
A Million‑Token, Open‑Weight Challenger Enters the Arena
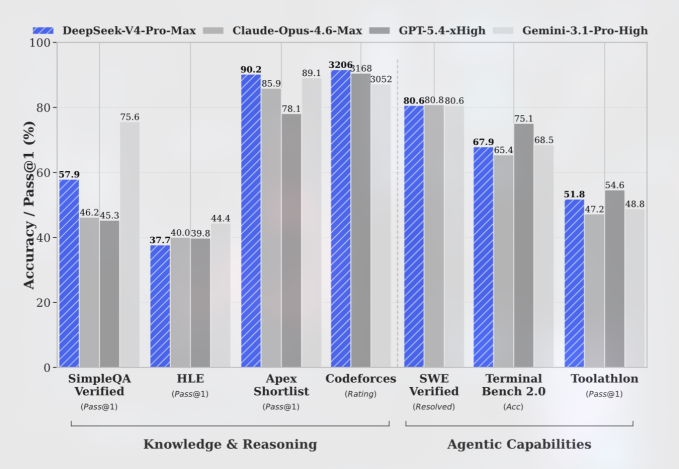
DeepSeek V4 model marks a new phase in the AI price war by pushing frontier‑class performance into an open‑weight package with a one‑million‑token context window. Both V4-Pro and V4-Flash use a mixture‑of‑experts architecture, activating only a subset of parameters per task to cut inference costs while keeping total parameter counts high. V4-Pro weighs in at 1.6 trillion parameters (49 billion active), making it one of the largest open models available, while the leaner V4-Flash uses 284 billion parameters (13 billion active). Benchmarks released by DeepSeek and independent coverage indicate the Pro variant now trails top frontier systems such as OpenAI GPT 5.5 and Gemini 3.1 Pro by only a few months of development, with particularly strong results in coding and reasoning tasks. The trade‑off is that V4 remains text‑only and still lags proprietary rivals in raw world‑knowledge breadth and multimodal capabilities.
V4-Pro vs V4-Flash: Rock‑Bottom Pricing Resets Expectations
DeepSeek has turned pricing into a weapon. V4-Pro’s API is listed at USD 1.74 (approx. RM8.10) per million input tokens on a cache miss and USD 3.48 (approx. RM16.20) per million output tokens, putting a simple million‑in, million‑out call at about USD 5.22 (approx. RM24.40). With cached input, the input rate reportedly drops to USD 0.145 (approx. RM0.70), pushing effective totals even lower. By contrast, OpenAI GPT 5.5 is priced at USD 5.00 (approx. RM23.40) per million input tokens and USD 30.00 (approx. RM140.40) per million output tokens, while Claude Opus 4.7 charges USD 5.00 (approx. RM23.40) input and USD 25.00 (approx. RM117.00) output. V4-Flash goes further, at USD 0.14 (approx. RM0.70) per million input tokens and USD 0.28 (approx. RM1.30) per million output tokens—over 98% below GPT 5.5 and Opus 4.7 in a like‑for‑like comparison. This undercuts not only Western frontier models but also many domestic competitors, forcing enterprises to revisit their cost‑benefit equations.
Memory Efficiency, Long Context AI—and the Risk of Losing the Needle
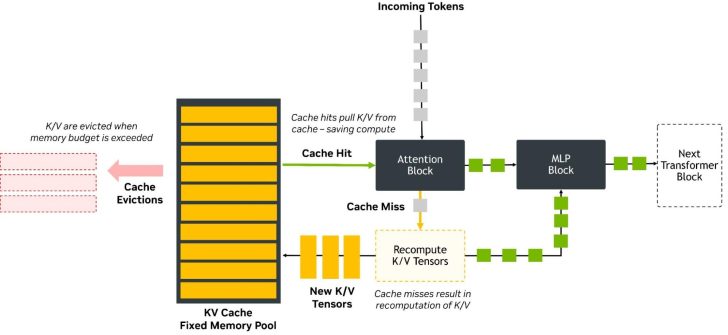
Under the hood, DeepSeek V4 leans on aggressive memory optimization to make long context AI viable at scale. Release notes describe a design that uses just 27% of the single‑token inference FLOPs and 10% of the key‑value (KV) cache of the earlier V3.2 model when running a one‑million‑token context. That reduction is crucial in the decode phase, where the model must constantly read and write KV cache to preserve conversation history. By shrinking the KV footprint, V4 can either serve more users per GPU or stretch context windows further without blowing up hardware budgets. However, this efficiency comes with a warning label: heavy KV compression can cause “needle in a haystack” failures, where small but critical details inside ultra‑long prompts are dropped or mis‑weighted. For enterprises planning million‑token workflows—massive contracts, full codebases, or multi‑month chat logs—the promise is lower cost, but only if they can tolerate occasional misses on fine‑grained retrieval and reasoning.
Huawei Ascend Chips and the Push for AI Self‑Reliance
A defining feature of DeepSeek V4 is its tight integration with Huawei Ascend chips, signalling a strategic pivot toward a more independent AI stack. Huawei says its newest Ascend 950PR and 950DT, along with the broader Ascend SuperNode and SuperPoD lines, enjoyed “day zero” adaptation with DeepSeek V4, supported by its CANN software stack—an analogue to Nvidia’s CUDA. DeepSeek confirms V4 can run inference on Ascend hardware and that these chips were used in parts of the training process. Analysts note this as a breakthrough: top‑tier models no longer need to depend exclusively on Nvidia accelerators, at least for deployment. Major platforms such as Alibaba, ByteDance and Tencent reportedly placed large orders for upcoming Ascend chips ahead of V4’s launch, betting that an all‑Chinese hardware‑software pipeline will insulate them from export controls. For enterprises, this creates a clearer choice between Western GPU ecosystems and a fast‑maturing, Huawei‑centered alternative.

Geopolitics, Model Replication Fears, and Enterprise Choices Ahead
DeepSeek’s rise has reignited political tensions around AI model replication. A White House memo warns that foreign entities are running “industrial‑scale” distillation campaigns against US AI tools, using thousands of accounts to jailbreak systems, extract proprietary behavior, and retrain rival models. While no company is named, firms like OpenAI and Anthropic have publicly accused DeepSeek of building unfairly on their technology. Washington officials argue that models trained this way may rest on “fragile foundations” even as they undercut Western rivals on price. For enterprises, the decision is no longer just OpenAI GPT 5.5 versus another premium closed model; it is proprietary versus open, sanctioned versus unsanctioned ecosystems, and cost savings versus regulatory and supply‑chain risk. DeepSeek V4’s ultra‑low prices could democratize access to near‑frontier intelligence, particularly for cost‑sensitive markets, but also complicate efforts to regulate safety, IP protection and cross‑border flows of advanced AI capabilities.