Why AI Speed Matters More Than Ever
The fastest AI models are systems that can generate or process language at very high tokens per second, reducing latency so responses feel instant in real applications rather than like a queued batch job. Speed has shifted from a benchmark curiosity to a core product decision: slow models break chat flows, stall code assistants, and bottleneck long‑running agents. Tokens per second is now a practical measure of productivity, not only a lab metric. A jump from 130 to 300 tokens per second can mean cutting multi-minute document runs down to seconds when called hundreds of times a day. That is why AI model benchmarks increasingly highlight inference speed alongside accuracy. For teams with strict service level agreements or heavy GPU usage, throughput and GPU performance shape which models are even feasible to run at scale.
Speed Rankings: How The Fastest AI Models Stack Up
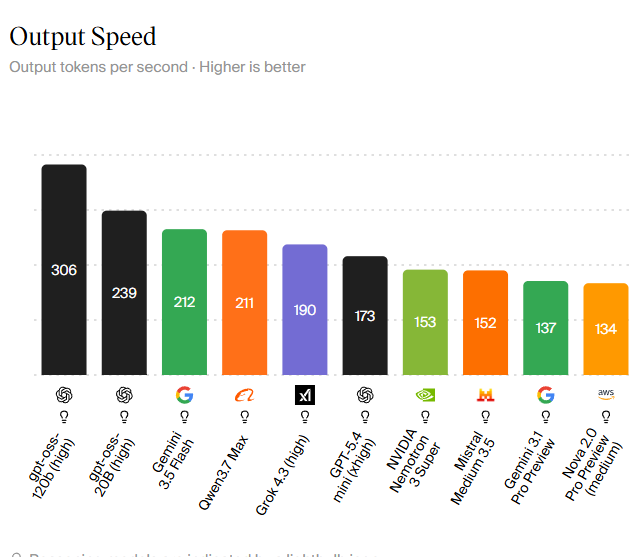
Recent AI model benchmarks show a clear gap between the top and bottom of the speed chart. According to OfficeChai’s summary of the Artificial Analysis index, the fastest listed model, GPT-oss 120B (High), reaches 306 tokens per second, while the tenth, AWS Nova 2.0 Pro Preview (Medium), sits at 134 tokens per second. That is more than a 2x difference in throughput over long runs. In between, GPT-oss 20B (High) delivers 239 tokens per second, Google Gemini 3.5 Flash hits 212 tokens per second, Alibaba Qwen3.7 Max reaches 211 tokens per second, and xAI Grok 4.3 (High) posts 190 tokens per second. OpenAI GPT-5.4 Mini (xHigh), NVIDIA Nemotron 3 Super, Mistral Medium 3.5, and Google Gemini 3.1 Pro Preview fill out a crowded middle band from 173 to 137 tokens per second.
Ultra-Fast Outlier: Xiaomi MiMo-V2.5-Pro UltraSpeed
Xiaomi’s MiMo-V2.5-Pro UltraSpeed mode sits outside typical cloud rankings because it targets extreme throughput on standard GPUs. The company says the 1-trillion-parameter model now breaks the 1,000 tokens-per-second barrier by co-designing the model and inference system with TileRT. For context, an earlier family member, MiMo-V2-Flash, generated around 150 tokens per second at launch, already fast enough to output text faster than humans can read or speak. Xiaomi claims UltraSpeed offers roughly ten times faster output than standard MiMo-V2.5-Pro API access. That gain comes with higher cost: the UltraSpeed API is described as a three-times price increase, and token plans are not supported. Access is limited to an application-based API trial window, with two weeks of free chat, daily queue caps, and session limits to manage constrained high-speed inference capacity.
Open-Source, Frontier, and the Speed–Quality Tradeoff
The comparison list shows that some smaller or open-weight models can rival frontier systems on speed while remaining strong on specific tasks. GPT-oss 20B and GPT-oss 120B, for example, lead the published speed table, reflecting heavy optimization and infrastructure. Mid-pack entries like NVIDIA Nemotron 3 Super at 153 tokens per second and Mistral Medium 3.5 at 152 tokens per second illustrate how efficient architectures can close the gap with larger proprietary models. Meanwhile, Google’s Gemini family splits roles: Gemini 3.5 Flash at 212 tokens per second favors throughput for agentic workloads, while Gemini 3.1 Pro Preview at 137 tokens per second favors quality. For many developers, the question is not “fastest at any cost” but “fast enough for my accuracy needs and hardware budget,” which makes tokens per second one dimension alongside context length, tools, and reasoning strength.
Choosing the Right Model: Latency, GPUs, and Trial Access
Picking among the fastest AI models starts with latency targets and GPU performance constraints. Real-time chat, coding assistance, and interactive agents often need triple‑digit tokens per second to feel responsive, especially when streaming long outputs. Batch backends and document processing can accept more delay but benefit from higher throughput to reduce GPU hours. Speed-per-dollar also matters: some high-compute tiers and ultra-speed modes charge more but may still be cheaper at scale if they cut run time enough. Limited-time API trials, such as Xiaomi’s application-based UltraSpeed window with capped sessions and free access, give teams a way to profile inference speed, tune prompts, and test parallelism before committing to production. Combining these trials with public AI model benchmarks helps developers choose a model that meets quality needs while staying within latency and hardware limits.





