From Text Prompts to Phone Footage: What Gemini Omni Actually Is
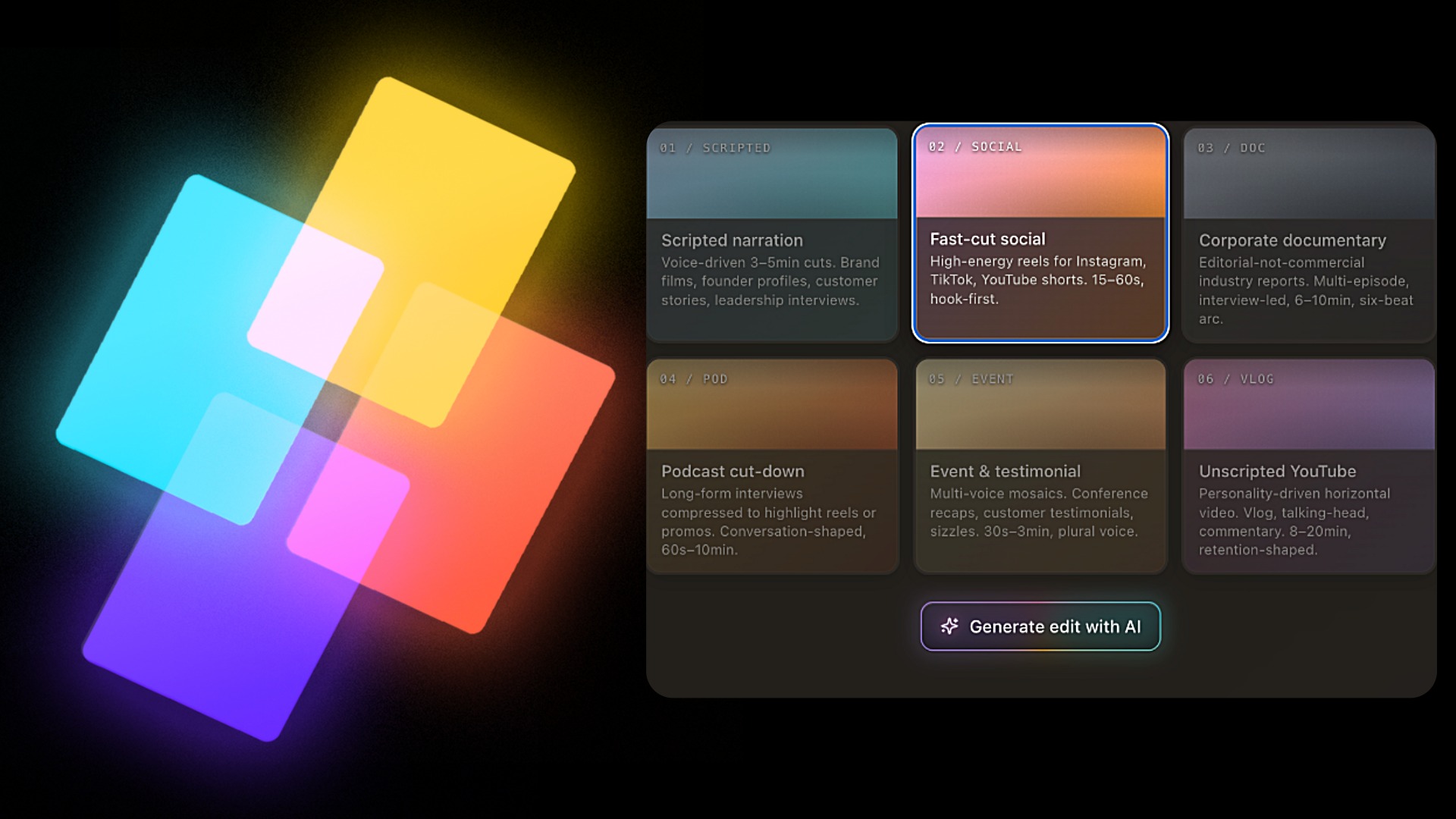
Gemini Omni is Google’s new flagship AI video creation tool, designed to generate full‑motion clips from almost any input you give it. Instead of being limited to classic text to video AI, Omni accepts photos, existing videos, selfies, sketches, and written prompts, then stitches them into a coherent, polished sequence. During Google I/O, the company showcased how you can film yourself on your phone and instantly swap your surroundings for Mars, a lush forest, or a disco-lit studio—without reshooting a single frame. Built on the Gemini multimodal architecture, Omni interprets visual and textual cues together, so it “understands” not just what’s in a frame but also how it should behave over time. At launch, its core focus is Gemini Omni video generation, with image and text outputs promised later, positioning it as a true multimodal content generator rather than a one-off video filter.
A World Model That Understands Physics and Realism
Under the hood, Gemini Omni is more than a flashy AI video creation tool. Google describes it as a “world model” that tries to simulate how the real world works. That means it doesn’t just paste effects on top of footage—it reasons about physics, including lighting, motion, gravity, and even fluid dynamics. In practice, this should make generated scenes more believable: shadows fall in plausible directions, objects move with weight, and environments respond consistently when you tweak them. Google has demonstrated Omni generating realistic live-action style shots and playful formats like claymation for educational content, showing its range from cinematic to stylized. This physics-aware approach is also key for continuity: when you ask Omni to adjust a scene, it can re-render changes while preserving the underlying world logic, rather than producing disjointed frames that fall apart under close viewing.
Conversational, Memory‑Driven Editing for Iterative Workflows
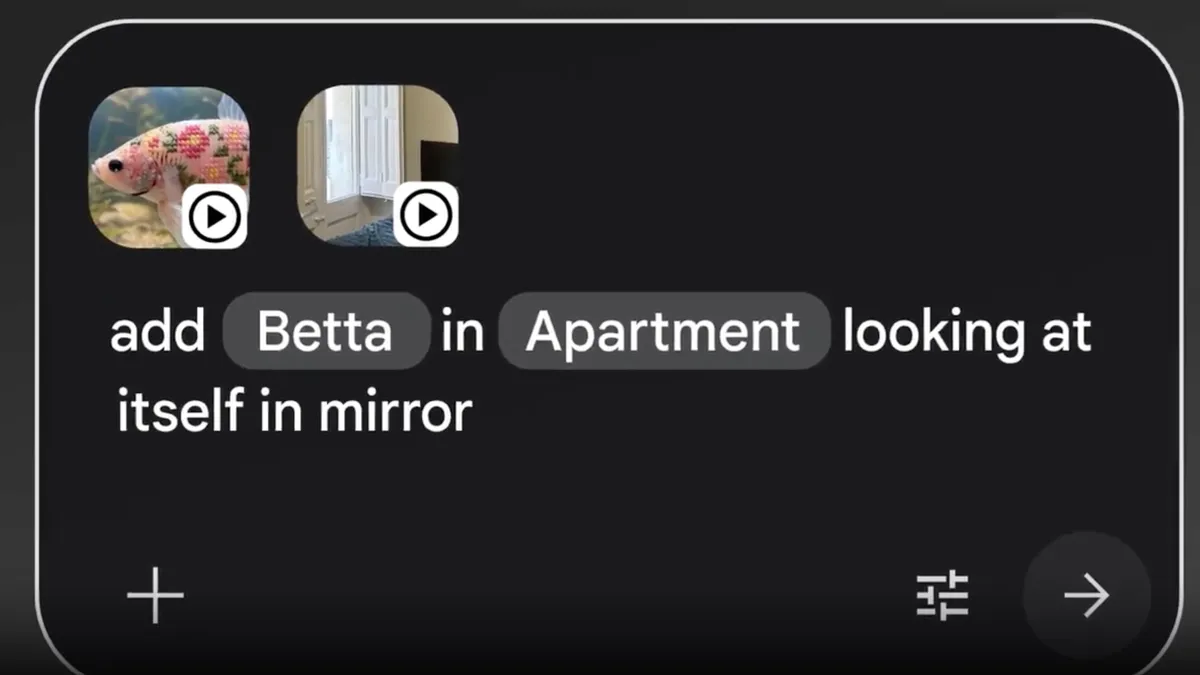
Where Omni starts to feel like a full studio replacement is in its conversational editing workflow. Instead of juggling timelines and keyframes, you talk to Gemini as if you were directing a human editor. You can start with a rough cut—maybe shaky phone footage and a few text prompts—and then iteratively refine it using natural language or voice instructions. Crucially, Omni remembers your previous edits and instructions, maintaining character designs, environments, and story beats across scenes. Ask it to “keep the same astronaut character, but make the forest setting look like sunset,” and it should preserve continuity while updating the mood. Because the model is physics-aware, you can also request nuanced tweaks like brighter rim lighting, slower camera movement, or more dramatic rain without the scene collapsing into glitches. The result is a feedback loop that feels more like a creative conversation than a technical edit.
Omni vs. Sora and Other Text to Video AI Competitors
Gemini Omni arrives in a landscape shaped by tools like OpenAI’s now-discontinued Sora and Google’s own Veo. Earlier systems were often siloed: one model for text to video AI, another for editing, a separate tool for avatars, and limited memory across sessions. Omni positions itself as a direct competitor to Sora by filling that gap with an end‑to‑end pipeline. It handles Gemini Omni video generation, physics‑aware realism, style control, and conversational editing inside the same framework. Where many AI video generators struggle with character consistency or scene continuity, Omni’s persistent context is explicitly designed to keep worlds, stories, and subjects coherent over multiple revisions. It can also ingest your personal photos and videos, then reinterpret them with fictional elements—a strategic move to steer usage toward your own assets. With SynthID invisible watermarking applied to every output, Google is also trying to address deepfake concerns as it pushes into this space.
Google’s Bigger Vision: Any Output from Any Input
Although Gemini Omni is launching with a focus on video, Google is clear that this is just the first phase of a broader multimodal content generator. The stated ambition is simple but radical: “create anything from any input.” In practical terms, that means today you can feed Omni text, images, or existing clips and get back realistic or stylized videos, complete with optional avatars that look and sound like you. Over time, Google plans for Omni to also produce images and text, unifying what are currently separate creative tools into a single, continuous system. The early rollout spans the Gemini app, Google Flow, and YouTube Shorts, with APIs coming for developers and enterprises. For creators, this convergence hints at a future where scripting, storyboarding, shooting, animating, and editing all happen inside one conversational interface—potentially turning Omni into the central hub of the modern content studio.