From Faster Tokens to Autonomous Coding: The New GPT-5.5 Features
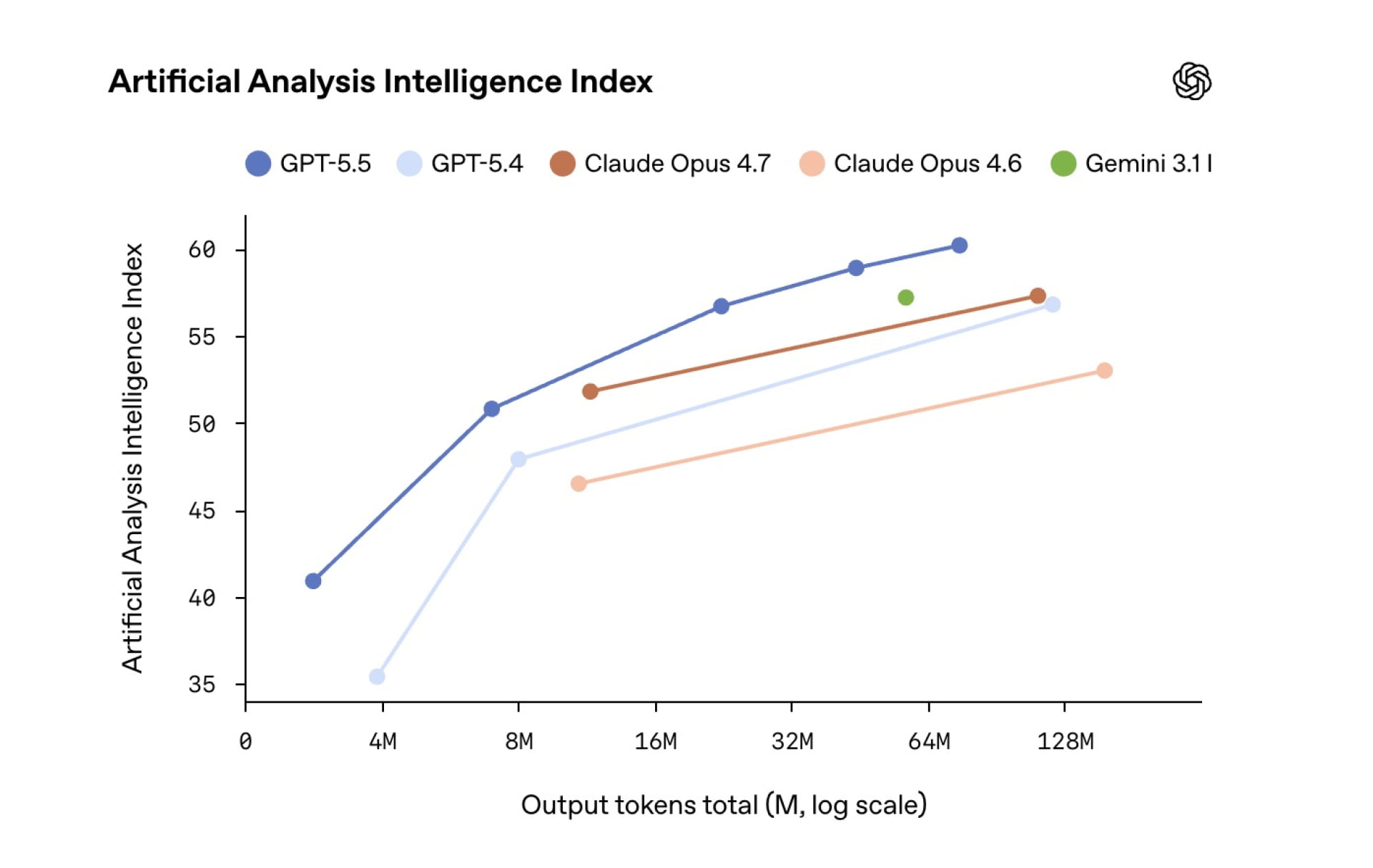
GPT-5.5 is not just another incremental upgrade; it is tuned for agent-like work across code, documents, and research. OpenAI positions it as its most capable autonomous coding AI so far, designed to handle messy, multi-part tasks without constant human steering. In Terminal-Bench 2.0, which measures complex command-line workflows, GPT-5.5 reportedly jumps to 82.7% from 75.1% on the previous generation, and it reaches 58.6% on SWE-Bench Pro, a benchmark built from real GitHub issues that must be fixed end-to-end in one pass. At the same time, OpenAI says the model maintains GPT-5.4’s token latency while consuming fewer tokens on Codex-style programming tasks, so it is both faster in practice and cheaper in token usage. Beyond code, GPT-5.5 strengthens computer-use skills, navigating interfaces, cross-checking its own work, and supporting demanding scientific research workflows.

Why Old Prompts Break on GPT-5.5—and How to Rethink Them
OpenAI is unusually blunt about one thing: treating GPT-5.5 as a drop-in replacement for earlier models will leave performance on the table. Its new GPT-5.5 prompt guide tells developers to discard legacy prompt stacks and start from a minimal, outcome-focused baseline. Older prompts often tried to script every internal step because previous models needed heavy scaffolding. With GPT-5.5, that micromanagement becomes noise. It narrows the model’s search space, encourages formulaic answers, and can even reduce reliability. Instead, OpenAI recommends prompts that clearly define the desired result, success criteria, constraints, and available tools, then let the model decide how to reason. The company also advises testing lower reasoning-effort levels first, because GPT-5.5 reasons more efficiently by default. For teams used to massive, process-heavy instructions, effective GPT-5.5 prompt engineering now means saying less but specifying the outcome more precisely.

Role Definitions Return: The New Core of GPT-5.5 Prompt Engineering
One of the biggest reversals in GPT-5.5 prompt engineering is the renewed importance of role definitions. After a period in which elaborate “you are X” setups were seen as optional or even cargo cult, OpenAI now puts role specification back at the top of its recommended prompt structure. The idea is to keep the role clear and stable—such as “you are a senior backend engineer” or “you are a cautious biomedical research assistant”—while leaving the internal reasoning strategy unscripted. Absolute rules like ALWAYS or NEVER should be reserved for true invariants such as safety policies, legal constraints, or required output fields. For everything else, OpenAI suggests decision rules and explicit stop conditions instead of rigid checklists. This shift matters because GPT-5.5’s stronger autonomous behavior benefits from a well-defined job description and boundaries, not a line-by-line task script.
Bio Bug Bounty and the Safety Stakes of a Stronger Research Model
GPT-5.5’s gains in scientific and biomedical research support come with an equally visible investment in safety. OpenAI has launched the OpenAI Bio Bug Bounty program specifically to probe the model’s biological security system. Selected specialists in AI security, cybersecurity, and biomedicine are invited to test whether GPT-5.5’s safeguards can be bypassed to obtain prohibited biomedical information. Participants must pass screening, answer test questions, and sign a non-disclosure agreement. Those who uncover serious weaknesses can receive rewards of up to USD 25,000 (approx. RM115,000). The program signals both confidence and concern: OpenAI believes GPT-5.5’s bio-safety mechanisms are robust enough to open to targeted red-teaming, yet it is willing to pay to discover failure modes before malicious actors do. For developers in health, pharma, or biotech, this is a reminder that safety and compliance constraints are not optional extras but central design inputs.

From Agents to Workflows: Practical Guidance and New Benchmarks for GPT-5.5
For developers and startups, adopting GPT-5.5 means rethinking both prompts and evaluation. On the workflow side, it is built for long-running, ambiguous tasks—like refactoring large codebases or reviewing tens of thousands of tax forms—where it can navigate tools, verify outputs, and maintain context over many steps. Practically, teams should: start with short, outcome-driven prompts; add only the constraints and fields that truly matter; and let the model orchestrate tool calls, using higher reasoning-effort settings only when needed. On evaluation, classic benchmarks like MMLU are no longer enough. Agentic reasoning benchmarks such as SWE-Bench variants, GAIA, and realistic web-navigation suites like WebArena have emerged as better proxies for real-world autonomy, although their results depend heavily on scaffolding and tool setup. As GPT-5.5 behaves more like an autonomous agent than a chat bot, success will be measured less by static scores and more by how reliably it closes loops in production workflows.