What RTX Spark Is and Why Local AI Agents Matter
RTX Spark is NVIDIA’s new Windows PC platform that combines a Blackwell-based superchip, unified memory, and the full RTX AI software stack to run local AI agents directly on-device without relying on the cloud. It turns a thin-and-light laptop into a personal AI computer that can execute agentic workflows, creative tools, and games with low latency and stronger privacy than cloud-only assistants. With up to 1 petaflop of AI performance and 128GB of unified memory, RTX Spark Windows PCs are built to keep large models and complex multi-step tasks on the user’s machine. Instead of sending prompts and data to remote servers, local AI agents can reason over files, automate cross-app workflows, and generate content while keeping sensitive information inside Windows. This shift positions the PC as an intelligent teammate rather than a thin client to distant AI infrastructure.
Blackwell Architecture Laptops Bring Data Center AI On-Device
At the heart of RTX Spark Windows PCs is NVIDIA’s Blackwell architecture, the same technology family used in its data center AI platforms. By folding this architecture into a single "superchip" for laptops and compact desktops, NVIDIA merges CUDA cores, RTX graphics, Tensor cores, and AI accelerators into one on-device AI platform. According to NVIDIA, RTX Spark systems deliver up to 1 petaflop of AI compute and 128GB of unified memory, enough to keep frontier-scale models and complex agentic pipelines in local RAM instead of streaming them from the cloud. For developers and enterprises, that means the same CUDA, TensorRT, DLSS, OptiX, Reflex, and G-SYNC ecosystem they use in servers is now available in Blackwell architecture laptops for AI model inference, coding assistance, and content creation. This alignment turns the Windows notebook into a small but capable edge node for advanced AI workloads.
On-Device AI Inference, Privacy, and 2x Faster Llama Models
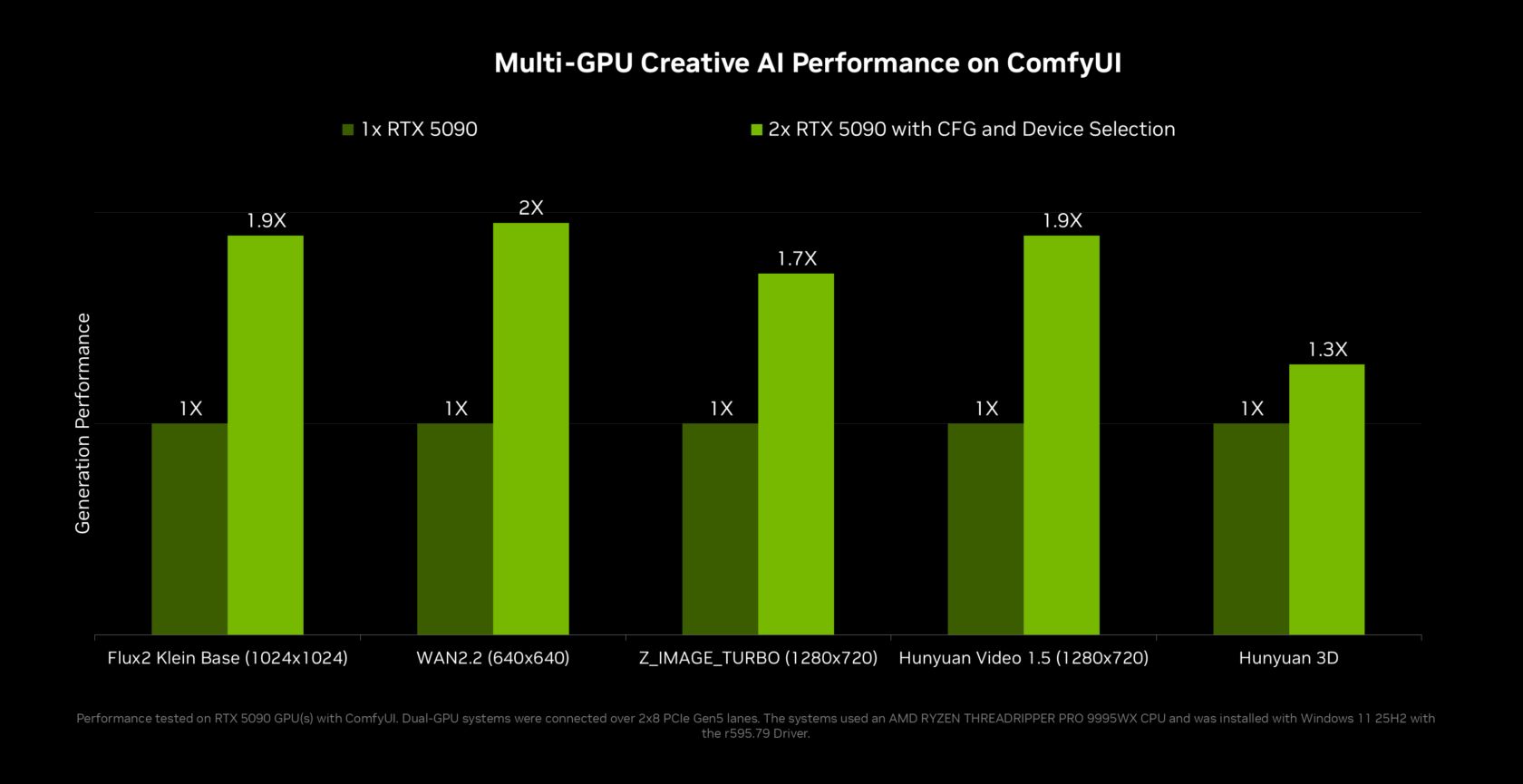
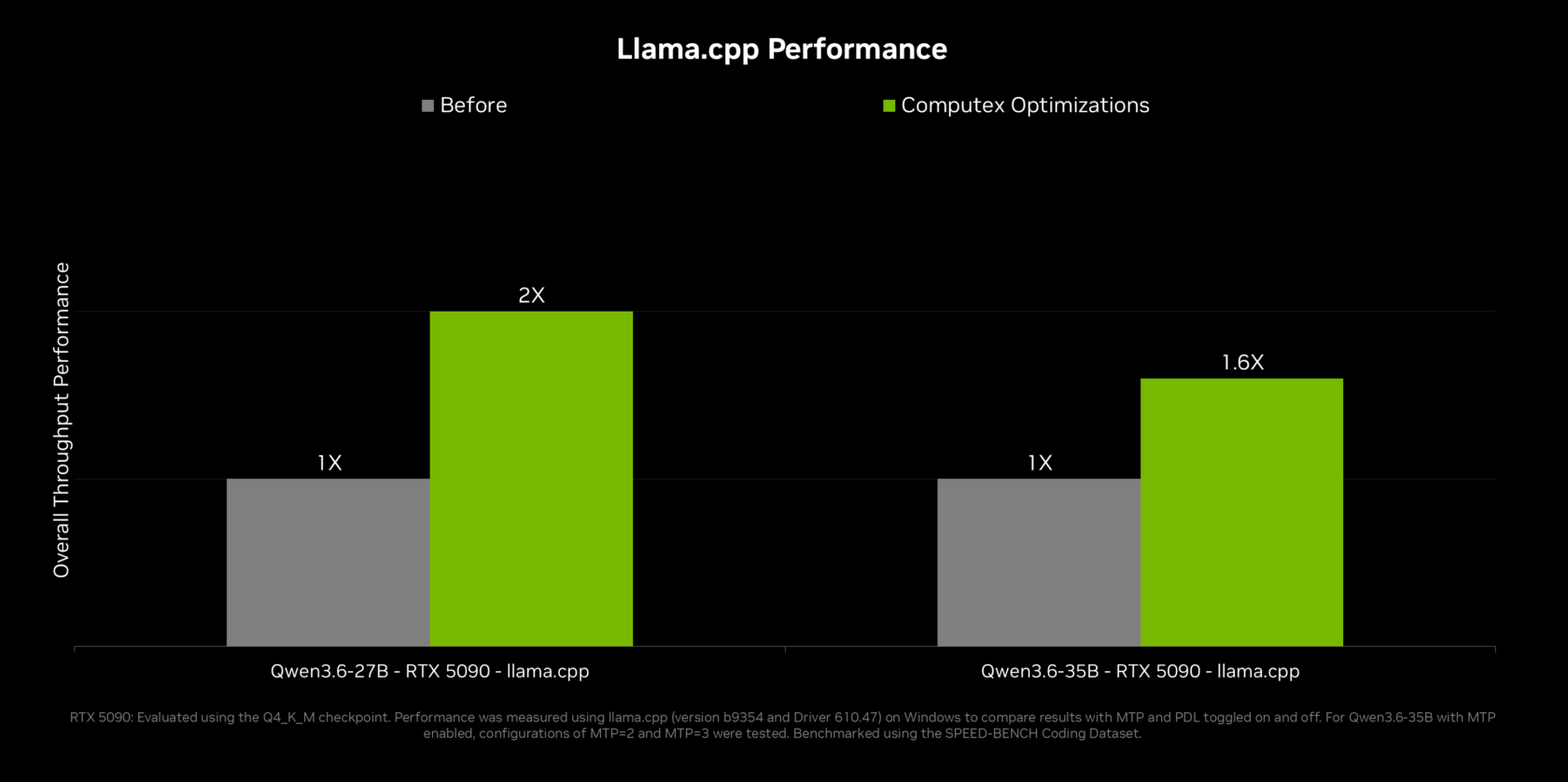
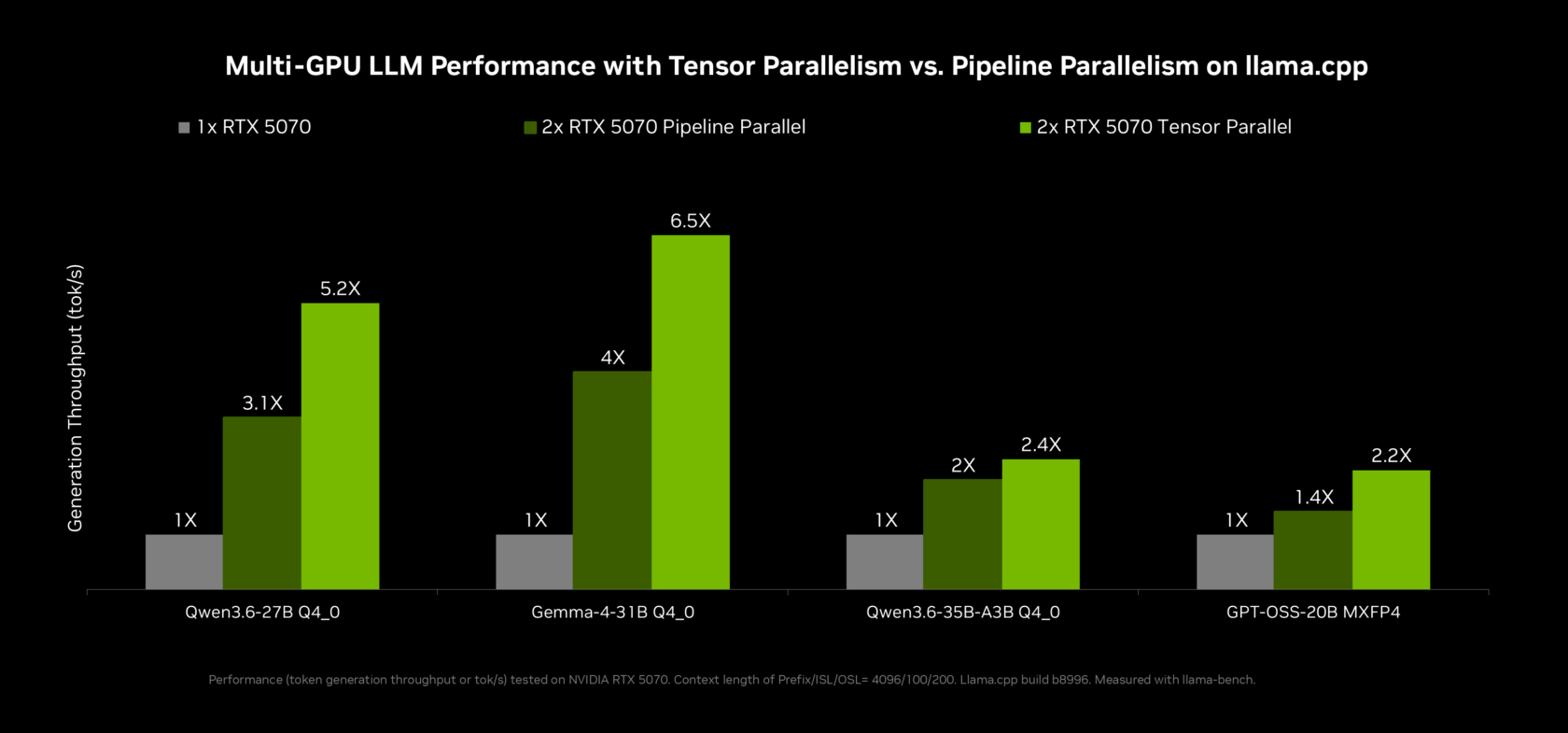
RTX Spark is designed around on-device AI inference, cutting round trips to remote servers while boosting privacy and responsiveness. Local AI agents can run models like Llama, Qwen and others directly on the GPU, taking advantage of new optimizations in llama.cpp and vLLM. NVIDIA reports "2x inference performance on top agentic models with multi-token prediction in llama.cpp and vLLM," which helps local agents respond faster and handle longer, more complex conversations. Multi-GPU and multi-token improvements also increase throughput for creative pipelines in tools such as ComfyUI. Because the models live on the machine, personal context—documents, media, and app state—can be processed without leaving Windows. When cloud models are required, NVIDIA OpenShell can disguise personal information and route requests based on user privacy policies, keeping sensitive prompts and data under tighter control than typical browser-based AI tools.
NVIDIA–Microsoft Security Stack for Local AI Agents
To make local AI agents reliable on everyday PCs, NVIDIA and Microsoft are building a joint security and control layer into Windows. Microsoft is adding new security primitives for agents—covering identity, containment, policy, and end-to-end security—so that AI software can run natively but stay within clear boundaries. On top of this, the NVIDIA OpenShell runtime adds user-defined policies that specify what each agent is allowed to do, from file access to app control. OpenShell can route queries to local models when privacy is critical, or to the cloud when needed, and can also disguise personal information before any remote call. Agent developers such as Hermes Agent and OpenClaw are baking these capabilities into new Windows applications. Their agents will be able to execute tasks in Windows apps, manage multi-step workflows, and search local files while honoring user-defined security rules.
Creative Apps, RTX Spark PCs, and the New Windows AI Baseline
RTX Spark is also reshaping how creative and productivity software is built for Windows. Adobe is rearchitecting Photoshop and Premiere to tap into RTX Spark’s AI acceleration, while Blender is adding DLSS 4.5 Ray Reconstruction and NVIDIA is introducing RTX Video Frame Generation for pipelines such as ComfyUI. These changes aim to make on-device AI inference a default part of editing, rendering, and effects workflows, rather than an optional cloud add-on. NVIDIA Broadcast 2.2 and Project G-Assist updates further tie streaming and gaming tools into the same AI stack. Hardware partners including ASUS, Dell, HP, Lenovo, Microsoft Surface and MSI plan to ship RTX Spark Windows PCs this fall, with Acer and GIGABYTE to follow. Targeted at creators, AI developers and power users, these systems position Blackwell architecture laptops as the new baseline for local AI agents on Windows PCs.