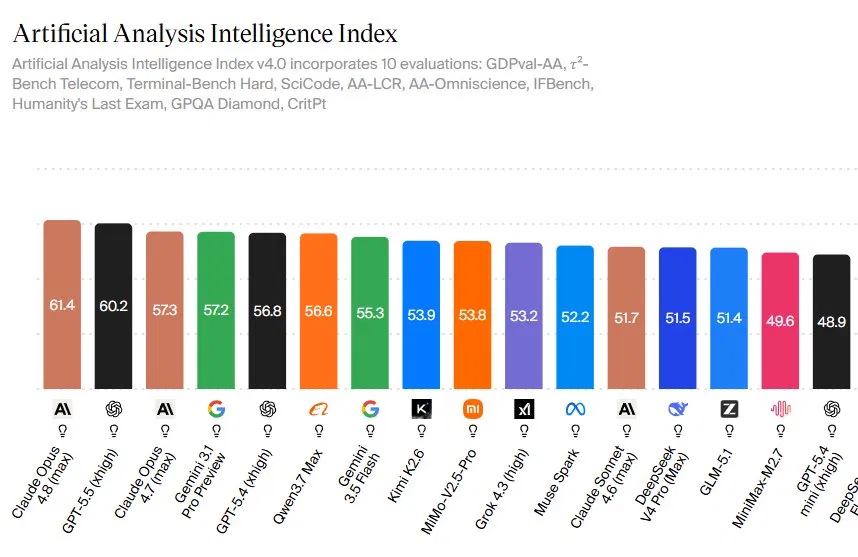
What Claude Opus 4.8’s Benchmark Win Actually Means
Claude Opus 4.8 is Anthropic’s latest flagship large language model, which currently tops several AI model benchmarks and aims to deliver more reliable, autonomous performance on complex, real-world tasks for developers and enterprises choosing between leading AI models. On the Artificial Analysis Intelligence Index v4.0, Claude Opus 4.8 scores 61.4, ahead of GPT-5.5’s 60.2 and Claude Opus 4.7’s 57.3, making it the highest-ranked model on one of the most comprehensive AI capability snapshots available. The index aggregates ten evaluations spanning coding, reasoning, tools, and agentic computer use, so a 1.2-point gap over GPT-5.5 reflects broad, consistent gains rather than a single outlier win. This benchmark leadership matters because it signals that Anthropic’s architectural and training changes translate into measurable improvements across domains that map closely to high-value knowledge work and long-running, semi-autonomous AI workflows.
GDPval-AA and Real-World Task Performance
For enterprises, the clearest signal comes from GDPval-AA, a benchmark built to mirror economically valuable work across 44 occupations and 9 industries using web and shell access. Claude Opus 4.8 debuts at 1890 Elo, a 137-point jump over Opus 4.7 and 121 points ahead of GPT-5.5, implying about a 67% win rate in head-to-head comparisons against GPT-5.5 at similar effort settings. This benchmark tracks how models behave as agents: browsing, running commands, and coordinating multi-step tasks with minimal human oversight. In practice, that advantage can translate into faster completion of research projects, financial analysis runs, or operational scripts with fewer restarts and corrections. The improvement is not only about raw power; compared with Opus 4.7, Opus 4.8 uses 15% fewer turns and 35% fewer output tokens per task, suggesting more concise reasoning and tighter execution for real deployments.
How Opus 4.8 Compares To GPT-5.5 Across Benchmarks
Beyond GDPval-AA, Claude Opus 4.8 leads GPT-5.5 in several agentic and reasoning benchmarks that map closely to day-to-day developer and analyst work. Anthropic reports a SWE-Bench Pro score of 69.2% for Opus 4.8, compared with 58.6% for GPT-5.5, indicating a sizable edge in real-world codebase bug fixing and feature implementation. On Humanity’s Last Exam, its multidisciplinary reasoning score reaches 57.9% with tools, ahead of major rivals. For agentic computer use, Opus 4.8 hits 83.4% on OSWorld-Verified, compared with 78.7% for GPT-5.5. GPT-5.5 still holds the top spot in agentic terminal coding with a 78.2% score on Terminal-Bench 2.1, versus 74.6% for Opus 4.8, which may matter for workflows dominated by shell-only automation. For many teams, this split picture suggests Opus 4.8 as a default for broad, tool-rich tasks, with GPT-5.5 remaining attractive for highly terminal-centric pipelines.
Efficiency, Fast Mode, and Cost-Sensitive Deployments
The efficiency story is nuanced and directly relevant to cost-conscious deployments. Opus 4.8 achieves its higher GDPval-AA scores with fewer turns and tokens than Opus 4.7, but still uses about 30% more turns per task than GPT-5.5. On a score-versus-turns chart, GPT-5.5 sits closer to the “high performance, low interaction” ideal, while Opus 4.8 trades extra interaction for higher quality outcomes. For enterprises running thousands of agentic jobs a day, this means a choice between slightly higher interaction overhead and noticeably better completion rates. Anthropic keeps Opus 4.8 at the same price as Opus 4.7 and introduces a Fast Mode that runs the same model at roughly 2.5x speed at one-third of the standard cost, accessible in Claude Code via the /fast command. This gives teams more control over the trade-off between latency, spend, and outcome quality when orchestrating large-scale workflows.
Implications For Developers and Enterprise AI Strategy
The benchmark gains in Claude Opus 4.8 align with Anthropic’s positioning of the model for long, autonomous workflows. In Claude Code, Opus 4.8 is described as behaving like “an experienced engineer” that can keep context across long sessions, follow through in a repository, and coordinate parallel efforts, as seen in Anthropic’s demo of 16 Claude instances building a C compiler from scratch. For developers, higher scores on SWE-Bench Pro and OSWorld-Verified hint at smoother feature builds, refactors, and agentic tooling that rely less on constant supervision. For enterprises, the GDPval-AA lead suggests better performance on end-to-end business processes, from knowledge work automation to finance-specific agents, where Opus 4.8 tops Finance Agent v2 at 53.9%. The choice between top enterprise AI models is less about a single “best” system and more about matching benchmark strengths, efficiency profiles, and tooling ecosystems to specific workloads.





