Why Inference Speed Now Matters as Much as Model Quality
The fastest AI models are high-speed language models tuned so that tokens per second stay low-latency even under heavy workloads, turning once-theoretical inference speed benchmarks into practical constraints that define which tools feel instant and which feel slow in real-world use. For years, discussions focused on accuracy and parameter counts; now speed has become a serious competitive differentiator in AI model selection. Data from rankings such as the Artificial Analysis index shows leading models in the 150–300 tokens-per-second range, with OpenAI’s GPT-oss variants, Google Gemini Flash, and NVIDIA Nemotron among the standout performers. The gap between top and bottom is not cosmetic: those differences decide whether an AI agent can keep up with live conversations, stream long documents in real time, or block a user’s workflow. As teams scale production deployments, speed-per-dollar and end-to-end responsiveness are becoming board-level concerns.
Xiaomi MiMo-V2.5-Pro UltraSpeed: Breaking 1,000 Tokens per Second
Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode pushes the idea of fastest AI models into new territory. Co-designed with TileRT, the 1-trillion-parameter model runs on general-purpose GPUs and crosses the 1,000 tokens-per-second threshold, an order-of-magnitude jump over many existing leaders. Xiaomi notes that an earlier sibling, MiMo-V2-Flash, already hit about 150 tokens per second when it launched, itself faster than human reading or speaking speed. UltraSpeed raises that ceiling further, with Xiaomi describing it as delivering “roughly 10 times faster output than standard MiMo-V2.5-Pro API access.” The tradeoff is cost and scarcity: UltraSpeed is priced at three times the standard MiMo-V2.5-Pro API and is currently offered only through an application-based trial with capped sessions and queue entries. This design makes UltraSpeed ideal for latency-critical bursts—such as live coding copilots, instant document rewrites, or trading tools—rather than always-on low-priority workloads.
MiniMax M3: Sparse Attention for High-Speed Long-Context Workloads
MiniMax M3 approaches fast inference from a different angle: keeping long-context, multimodal workloads responsive. With 428 billion parameters and support for context windows up to one million tokens, it targets extended coding, video analysis, and design pipelines that used to be too slow or expensive to keep online. MiniMax Sparse Attention cuts the computational load, leading to substantially faster prefill and decoding than the previous generation while still handling text, images, and video natively. Running on NVIDIA’s accelerated stack—using engines such as TensorRT LLM, SGLang, and vLLM, plus BF16 and MXFP8 precision formats—M3 is tuned for high throughput on Blackwell-class GPUs and supports up to 128 experts per token. Early users highlight efficiency gains and stable performance on large, continuous workloads, making M3 attractive for 24/7 agents, long-context retrieval systems, and multimedia analytics where steady speed matters more than ultra-short bursts.
Benchmarks in Context: From Leaderboards to Real Applications
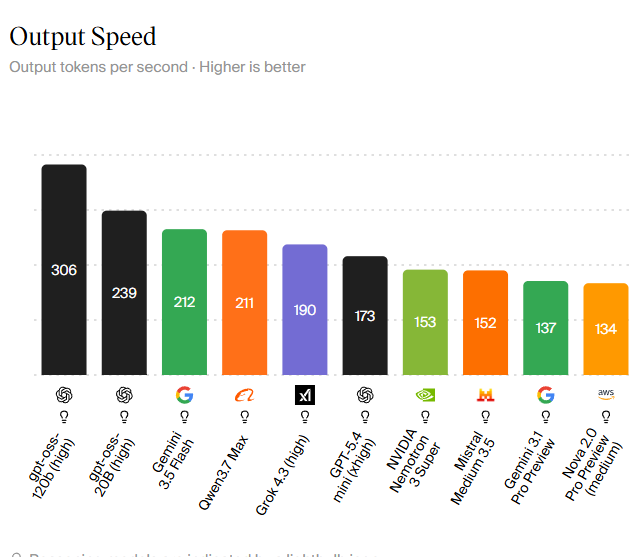
Traditional inference speed benchmarks list models like GPT-oss 120B High at 306 tokens per second, GPT-oss 20B High at 239, Google Gemini 3.5 Flash at 212, Alibaba Qwen3.7 Max at 211, and NVIDIA Nemotron 3 Super at 153. These numbers help rank the fastest AI models, but raw tokens per second only tell part of the story. Xiaomi MiMo-V2.5-Pro UltraSpeed shows what happens when that figure jumps beyond 1,000 on standard GPUs: workloads such as streaming summarization and real-time translation move from “fast enough” to effectively instantaneous. MiniMax M3, in contrast, optimizes prefill and decoding speed while keeping a million-token context feasible, which matters more for batch-heavy or agentic workflows. For practitioners, the practical question is no longer “Which model is fastest?” but “Which speed profile—burst or sustained—matches this product’s interaction pattern and context length?”
Where High-Speed Language Models Deliver Competitive Advantage
High-speed language models change what teams can build. In customer support, ultra-fast responses keep chat queues short and make AI feel like a human agent, especially when multiple threads run in parallel. In development tools, copilots backed by models like MiMo-V2.5-Pro UltraSpeed give near-instant code completions and refactors, increasing iteration speed. For analytics, MiniMax M3’s sparse attention and large context make it realistic to keep continuous agents reading logs, documents, or video streams without timing out. Cost-effective inference also shifts strategy: faster models can finish tasks quickly, reduce GPU time, and enable more aggressive use of streaming UIs. The emerging best practice is to mix models—using a burst-speed specialist for interactive front-ends and a long-context expert for background reasoning—while tracking tokens per second as a first-class product metric alongside accuracy and safety.





