
What Claude Fable 5 Is and Why It Matters
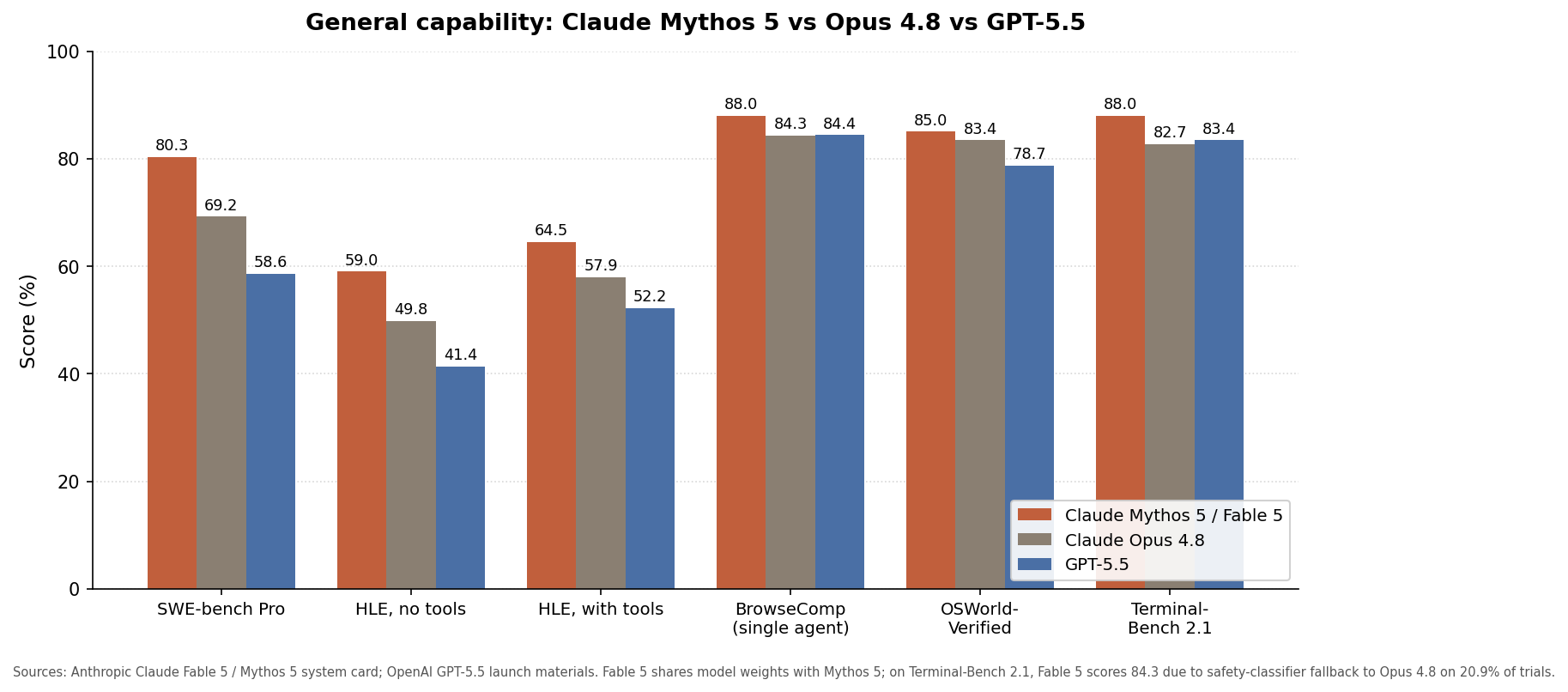
Claude Fable 5 is Anthropic’s first publicly accessible Mythos-class model, designed to deliver stronger coding performance, deeper analytical reasoning, and longer autonomous workflows than earlier Claude models while enforcing strict safety controls for everyday users. Built on the same core weights as Mythos 5, Fable 5 is wrapped in classifiers that detect high‑risk topics and automatically route sensitive cybersecurity and biology questions to the older Claude Opus 4.8 model instead. This design exposes most of Mythos‑level intelligence without giving unrestricted access to its most sensitive capabilities. Benchmarks underline the step up: Fable 5 reaches 80.3% on SWE‑Bench Pro compared with Opus 4.8’s 69.2%, and is the first Claude model to pass 90% on a long‑running analytical benchmark from Hex. For teams evaluating AI coding benchmarks or planning long‑horizon knowledge work, Fable 5 changes the baseline for what a general‑access model can handle.

Coding Power: Claude Fable 5 vs Opus 4.8 vs GPT‑4
On coding‑heavy tasks, Claude Fable 5 performance stands out most clearly. In direct comparisons, Fable 5 not only scores 80.3% on SWE‑Bench Pro versus Opus 4.8’s 69.2%, it also tends to produce more polished, self‑directed outputs. In a simple browser ping‑pong game test, both models produced working HTML, but Fable 5 added a dark navy field, clear score display, and deliberate color choices without being asked, hinting at stronger product sense and layout judgment. Anthropic reports that Stripe used Fable 5 to run a migration across a 50‑million‑line Ruby codebase in a single day, compressing what they estimated as over two months of human engineering. Compared with GPT‑4‑class models, early cross‑model comparisons position Fable 5 as especially strong on difficult, production‑grade codebases and long, dependent coding sequences, while GPT‑4 remains competitive on smaller, one‑shot coding prompts and general scripting work.
Long‑Form Analysis and Mythos‑Class Reasoning
Beyond pure coding, Fable 5 is tuned for sustained analytical work that previously required close human steering. Anthropic describes an “adaptive thinking” mode enabled by default, allowing the model to maintain consistent reasoning across multi‑step chains and multi‑day document workflows. External evaluations echo this: on Artificial Analysis’s Intelligence Index, Fable 5 scores 65, ahead of both GPT‑5.5 at 60 and Gemini 3.1 Pro Preview at 57, signaling a broad reasoning advantage on complex benchmarks. In physics research tests, Physical Superintelligence reported that the underlying Mythos‑class system delivered leading results while using roughly a third of the reasoning tokens compared with prior models. For enterprises, this translates into fewer restarts and less prompt micromanagement when running deep research reviews, complex data analyses, or multi‑phase planning. GPT‑4 remains a strong generalist, but for long‑context analytical tasks, the Mythos‑class model comparison increasingly tilts toward Fable 5.
Security Fallbacks, Costs, and Practical Tradeoffs
Fable 5’s power is constrained by explicit safety design. Any request that strongly touches cybersecurity or biology is routed to Opus 4.8, preserving Anthropic’s stricter Mythos access rules. That means a developer can rely on Fable 5 for large‑scale refactors, but attempts to probe exploit techniques or sensitive bio‑design will quietly fall back to Opus, with its lower raw capability in those domains. This dual‑model behavior has cost implications. According to Anthropic, “both Fable 5 and Mythos 5 are priced at USD 10 (approx. RM46) per million input tokens and USD 50 (approx. RM230) per million output, exactly double the standard Opus 4.8 rate.” Real session logs show the impact: in the ping‑pong game test, Fable 5 consumed 109,035 session credits versus Opus’s 81,225 for similar token counts. For buyers, the tradeoff is clear: higher performance per task, but fewer messages and higher spend per experiment.

When to Use Fable 5, Opus 4.8, or GPT‑4
From a practical standpoint, Fable 5 delivers the biggest gains on work that demands sustained effort: large codebase changes, full web or app builds from screenshots, multi‑document analyses, and extended design iterations. Opus 4.8 remains attractive when cost, message volume, or highly interactive back‑and‑forth chats matter more than peak performance, and it is still the model handling security‑sensitive queries behind Fable’s safety net. GPT‑4 continues to be a strong all‑purpose option with wide ecosystem support, especially for quick utilities, lightweight scripts, and integrations where ultra‑long reasoning chains are less important. For teams choosing among these systems, the Mythos‑class model comparison suggests a simple rule of thumb: reach for Claude Fable 5 when you want an AI that can stay engaged with complex coding and analysis over time, fall back to Opus 4.8 when budgets are tight, and keep GPT‑4 in the mix for broad compatibility and general tooling.





