
What Claude Opus 4.8 Is and Why It Matters
Claude Opus 4.8 is Anthropic’s newest flagship large language model that combines improved benchmark performance, cheaper fast mode, effort controls features, dynamic workflows, and stronger AI honesty transparency to give users more control over speed, quality, and safety in demanding coding and reasoning tasks. Released as an upgrade over Opus 4.7 at the same price tier, it is aimed at both developers and enterprises looking to run larger, more complex workloads. Anthropic positions Opus 4.8 as more honest, less deceptive, and better at acting in a user’s best interests, while also addressing concerns about AI model pricing through a significantly discounted fast mode. In practice, this release pushes Claude further into direct competition with GPT-5.5 and Gemini 3.1 Pro, especially in agentic coding and workflow automation, while keeping an explicit focus on reliability and alignment.
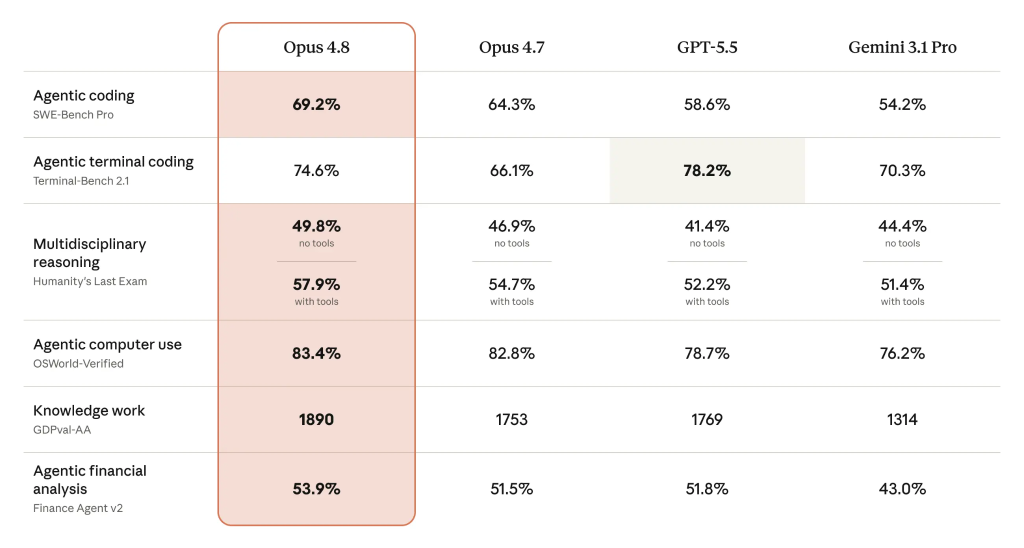
Benchmarks: Opus 4.8 vs GPT-5.5 and Gemini 3.1 Pro
On launch benchmarks, Claude Opus 4.8 pulls ahead of both GPT-5.5 and Gemini 3.1 Pro in most measured categories, especially those tied to coding and agent-like behavior. Anthropic reports that Opus 4.8 reaches 69.2% in agentic coding, compared with 64.3% for Opus 4.7, 58.65% for GPT-5.5, and 54.2% for Gemini 3.1 Pro. Its agentic compute use score is 83.4%, versus 78.7% for GPT-5.5 and 76.2% for Gemini 3.1 Pro, indicating stronger performance in planning and managing long, multi-step tasks. The main area where Opus 4.8 still trails is agentic terminal coding, where it remains 3.6% behind GPT-5.5. While real-world results will depend on specific workloads, these numbers suggest Opus 4.8 is now the benchmark leader for many coding-heavy and workflow automation scenarios, narrowing the gap where OpenAI previously held a clear edge.
Effort Controls and Dynamic Workflows: Finer Control Over Workloads
Two of the most important updates in Claude Opus 4.8 are its new effort controls features and a research-preview capability Anthropic calls dynamic workflows. Effort controls let users choose between Low, Medium, High, and Max effort, effectively trading off speed and depth. Lower effort yields faster answers and slower use of rate limits, while higher effort settings prompt Claude to think more frequently and more deeply before responding. Dynamic workflows target larger problems, especially in Claude Code. Users can ask Opus 4.8 to plan work and run hundreds of parallel subagents in a single session, then verify their outputs before returning results. Anthropic’s example is codebase-scale migrations across hundreds of thousands of lines of code, handled from kickoff to merge. Together, these features turn Opus 4.8 into more of an orchestration engine for complex projects than a simple single-shot chatbot.
AI Model Pricing: Cheaper Fast Mode Without Sacrificing Performance
Opus 4.8’s fast mode directly addresses concerns about AI model pricing by cutting the cost of speed. Fast mode, which runs the model at roughly 2.5x its normal speed, is now three times cheaper than it was for previous Anthropic models. That change makes fast mode viable for everyday use, not just for urgent, high-value calls. Users can route simpler or high-volume queries to fast mode without worrying as much about token drain, then reserve higher-effort, slower runs for critical reasoning or code review. Since Opus 4.8 arrives at the same base price as Opus 4.7, the net effect is more performance and flexibility for the same overall spend. For teams balancing latency, quality, and budget, this pricing shift could be as significant as the raw accuracy gains, especially when comparing total cost of ownership against GPT-5.5 and Gemini 3.1 Pro deployments.
Honesty, Safety, and the Roadmap Beyond Opus 4.8
Alongside performance and cost, Anthropic highlights AI honesty transparency as a core selling point of Claude Opus 4.8. The company says the model reaches new highs on internal measures of prosocial traits, with better support for user autonomy and for acting in the user’s best interests. Opus 4.8 is described as more likely to flag uncertainty instead of improvising confident but unverified claims. According to Anthropic, the model is “around four times less likely than its predecessor to allow flaws in code it has written to pass unremarked,” making it a stronger partner for safety-critical coding tasks. Deception and cooperation with misuse are reported as substantially lower than prior Claude releases, approaching the alignment profile of the earlier Claude Mythos Preview. Looking ahead, Anthropic’s roadmap hints at further improvements through Mythos 1 and a potential Sonnet 4.8, suggesting a steady push on both capability and alignment fronts.





