,000 tokens-per-second barrier
On the deployment side, Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode shows how hardware-aware optimization and system co-design can push token generation speed into new territory. According to Xiaomi, the 1-trillion-parameter MiMo-V2.5-Pro in UltraSpeed mode “can run on general-purpose GPUs while breaking the 1,000 tokens-per-second generation barrier.” Earlier, MiMo-V2-Flash reached about 150 tokens per second, already faster than humans can read or speak, but the new mode raises output to roughly ten times the standard MiMo-V2.5-Pro API. These gains come from tight coordination between the model and its runtime, rather than from model architecture alone. They also carry economic trade-offs: Xiaomi prices the MiMo-V2.5-Pro-UltraSpeed API at three times the standard rate and limits access through an application-based trial, reflecting how valuable high-throughput inference resources have become as workloads scale.
Why optimization is becoming non‑optional for LLM deployments
As organizations move from experimentation to always-on LLM services, inference costs grow with every redundant multiply and unoptimized batch. Techniques such as sequence packing, VRAM-aware bin sizing and hardware-aware batching are turning from niche tricks into baseline requirements. Custom C++ backends like WarpGroup-Backend show that being “mildly rude to PyTorch” by bypassing generic batch handling can deliver multi‑fold throughput gains and eliminate instability from out-of-memory errors. At the same time, large players are co-designing models and runtimes, as seen with Xiaomi and TileRT’s MiMo-V2.5-Pro UltraSpeed mode surpassing 1,000 tokens per second on standard GPUs. For teams planning long-lived LLM deployments, LLM inference optimization is now as important as fine-tuning, with direct effects on capacity planning, latency targets and the economic viability of AI products.





