
What Claude Fable 5 Is and Why It Matters
Claude Fable 5 is Anthropic’s first publicly available Mythos-class AI model designed for long, complex coding and analytical tasks, delivering higher real-world performance than previous Claude models while introducing clear tradeoffs in cost, speed, and security behavior. Built on the same underlying weights as Mythos 5, Fable 5 is wrapped in classifiers that detect high‑risk requests and route them to Claude Opus 4.8 for safer handling. It scores 80.3% on SWE-Bench Pro against Opus 4.8’s 69.2%, and exceeds 90% on Hex’s long analytical benchmark, signaling a measurable jump in sustained reasoning. At the same time, Anthropic prices Fable 5 at USD 10 (approx. RM46) per million input tokens and USD 50 (approx. RM230) per million output tokens, exactly double Opus 4.8, so every experiment with the model is a conscious trade between raw capability and session budget.

Coding Performance Benchmark: From Ping Pong to 50M Lines
Claude Fable 5 performance in coding shows up both in small demos and industrial-scale work. In a simple browser ping pong game test, Fable 5 and Opus 4.8 produced functionally similar games from the same prompt, but Fable added a dark navy field, distinct paddle colors, and a clean score display, hinting at better layout and UI instincts. Third‑party tests from Genspark report stronger results for Fable 5 on UI design and game coding, and Anthropic says it can rebuild a web app’s source code from a screenshot. On the heavy end, Stripe reported that Fable 5 completed a codebase‑wide migration across a 50‑million‑line Ruby codebase in a single day, work they say would have taken a team over two months. These coding performance benchmarks highlight where Fable 5 outpaces both Opus 4.8 and GPT 5.5 on sustained software engineering.
Session Cost, Speed, and AI Model Tradeoffs
The Fable 5 vs Opus comparison is as much about economics as capability. Anthropic lists Fable 5 and Mythos 5 at USD 10 (approx. RM46) per million input tokens and USD 50 (approx. RM230) per million output tokens, roughly twice Opus 4.8’s USD 5 (approx. RM23) and USD 25 (approx. RM115). In a controlled ping pong game request, Fable 5 used 109,035 session credits versus Opus’s 81,225, even though the token counts were similar. That translated into fewer remaining messages in the same session, 13.9 for Fable 5 versus 18.7 for Opus 4.8. The interface on claude.ai makes this visible, warning that Fable “takes 2x the usage of Opus” and showing consumption per task. For teams planning long coding or research runs, these AI model tradeoffs mean deciding when Fable 5’s better reasoning is worth higher cost‑per‑session and potentially slower throughput.
Security Fallbacks and Their Impact on Consistency
One of Fable 5’s defining design choices is its security fallback. To keep Mythos‑class capabilities from being misused in cybersecurity or sensitive biology, Anthropic built classifiers that auto‑route any task that mentions those domains to Opus 4.8. In practice, that means a user can be in a high‑performing Fable 5 coding session, introduce a security‑related request, and suddenly experience older‑model behavior mid‑conversation. This protects against high‑risk outputs, but it also affects performance consistency because the same chat can switch models under the hood. According to RDWorld’s overview of Fable 5, the underlying Mythos 5 weights show strong life sciences performance, yet outside controlled programs such as Project Glasswing, public users meet Opus 4.8 whenever they cross certain safety thresholds. Developers who rely on repeatable timing and quality need to factor in these silent fallbacks when designing workflows or benchmarks.
How Fable 5 Compares to Opus 4.8 and GPT 5.5
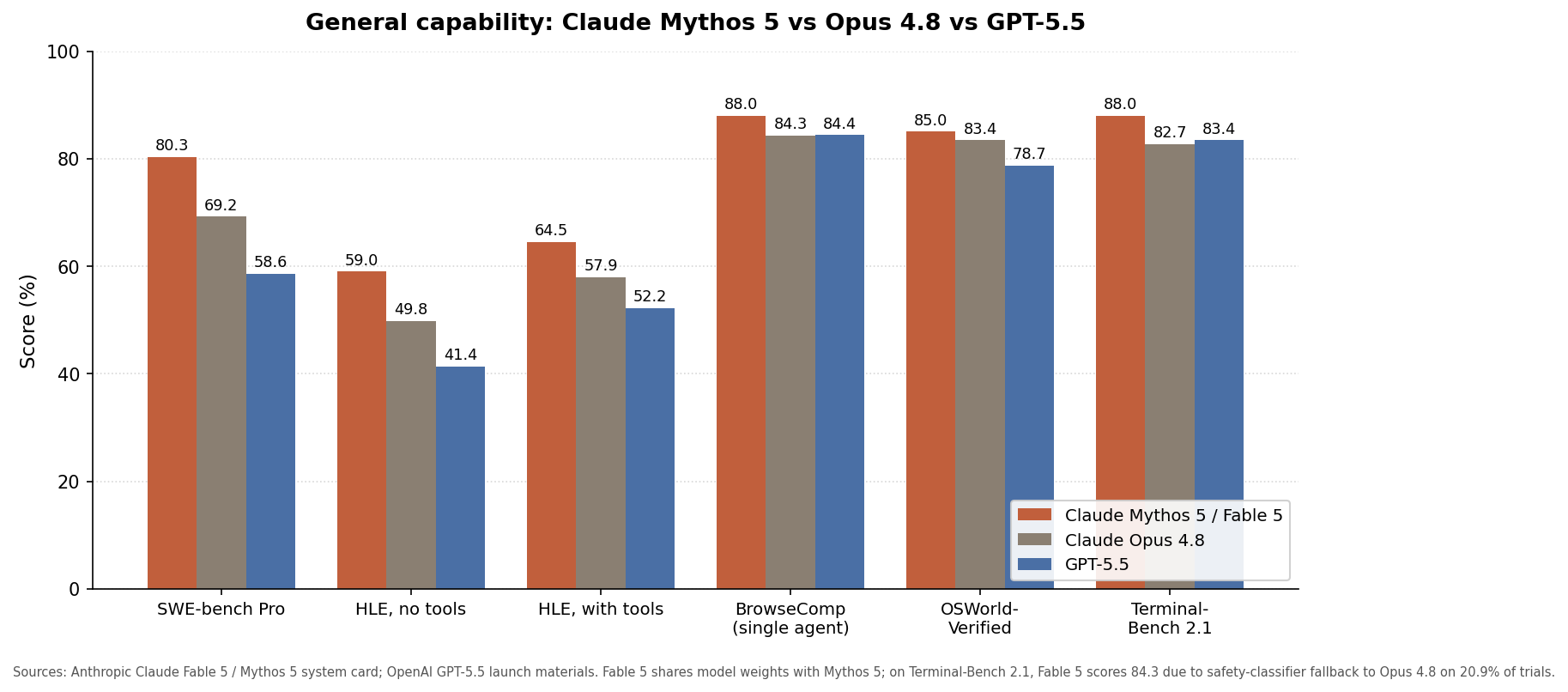
Direct comparisons place Claude Fable 5 at the front of current general‑purpose models for coding and analysis. On Artificial Analysis’s Intelligence Index, Fable 5 scores 65, ahead of GPT 5.5 at 60 and Gemini 3.1 Pro Preview at 57, while Opus 4.8 sits behind both. Hebbia’s finance benchmark and tests by IMC point to stronger document‑based reasoning and chart interpretation, and Physical Superintelligence described it as the strongest model it has tested on frontier physics research while using a third of the reasoning tokens. At the same time, Fable 5’s higher price, security fallback to Opus 4.8, and noticeable session drain mean it is not a universal replacement. For long, complex coding performance benchmarks, app‑scale refactors, and multi‑step analysis, Fable 5 is where you go for maximum headroom, while Opus 4.8 and GPT 5.5 remain better fits for lighter, cost‑sensitive workloads.





