What Google’s AI Overview Is—and Why Its Errors Matter
Google’s AI Overview is a Gemini-powered feature that sits at the top of search results and generates short, conversational answers that summarize information, instead of only listing links, so its spelling accuracy, factual reliability, and source coverage strongly influence what users see and trust in search. Since launch, AI Overviews have been caught hallucinating answers, from glue-on-pizza advice to basic spelling questions gone wrong. Because many people stop at the AI summary and are “less likely to click on links when an AI summary appears,” any mistake is amplified. When the answer that dominates the screen cannot spell simple words or reflect top-ranked sources, it raises concerns about how much users can rely on AI-generated search results and whether traditional signals of quality still protect people from misinformation.
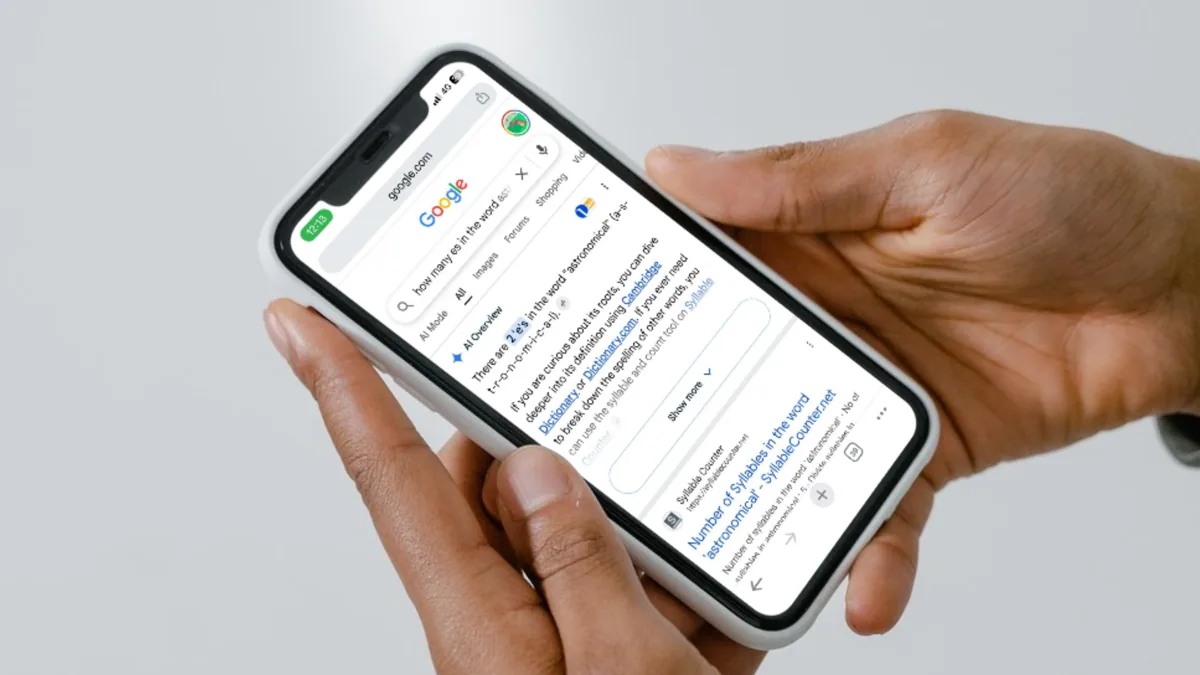
Spelling Failures Reveal How the System Reads Words
Recent tests show Google’s AI Overview still fails spelling questions it should breeze through. Asked “How many e’s in the word astronomical?”, it confidently replied that there are two, even offering a mangled version of the word: “a-s-t-r-e-n-o-m-i-c-a-e-l.” Users report similar mistakes for other multi-syllable words, suggesting a pattern rather than a one-off glitch. Google’s own Gemini has explained that it does not see words as sequences of letters but as tokens—blocks that represent whole words or meaningful parts of words. This token-based processing is efficient for understanding meaning but unreliable when users ask for letter-by-letter breakdowns. The result is a system that can discuss complex topics yet fails simple spelling tests, undermining confidence in Google AI Overview errors being rare edge cases rather than structural weaknesses in how the model represents text.
Brands Vanish Between Search Results and AI Answers
Spelling is not the only issue. A new SearchScore AI Visibility Study highlights a wider reliability gap between traditional search and AI-generated search results. The study found that “76.4% of brands scored below 40% in AI visibility across AI-powered search and recommendation platforms,” indicating that most brands rarely appear in AI answers. Even more striking, 52% of brands that rank on Google’s first page fail to appear in AI-generated recommendations at all. This means AI Overviews can omit more than half of the sources Google itself ranks highly. Users who rely on AI answers may never see well-optimized, authoritative sites that dominate traditional search. Instead, a small cluster of brands gains disproportionate exposure, raising concerns that AI search accuracy issues are not only about facts, but also about whose voices and products get visibility.

Why Training Data, Tokens, and Quality Control Fall Short
These Google AI mistakes point to deeper design and process problems. Large language models are trained on massive text datasets and learn patterns of words, not precise sequences of letters or fixed reference tables of facts. When users ask for spelling counts or structured recommendations, the model predicts plausible-looking text based on patterns, without a guaranteed step where it checks results against a dictionary or a curated knowledge base. Quality control appears focused on reducing outrageous hallucinations, not on edge cases such as spelling or ensuring coverage of top-ranked sites. Without stronger fact-checking, token-level spelling tools, and better integration between search rankings and AI answers, Google’s AI Overview will keep producing AI-generated search results that feel polished but remain fragile—correct enough to appear credible, yet unreliable enough to mislead users and marginalize many brands.





