What SynthID Watermarking Is and Why It Matters Now
SynthID watermarking is a method developed by Google DeepMind that embeds imperceptible signals into AI-generated images, audio, video, and text so that their synthetic origin can be detected later, even after common edits, resaving, or format changes, making it a cornerstone technology for AI content verification and deepfake detection across the modern media ecosystem. Instead of adding a visible label, SynthID hides a pattern directly inside the pixels of an image or the waveform of audio. Detection tools then scan for this pattern to support AI provenance tracking. This approach is designed to survive resizing, screenshots, compression, and light editing. As AI image generators and voice models grow more convincing, the ability to track where media came from is becoming as important as generating it, turning watermarking from a niche safety feature into a basic requirement for responsible AI deployment.
From Google Experiment to Industry Standard for AI Provenance
Google has pushed SynthID beyond its own Gemini ecosystem, and rivals are starting to treat it as shared infrastructure. OpenAI, ElevenLabs, Kakao, and Nvidia are all adopting SynthID watermarking across their models, from images in ChatGPT and the OpenAI API to video from Nvidia’s Cosmos foundation models and audio from ElevenLabs. According to Google’s May update, “SynthID has already watermarked more than 100 billion images and videos and 60,000 years of audio across Google’s own products.” At this scale, AI provenance tracking begins to look less like an experiment and more like a de facto standard. The key change is that watermark signals now cross product boundaries: content generated in one company’s tools can be detected and flagged by another’s systems, which is vital for cross-platform AI content verification and deepfake detection.

How SynthID and C2PA Metadata Work Together
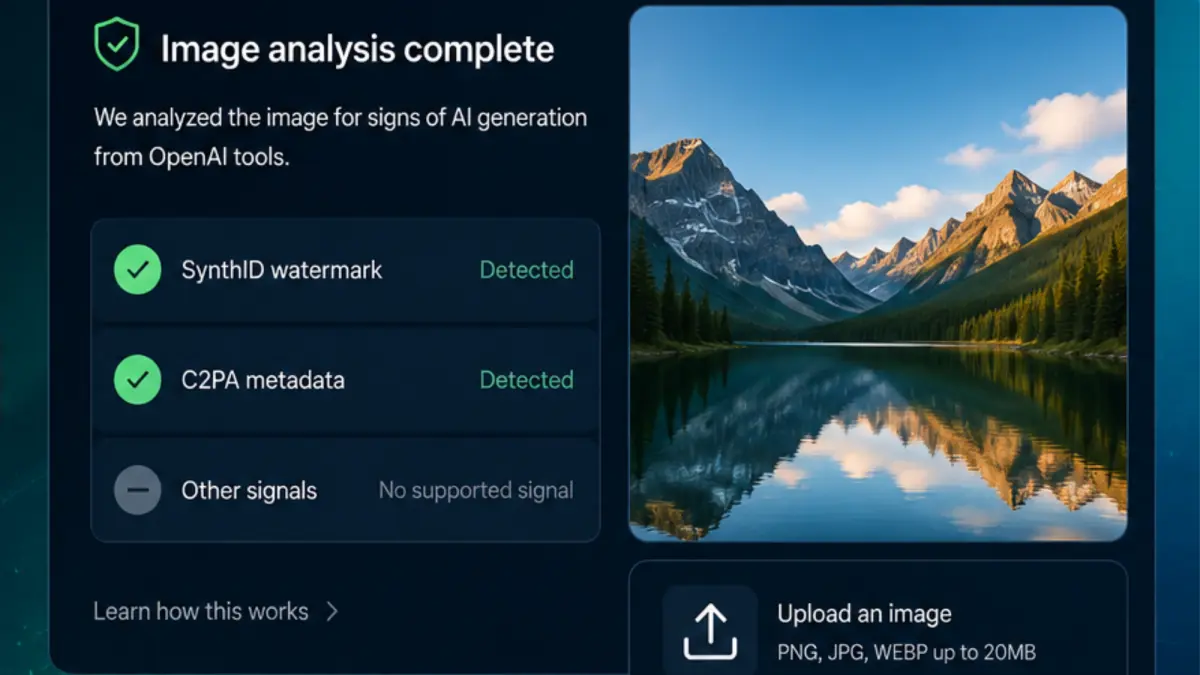
SynthID is not replacing existing metadata standards; it is filling their gaps. C2PA metadata, sometimes called Content Credentials, attaches information about how a file was created or edited, including whether AI tools were used. However, metadata can disappear when a file is resaved, downloaded, screenshotted, or run through another app. SynthID watermarking addresses this by hiding a durable signal inside the media itself. OpenAI has become a C2PA Conforming Generator Product and is rolling out a multi-layer approach that checks both SynthID and C2PA metadata in its new public image verification tool. The tool currently focuses on images created through ChatGPT, the OpenAI API, and Codex. In practice, C2PA metadata offers richer context, while SynthID provides a fallback when that metadata is missing, creating a more reliable AI content verification stack for platforms and publishers.
Google Cloud’s Content Detection API and Enterprise Deepfake Detection
To make AI provenance tracking usable at enterprise scale, Google is previewing a Content Detection API on its Gemini Enterprise Agent Platform. The API accepts JPEG, PNG, or WebP images and uses machine learning to examine pixel-level artifacts, noise patterns, and spectral anomalies. It is designed to detect AI-generated content produced not only by Google’s own models but also by other popular systems, extending AI content verification across mixed media pipelines. Google says the API does not store processed images, a key point for risk-sensitive customers. Early partners such as Shutterstock, Snap, Fox Sport, and Canva are testing how detection can support content moderation, feed ranking, insurance fraud checks, and user-facing labels on synthetic media. In parallel, Google is expanding SynthID-based verification to its Gemini app and plans to extend similar capabilities to Search, Chrome, and Pixel cameras via C2PA metadata.
Publishers, Research Integrity, and the New Provenance Baseline
As watermarking becomes standard in AI systems, downstream publishers are beginning to treat AI provenance tracking as a non‑negotiable part of their workflows. Academic and professional publishers such as Wiley are integrating image screening tools to help spot AI-generated visuals in submissions, aiming to reduce the risk of deepfake figures, fabricated microscopy images, or synthetic diagrams entering the scholarly record. These tools combine deepfake detection methods, C2PA metadata checks, and, increasingly, SynthID signals where available. For newsrooms, advertisers, and compliance teams, the bar is rising: if leading generators from Google, OpenAI, Nvidia, and ElevenLabs all ship watermarked output, platforms that cannot identify AI media will look exposed. The emerging expectation is clear—AI-generated content should arrive with detectable provenance, and systems that ignore watermark signals will struggle to maintain user trust and regulatory confidence.





