What Long-Context AI Models Are and Why a Million Tokens Matters
Long context AI models are large language or multimodal systems designed to process and remember far more input—often hundreds of thousands or a million tokens—within a single interaction, so they can handle entire projects or workflows without repeatedly losing track of earlier details and instructions. The sudden focus on a million token window marks a shift away from small, chat-sized prompts toward models that can treat whole codebases, document collections, or media archives as active working memory. Instead of heavy prompt engineering and manual chunking, these extended context windows allow users to keep more of their real work intact. Developers and companies now compare models not only on accuracy, but also on how much information they can keep in mind at once and how reliably they maintain coherence across long, complex tasks.
MiniMax M3 Joins the Million-Token Window Race
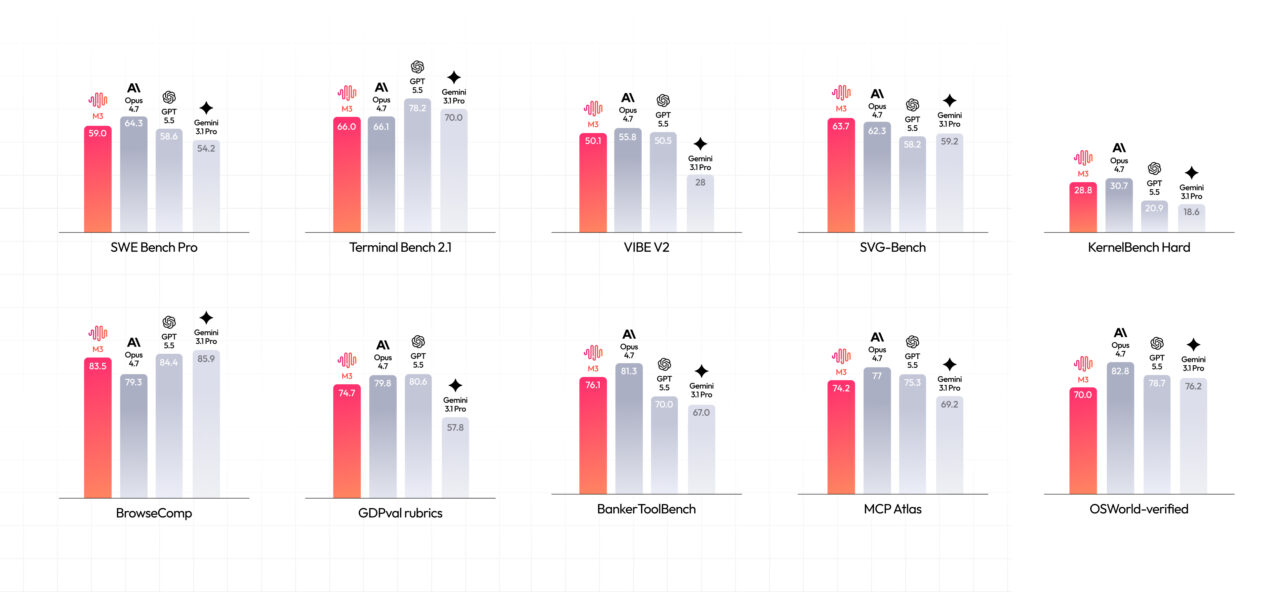
MiniMax’s new M3 model is a clear sign that the million-token window has become a competitive benchmark. M3 is presented as a frontier-class coding and agentic system with a 1 million-token context window and native multimodal processing in one architecture. It accepts text, images, and video as input and returns text output through OpenAI-compatible endpoints, so teams can plug it into existing tooling. According to MiniMax’s reported benchmarks, M3 reaches 59.0% on SWE-Bench Pro and 66.0% on Terminal Bench 2.1, putting it in the same conversation as closed frontier models such as Gemini 3.1 Pro and GPT 5.5. Pricing for access through the API is set at $0.60 (approx. RM2.76) per million input tokens and $2.40 (approx. RM11.04) per million output tokens, with open weights promised in a later technical release.
A Broader Long-Context Push: From Nemotron 3 Ultra to Domain Workbenches
MiniMax is not alone in chasing extended context windows. Nvidia’s Nemotron 3 Ultra, a 550B-parameter sparse Mixture-of-Experts model with 55B active parameters, is designed for long-context and agentic workloads and can handle up to 1 million tokens of context using a hybrid Transformer-Mamba architecture. That architecture aims to make long-context inference faster and cheaper while keeping model capacity high. At the same time, OpenAI is pairing long-context reasoning with domain depth: its updated GPT-Rosalind is positioned as a life-sciences workbench, combining GPT-5.5-style coding and tool use with specialized biology and drug-discovery workflows. These moves show that extended context windows are becoming a core design axis across general-purpose, open-weight, and domain-specific systems rather than a niche feature reserved for a few flagship chatbots.

What Extended Context Windows Change in Real Workflows
A million token window means a model can keep an entire software repository, a full legal case file, or a multi-quarter analytics project in active memory. For developers, that enables whole-repo refactors, cross-file bug hunting, and design documentation analysis without preprocessing source code into smaller segments. For analysts and researchers, long context AI models can read large literature collections, stay aware of earlier sections when summarizing, and preserve references across a long chain of reasoning. MiniMax’s M3 is pitched toward teams working “across source files, screenshots, diagrams, and other visual reference material,” who can now keep more of that workflow inside one model instead of juggling multiple tools. The result is fewer context resets, less copy-paste, and a closer match between how people work and how models process information.
Multimodal AI Capabilities and the Move Toward Context-Aware Systems
The most important shift may be the combination of extended context windows with multimodal AI capabilities. M3’s ability to accept text, images, and video in a million-token window means a single system can read a design document, interpret UI screenshots, and inspect code fragments in one pass. Nvidia’s broader model ecosystem and Google’s Gemma 4 12B, a natively open multimodal model that can process audio, point in the same direction: models that see, read, listen, and remember over long stretches. Meanwhile, platforms like OpenAI’s Codex add agents and plugins that operate over business tools, turning long-context models into orchestration engines for workflows rather than isolated chatbots. Together, these trends move the field away from single-task models toward more versatile, context-aware systems that feel closer to general-purpose digital collaborators.





