
From Brute Force to Intelligent LLM Inference Optimization
LLM inference optimization is the discipline of reducing the compute, memory, and latency required to run large language models, using smarter scheduling, retrieval, and caching techniques instead of growing raw hardware capacity. Enterprises are under pressure to cut AI cost while keeping accuracy and latency stable, and three emerging approaches point to a new playbook. On the hardware side, sequence packing removes padding waste and improves GPU memory efficiency without changing model architectures. In retrieval-heavy workloads, parallel test-time scaling shrinks retrieval latency by running query expansion and reranking in parallel rather than in long sequential loops. Finally, memory engines avoid redundant context recomputation by restoring previously processed model states, shrinking the recurring costs of long-context workloads. Together, these methods show that AI cost reduction increasingly depends on how work is organized, not how large the cluster is.
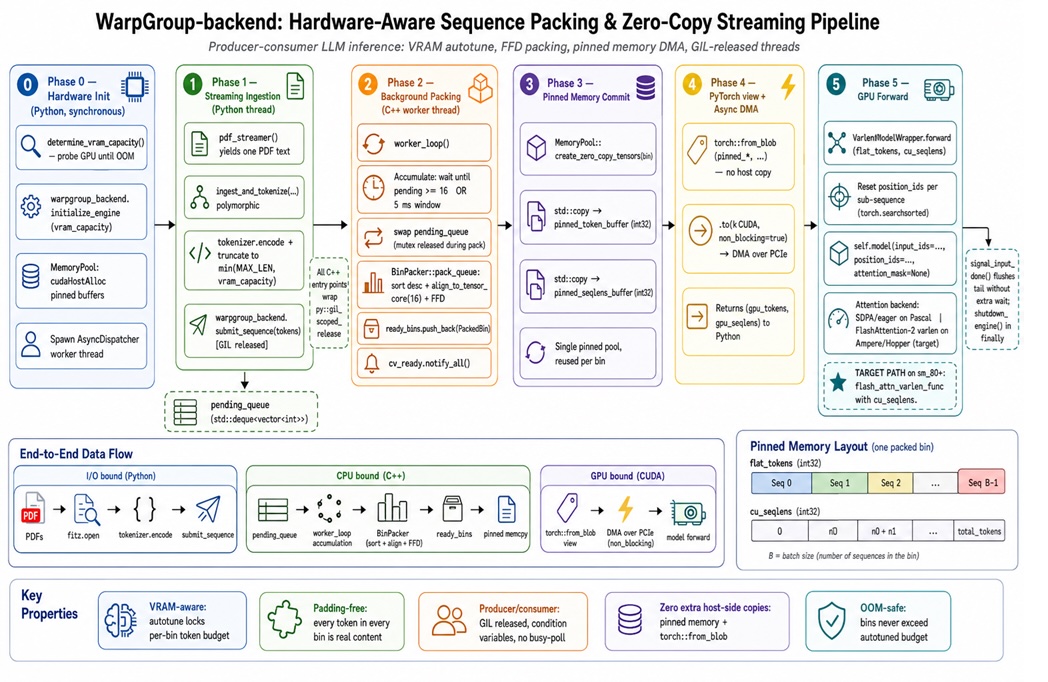
Sequence Packing: Ending Fake Work on the GPU
A major source of wasted compute in LLM inference is padding: batching variable-length prompts into a fixed rectangle so short sequences are filled with zeros. The WarpGroup-Backend tackles this by packing variable-length sequences into bins sized to fit real VRAM limits, then concatenating them into a single ribbon for variable-length attention kernels. Instead of multiplying zeros, the GPU processes dense, token-rich ribbons tuned to its preferred tile sizes, often in multiples of 16 tokens. The author reports that this hardware-aware packing yields up to 2.08× throughput on an H100 and 5.89× on a GTX 1080, with fewer out-of-memory failures. Because this approach sits in the batching layer, it does not require architectural reconfiguration of the model, making it a low-friction way to improve GPU memory efficiency and overall LLM inference optimization in production stacks.
Parallel Test-Time Scaling: Faster Retrieval Without Quality Loss
Databricks’ Instructed-Retriever-1 shows how parallel test-time scaling can cut retrieval latency without sacrificing answer quality. Instead of running a long sequence of tool calls and reasoning loops, the system expands queries and reranks documents in parallel in the initial search stage. This single model powers both query generation for higher recall and reranking for higher precision, but crucially runs these operations concurrently. According to Databricks, answer generation time dropped by 2× and search time by more than 3×, bringing time to first token to around two seconds, with no reconfiguration required for users. For enterprise agents, this means lower retrieval latency and lower compute usage per query, because the system spends less time waiting on sequential decision steps. The broader implication is that AI cost reduction can come from restructuring when and how retrieval work happens, not only from pruning models or shrinking context windows.
Memory Engines: Eliminating Redundant Context Recomputation
In long-context workloads, the largest recurring cost is often context recomputation: re-reading and re-encoding the same documents for each new query. Corbenic AI’s Taliesin memory engine addresses this by saving the model’s internal memory for a given context and restoring it later, byte-identical, on demand. The company describes scenarios where a model would otherwise reread a 100-page document ten times, effectively processing a thousand pages; Taliesin instead restores the prior state and continues generation. Corbenic reports that on a $0.69-per-hour graphics card, the longest test contexts that took more than two minutes to process from scratch were restored in under seven seconds, a 21-times speedup with no loss of accuracy. Taliesin has also been validated across GPU generations, with identical 64-of-64 output tokens in a relay between an Ampere A6000 and an Ada Lovelace RTX 4090, and cryptographic hashes published for independent verification.

The New Playbook: Smarter Utilization Over Bigger Clusters
Taken together, sequence packing, parallel retrieval, and memory engines mark a shift in LLM inference optimization: from more compute to smarter utilization. Packing removes padding-induced waste, keeping GPUs busy on useful tokens and improving GPU memory efficiency without modifying model architectures. Parallel test-time scaling reorganizes retrieval into concurrent operations, cutting search latency 3× and answer generation 2× while keeping quality stable. Memory engines attack context recomputation directly, caching and restoring long-context states to turn minutes of repeated work into seconds of reuse. None of these approaches require retraining models or redesigning architectures, which lowers the adoption barrier for enterprise teams. For organizations struggling with retrieval latency and the recurring cost of long-context queries, the message is clear: meaningful AI cost reduction now depends on how cleverly workloads are scheduled and remembered, not on buying the next tier of hardware.






