
What the MiniMax M3 Model Is Trying to Solve
MiniMax M3 is a long context AI model designed for coding agents that combines a one-million-token context window with native multimodal AI capabilities to support text, image, and video input in a single developer-facing system. Instead of chasing chatbot-style conversation quality, M3 aims to keep an entire working set of code, documents, and visual references in view while agents edit software, run tools, and repair failed tasks over extended sessions. MiniMax positions this as a direct answer to modern software workflows, where models must read large repositories, maintain state across long automation chains, and recover from errors without losing track of earlier steps. By framing M3 as an agent-first platform rather than a general-purpose assistant, the lab is signaling that its main goal is to sit inside the daily stack of professional developers who need reliable, long-lived coding sessions.
Frontier Coding Agent Model With 1M-Token Context
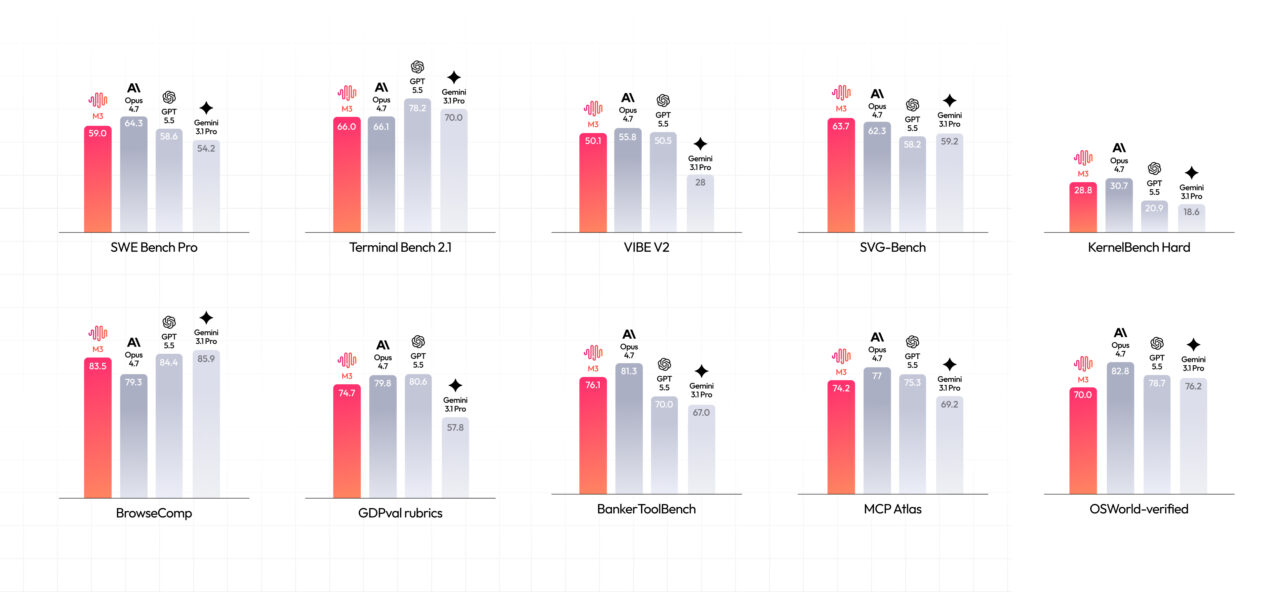
MiniMax released M3 as a frontier coding agent model, not a general chatbot, with a 1M-token headline context and a guaranteed minimum of 512,000 tokens for developers planning long workflows. The model is available through MiniMax Code and OpenAI-compatible endpoints, making it easier to plug into existing tooling. According to MiniMax’s reported results, “M3 scores 59.0% on SWE-Bench Pro, 66.0% on Terminal-Bench 2.1, 34.8% on SWE-fficiency, 28.8% on KernelBench Hard and 74.2% on MCP Atlas.” These numbers suggest competitive performance in agent-style settings, though much of the testing used MiniMax’s own infrastructure and scaffolding such as Claude Code, Mini-SWE-Agent, or Terminus. That dependence on in-house runs means the model still needs independent verification, but it also underlines how tightly M3 is aimed at complex coding agent stacks rather than isolated benchmark questions.
Sparse Attention and the Cost of Long-Context Reasoning
M3’s most significant claim is not only that it offers a 1M-token window, but that it does so with lower latency and inference costs. MiniMax says it uses a Grouped-Query Attention backbone combined with MiniMax Sparse Attention, which reportedly cuts per-token compute at million-token scale to one-twentieth of the prior generation while delivering more than 9 times faster prefilling and more than 15 times faster decoding. In long-context AI models, this prefill phase—where the system reads huge prompts before responding—often becomes the bottleneck for coding agents that must scan large repositories or long histories of tickets and design documents. If these efficiency gains hold up outside MiniMax’s controlled tests, they could make long-context coding workflows more practical, allowing teams to maintain rich, persistent context over multi-stage tasks without paying for extreme latency or overspending on compute for every extended session.
Native Multimodal Capabilities for Developer Workflows
Beyond its text capacity, the MiniMax M3 model brings native multimodal AI capabilities to coding agents by accepting text, image, and video input while producing text output. MiniMax presents this as an all-in-one package for teams that work across source files, screenshots, diagrams, and other visual artifacts during debugging or system design. Instead of switching between separate tools for visual analysis and code generation, developers can feed repositories, UI captures, and architectural sketches into a single long-context AI model. MiniMax Code then wraps these features in an agent framework that can split complex coding tasks into multi-stage workflows, run producer–verifier loops, and use computer-control steps through the same multimodal channel. This multimodal emphasis directly positions M3 against other coding agent models from major labs, where the race is to provide one system that can reason over both code and the surrounding visual context in continuous, long-running sessions.




