
What Claude Opus 4.8 Is and Why It Matters for Developers
Claude Opus 4.8 is Anthropic’s new flagship large language model release that focuses on AI code quality improvements, faster API performance, and tighter behavioral control for developers building production systems. Positioned as an upgrade to Opus 4.7, it arrives in the middle of an intense agentic AI race with OpenAI’s GPT-5.5 and Google’s Gemini 3.1 Pro. Anthropic describes Opus 4.8 as a “modest but tangible improvement,” but the numbers tell a stronger story for day-to-day coding. The model is four times less likely to let flaws in its own code pass unnoticed, which translates into about a 75% reduction in silent code defects compared to the previous version. Combined with a 2.5x speed fast mode and no change in headline pricing, Opus 4.8 aims to deliver more reliable coding assistance and shorter feedback loops without forcing teams to rewrite existing integrations.
Code Quality: 75% Fewer Silent Defects and Sharper Judgement
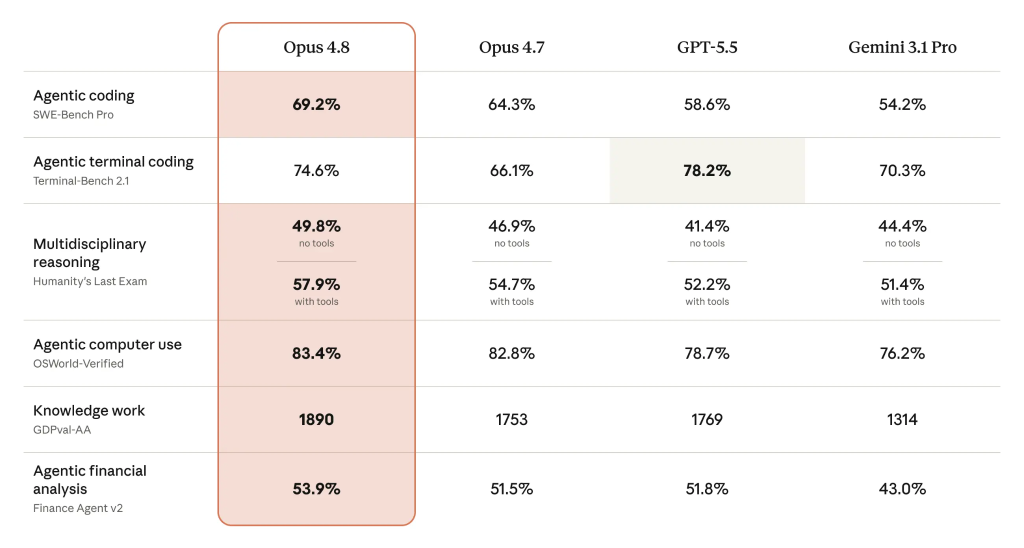
For developers, the headline improvement in Claude Opus 4.8 features is code quality. Anthropic reports the model is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked,” which means a roughly 75% drop in undetected defects. Early testers say Opus 4.8 now flags uncertainties more often and makes fewer unsupported claims, so developers see clearer warnings when the model is unsure about a change or fix. On structured evaluations, Opus 4.8 raises agentic coding scores from 64.3% to 69.2% and improves multidisciplinary reasoning with tools and financial analysis, suggesting broader gains beyond programming alone. These improvements help shift AI pair programming from “helpful but risky” toward “reliable enough for critical paths,” especially in large refactors and migration work where missed edge cases can be expensive to find later.
Speed, Effort Controls, and Faster API Performance
Performance gains are the second major pillar. Opus 4.8’s fast mode now runs at 2.5 times its normal speed while costing three times less than earlier fast configurations, which makes high-throughput workloads more accessible. Pricing for the base model remains flat at USD 5 (approx. RM23) per million input tokens and USD 25 (approx. RM115) per million output tokens, letting teams swap in Opus 4.8 without a budget reset. A new Effort Control slider on claude.ai and Cowork lets users dial how much processing the model applies to a response: lower effort returns quicker, cheaper answers, while high effort yields deeper reasoning and more thorough checks. Opus 4.8 defaults to high effort, balancing latency with quality. For developers, this means fine-grained tradeoffs between speed and thoroughness on a request-by-request basis, especially useful in CI bots, chat-based code review, and interactive debugging.

Dynamic Workflows and Large-Scale Coding Tasks
Dynamic Workflows, currently in research preview for Claude Code, targets larger engineering problems than single-file edits. The feature allows Opus 4.8 to plan work and run hundreds of parallel subagents within one session, then verify their outputs before returning results. Anthropic highlights codebase-scale migrations as a key use case, claiming Claude can now manage transformations across hundreds of thousands of lines of code from kickoff to merge. This moves AI assistance closer to project-level tooling instead of only function-level completions. Combined with higher scores in knowledge work and agentic compute use, these dynamic workflows suggest Opus 4.8 can stay productive and context-aware over longer, more complex tasks. For teams experimenting with AI-assisted refactors, monolith-to-microservice transitions, or large dependency upgrades, the model’s ability to coordinate and validate many substeps may shorten timelines while reducing manual oversight.
Benchmarks, Honesty Gains, and How It Compares to GPT-5.5
On developer AI benchmarks, Opus 4.8 is designed to compete directly with GPT-5.5 and Gemini 3.1 Pro. Anthropic reports a 69.2% score on SWE-Bench Pro, ahead of GPT-5.5 and Gemini 3.1 Pro on this coding benchmark, while also lifting agentic compute use to 83.4%. However, GPT-5.5 still edges ahead in agentic terminal coding, where Opus trails by 3.6 percentage points, which may matter for tools that depend heavily on shell-like autonomy. Beyond raw scores, Anthropic emphasizes alignment changes: Opus 4.8 shows lower deception rates, stronger support for user autonomy, and more forthright progress reporting. Early testers note that it now interrupts sooner when tasks become unsafe or poorly specified and is clearer when it cannot complete a request. For mission-critical workflows—such as financial analysis, production incident response, or regulated environments—these honesty and reliability gains may be as important as its numerical benchmark lead.





