What Claude Opus 4.8 Is and Why Its Benchmarks Matter
Claude Opus 4.8 is Anthropic’s latest flagship large language model, positioned as an incremental but meaningful upgrade that improves coding, reasoning, and agentic task performance while keeping the same pricing tier as its predecessor for enterprise and developer use. Artificial Analysis reports that Opus 4.8 scores 61.4 on the Artificial Analysis Intelligence Index, narrowly ahead of GPT-5.5 (xhigh) at 60.2, signaling that top-tier systems now sit within a very tight band of large language model performance. Anthropic’s own system card places Opus 4.8 between Opus 4.7 and the higher-end Mythos Preview on its internal AECI index, again highlighting small numerical gaps rather than a clear generational leap. For enterprise AI evaluation, the question is shifting from which model leads a benchmark table to when those marginal gains become visible in production: fewer escalations to humans, shorter task completion times, or higher accuracy on regulated workflows.
Inside the Claude Opus 4.8 Benchmarks and AI Model Comparison
On Anthropic’s reported benchmarks, Claude Opus 4.8 consistently improves on Opus 4.7 and often edges out GPT-5.5 and Gemini 3.1 Pro, suggesting steady refinement rather than a dramatic jump. Opus 4.8 scores 69.2% on SWE-bench Pro, up from 64.3% for Opus 4.7 and ahead of GPT-5.5 at 58.6 and Gemini 3.1 Pro at 54.2, indicating stronger agentic coding in large codebases. On Humanity’s Last Exam, it reaches 49.8% without tools and 57.9% with tools, leading the compared models on multidisciplinary reasoning. Agentic computer use in OSWorld-Verified rises slightly to 83.4%, ahead of GPT-5.5’s 78.7%. Knowledge work (GDPval-AA) is another bright spot, with Opus 4.8 at 1890 versus 1769 for GPT-5.5 and 1753 for Opus 4.7. The main exception is Terminal-Bench 2.1, where GPT-5.5 posts 78.2% against Opus 4.8’s 74.6%, though Opus 4.8 still improves substantially over Opus 4.7’s 66.1%.

Incremental Gains: Opus 4.8 vs Opus 4.7 and Mythos
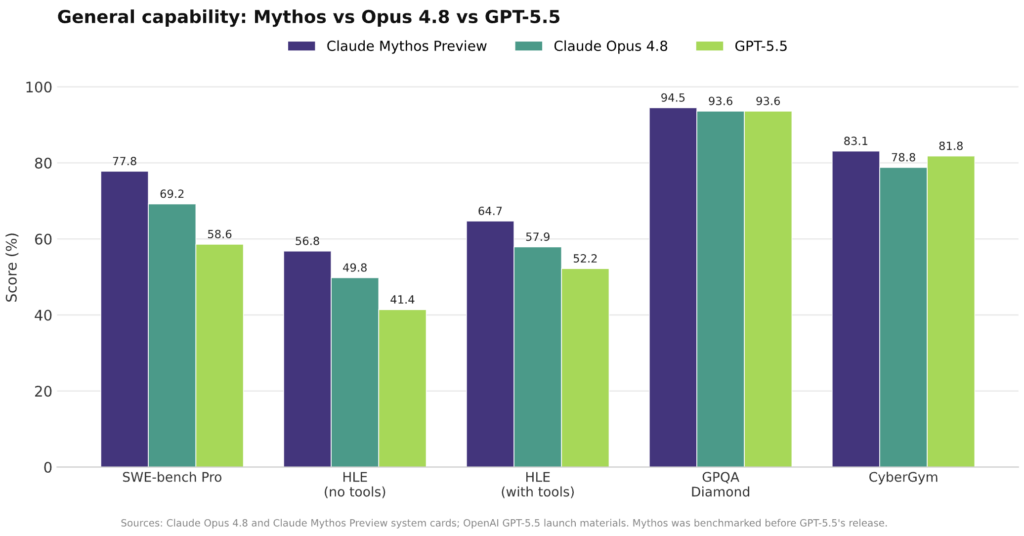
Anthropic describes Opus 4.8 as a step up from Opus 4.7, and its internal AECI index backs that up with scores of 155.5 for Opus 4.8 and 154.1 for Opus 4.7, while Mythos Preview sits higher at 158.3. The benchmark story is uneven: Mythos leads on the hardest software tasks, including 77.8 on SWE-bench Pro versus Opus 4.8’s 69.2, and 59.0 on SWE-bench Multimodal against 38.4 for Opus 4.8. For pure reasoning, the gap narrows: GPQA Diamond is effectively a tie at around 94 for both models, and they sit within a point of each other on USAMO-style proof problems. According to Anthropic’s system cards, “the general-intelligence gap over Opus 4.8 is modest and uneven, while the cyber gap is vast,” which supports the view that Opus 4.8 is a tuned workhorse for broad enterprise use, while Mythos targets specialized, higher-risk domains.
From Benchmark Wins to Enterprise AI Evaluation
With Opus 4.8 topping the Artificial Analysis Intelligence Index by just over one point and trading benchmark leads with GPT-5.5 and Mythos on specific tasks, enterprise buyers face diminishing returns from headline scores alone. Anthropic is positioning Opus 4.8 for agentic workloads: long-running coding sessions in Claude Code, repository-wide bug sweeps, and multi-step engineering tasks that need fewer human check-ins. Fast Mode adds another dimension by running the same model at around 2.5x speed and at one-third the previous cost, which can change the economics of large-scale experimentation. For businesses, the practical questions are now: does a 5–10 point gain on SWE-bench Pro reduce developer review time; does stronger OSWorld-Verified performance translate into more reliable autonomous computer use; and does the same price as Opus 4.7 make an upgrade a low-risk default for most existing Opus workloads?
Where Benchmark Margins Hide Real-World Capability Gaps
Opus 4.8’s marginal lead on the Artificial Analysis Intelligence Index and Anthropic’s internal AECI scores show an AI model comparison landscape where top systems are tightly clustered, yet capability gaps still matter in specific domains. Cyber security is a clear example: Anthropic reports that Mythos drastically outperforms Opus 4.8 on exploit generation, while external work like Berkeley RDI’s ExploitGym and the UK AI Security Institute’s tests show Mythos and GPT-5.5 trading narrow leads across different slices of expert tasks. For most enterprises, that means Opus 4.8 offers strong, general-purpose performance for coding, reasoning, and knowledge work, while more specialized models such as Mythos or GPT-5.5 might be reserved for high-stakes security or infrastructure projects. As benchmark differences compress, successful enterprise AI evaluation will depend less on who tops a chart and more on controlled pilots that measure error rates, escalation patterns, and integration effort in live systems.






