
What Claude Opus 4.8 Effort Control Is and How It Works
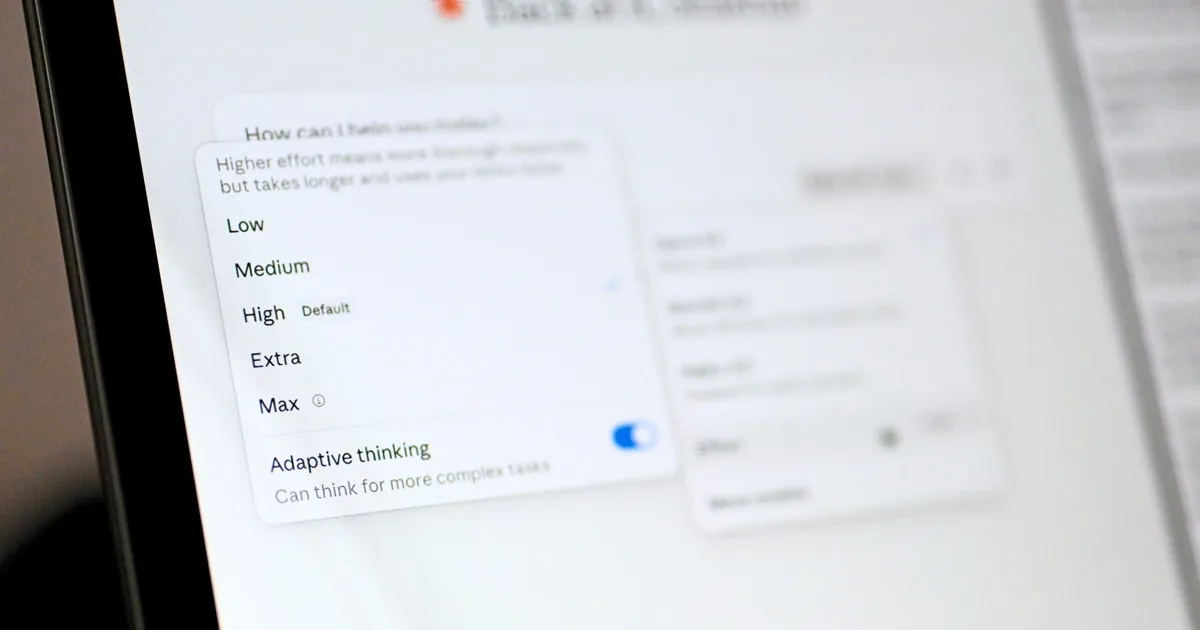
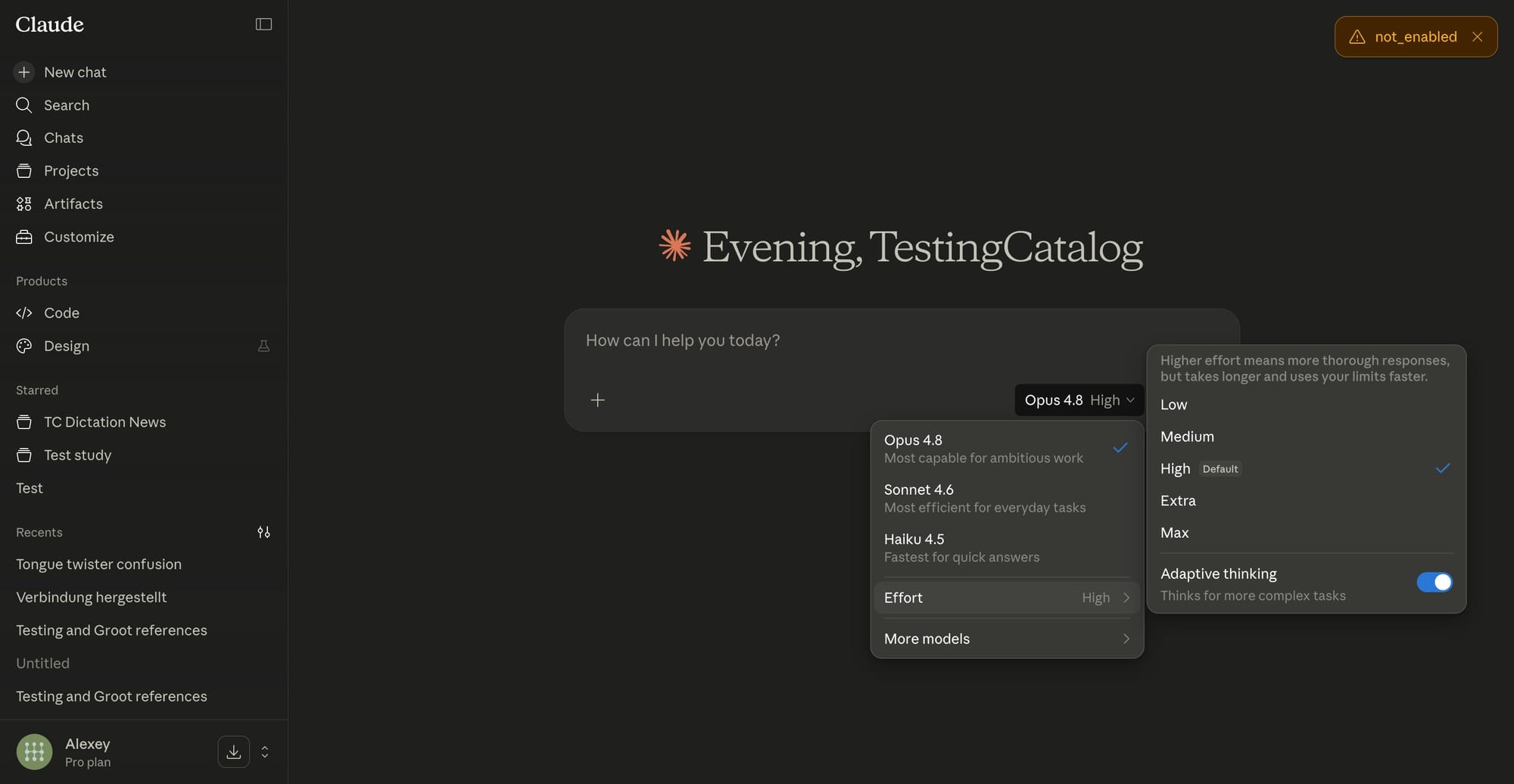
Claude Opus 4.8 effort control is a feature that lets users choose how much reasoning and validation the model performs before responding, trading off speed and cost against depth and accuracy on a per-task basis. Instead of Claude deciding how hard to think, a new slider sits next to the model selector on claude.ai, exposing five effort levels: Low, Medium, High (default), Extra, and Max. Low effort favors fast, lightweight replies that are well suited to short answers, email drafts, and quick summaries where AI reasoning speed vs accuracy tilts toward speed. High, Extra, and Max instruct the model to spend more time planning, exploring alternatives, and checking its own work before answering. These higher levels consume rate limits faster but are better for complex analysis, multi-step problem solving, and higher-stakes decisions where accuracy matters. Effort control is available to all Claude Opus 4.8 users across consumer and enterprise plans.

Fast Mode, Pricing, and the Speed–Accuracy Trade-Off
Alongside the new selector, Claude Opus 4.8 introduces a dedicated fast mode that targets users who prioritize low latency and lower bills over exhaustive reasoning. Anthropic says fast mode runs the same core model “at roughly 2.5x the speed, and we’ve made it three times cheaper than before.” For developers, Claude fast mode pricing is especially relevant when building high-traffic apps, streaming chatbots, or real-time coding assistants that must respond in seconds. In these cases, choosing Low effort plus fast mode can dramatically cut response times and operational costs per request. For analytical workloads, teams can stay on standard mode and turn effort up to High or Max when quality is more valuable than speed. Because effort settings and fast mode are controlled independently, product teams can tune AI reasoning speed vs accuracy differently for each feature or endpoint, rather than locking into a single profile.
Coding Model Improvements and Safer Autonomy
Opus 4.8 is not only about knobs and sliders; the underlying model shows clear coding model improvements and reliability gains. Anthropic reports that Claude Opus 4.8 is nearly four times less likely than Opus 4.7 to miss defects in the code it generates, which means fewer silent failures in automated refactors and pull requests. Benchmark numbers support this: the model reaches 69.2% on agentic coding tasks and 74.6% on Terminal Bench 2.1. It also scores 83.4% on OS World Verified for agentic computer use and 53.9% on Finance Agent v2 for financial analysis, indicating stronger tool-using and autonomous task execution. Early testers note more cautious judgment, with the model more likely to admit uncertainty and less likely to make unsupported claims. For developers and enterprises, this makes higher-effort modes attractive when running unsupervised test generation, complex migrations, or legal and financial workflows where undetected mistakes are costly.
Dynamic Workflows and Agentic Use Cases for Teams
Effort control pairs with new dynamic workflows in Claude Code to support longer-running, semi-autonomous tasks. In research preview for Enterprise, Team, and Max plans, dynamic workflows let Claude Opus 4.8 plan large jobs, spin up hundreds of parallel sub-agents in one session, and verify outputs before returning results. Anthropic describes scenarios like large-scale codebase migrations spanning hundreds of thousands of lines, where Claude coordinates analysis, edits, and validation against an existing test suite. Higher effort levels are well suited here: Extra or Max give sub-agents more room to explore, refactor, and self-check. Meanwhile, updates to the Messages API allow developers to insert system messages mid-task, changing permissions, token budgets, or environment context without breaking prompt caching. Together, these changes position Opus 4.8 as a better fit for agentic pipelines—such as CI bots, data clean-up jobs, and research assistants that run unattended for extended periods.
Practical Effort Strategies for Developers and Enterprises
For product teams, the key question is how to apply Claude Opus 4.8 effort control across different use cases. A common pattern is to default to Medium or High for everyday knowledge work, then downgrade to Low for non-critical tasks like quick drafting or internal questions where cost and speed dominate. Customer-facing support flows might use Low effort for simple FAQs, escalating to High when issues involve billing, compliance, or multi-step troubleshooting. In engineering workflows, Low plus fast mode works well for exploratory coding, while Max effort is reserved for production-critical refactors and security-sensitive reviews that benefit from deeper code defect detection. Enterprises building agentic systems on Claude Work or Claude Code can start runs at Medium, then dynamically increase effort for tricky files or ambiguous data. Because the feature is available across Anthropic’s platform and the Microsoft Foundry integration, these patterns can be applied consistently across web, API, and IDE tools.





