From Code Snippets to Full Codebases: Why Refactoring Now Matters
AI code refactoring is moving from theoretical promise to measurable practice as engineering teams lean on coding agents for more than greenfield features. The hard work in many organizations lies in legacy code modernization—untangling monolithic modules, replacing brittle interfaces, and cleaning up years of drifted patterns. Traditional benchmarks have mostly tested models on isolated programming puzzles or short functions, which say little about how an agent behaves inside a sprawling repository. For developers buried in accumulated technical debt, the real question is whether AI can restructure an existing system without breaking what already works. This is precisely the gap that new codebase restructuring benchmarks seek to close: can an agent understand architecture, update multiple files coherently, and preserve behavior? As AI moves deeper into maintenance tasks, its value will increasingly be judged not by how cleverly it writes new code, but by how safely it reshapes old code.
Inside Scale Labs’ Refactoring Leaderboard and SWE Atlas
Scale Labs’ Refactoring Leaderboard extends its SWE Atlas research suite by targeting one of the hardest engineering problems: changing structure without changing behavior. Instead of scoring models on small, isolated tasks, the benchmark drops AI agents into production-style repositories and asks them to refactor while keeping tests green. Compared to SWE-Bench Pro, these Refactoring tasks involve roughly twice as many lines of code changes and 1.7 times more file edits, turning them into a higher-pressure measure of multi-file software engineering work. The benchmark covers four core scenarios central to legacy code modernization: decomposing monolithic implementations, replacing weak interfaces with cleaner abstractions, extracting duplicated logic into shared modules, and relocating code to improve module boundaries. Each run is evaluated both by automated tests and rubric-based reviews that examine maintainability, artifact cleanup, and documentation quality, making this a holistic coding agents benchmark rather than a narrow correctness check.
How Leading AI Coding Agents Perform on Refactoring Tasks
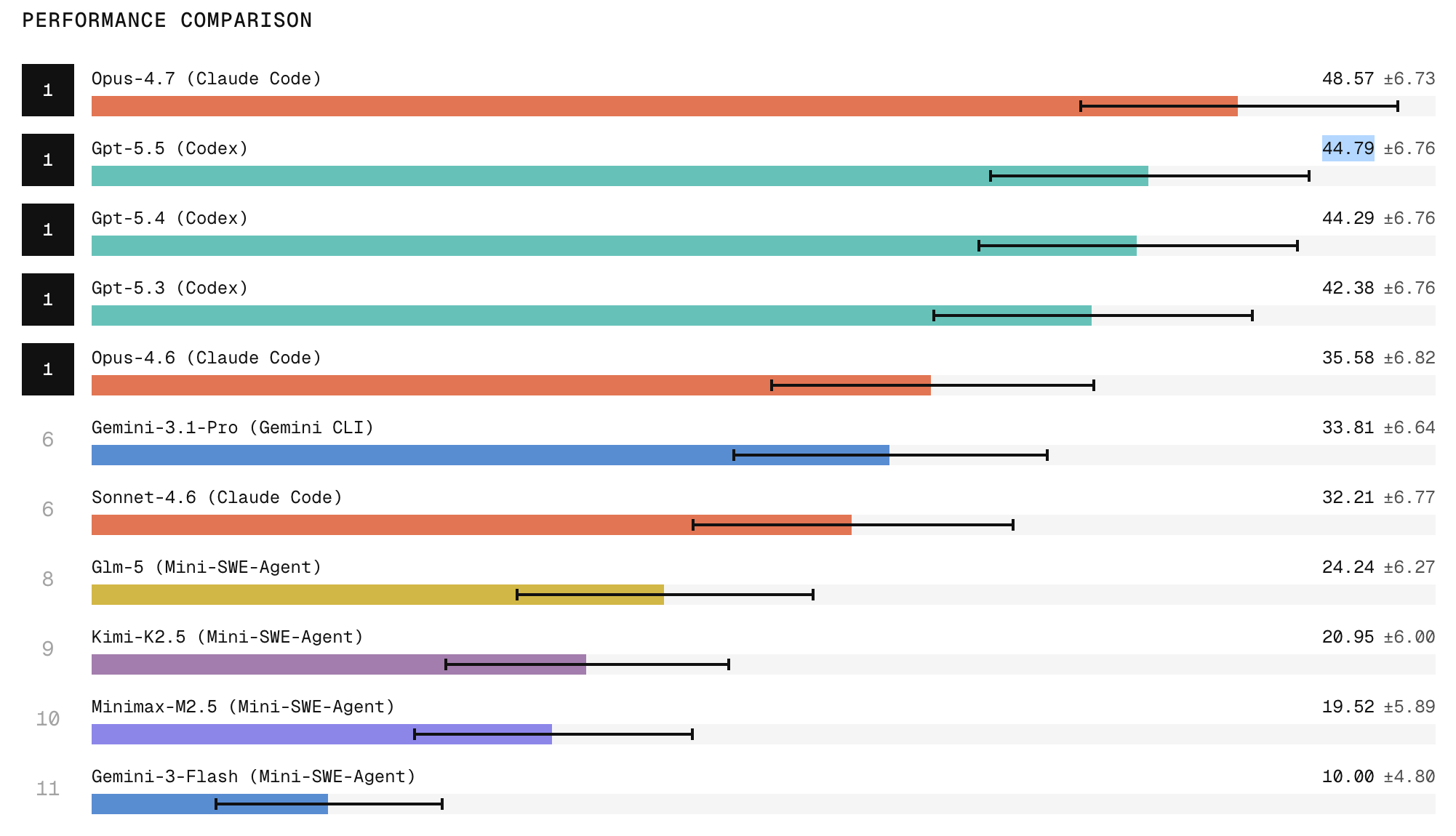
Early results from the Refactoring Leaderboard highlight important differences between AI agents’ abilities on complex refactoring and on simpler code generation. Claude Code with Opus 4.7 currently takes the top spot, with research indicating it produces the strongest refactors among tested systems, while ChatGPT 5.5 follows closely behind. A pronounced gap emerges between frontier closed models and open-weight models, especially on tasks that demand broad repository exploration, structural edits, and strict behavior preservation. Yet even high-scoring agents reveal a recurring weakness: cleanup. Models often leave behind dead code, stale imports, duplicated implementations, outdated comments, or missed call sites. This means that passing tests does not guarantee production-grade quality. For teams evaluating AI code refactoring tools, these findings suggest that leaderboard rank should be weighed alongside how well an agent finishes the job—removing artifacts and aligning the codebase with long-term maintainability standards.
Reliability and Repeatability: The Trust Gap in AI-Assisted Maintenance
Beyond headline scores, the Refactoring Leaderboard underscores reliability as the central hurdle for AI coding agents. Scale Labs reports that when models attempt the same refactoring task three times, they are two to three times more likely to succeed once than to succeed in all three attempts. This spread reveals a trust gap: an agent can look capable in a single run while remaining too inconsistent for unattended production workflows. For developers relying on AI for codebase restructuring, it means human oversight is still essential—particularly for high-risk changes in core modules or critical paths. Scale Labs positions SWE Atlas as a way to treat agents like software engineers rather than autocomplete tools: they must inspect codebases, infer design constraints, and avoid regressions repeatedly, not just once. Until consistency, artifact removal, and deeper code understanding improve, AI will function best as a supervised collaborator, not an autonomous maintainer.
What This Means for Teams Managing Legacy Systems
For engineering leaders wrestling with legacy code modernization, the Refactoring Leaderboard offers both encouragement and caution. On the positive side, top-tier agents already demonstrate the ability to decompose monoliths, introduce cleaner abstractions, and centralize duplicated logic—tasks that typically absorb significant developer time. Used thoughtfully, these tools can accelerate backlog reduction and free human engineers to focus on architecture and product-level decisions. However, the benchmark’s findings on cleanup and repeatability signal that AI-assisted refactors still require careful code review, test expansion, and incremental rollout strategies. Teams may benefit from integrating agents into existing workflows as pair-programmers for refactors, rather than handing them entire subsystems. Over time, as coding agents benchmark scores rise and reliability stabilizes, developers can gradually delegate more of the routine restructuring work. Until then, success will hinge on pairing AI’s speed with human judgment and ownership.