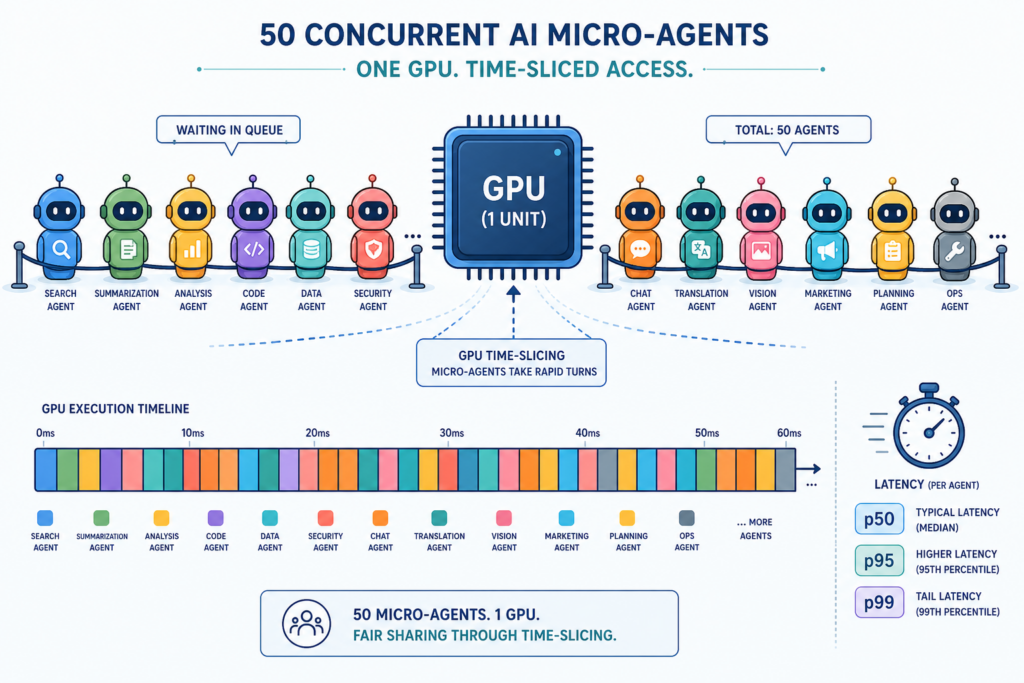
Redundant Context Recomputation: The Hidden Tax on Enterprise LLMs
Redundant context recomputation in LLMs is the repeated, bit-for-bit reprocessing of the same prompt or document across queries or agents, even when the model has already computed the exact key–value (KV) state needed to answer those requests, and it is the single largest recurring cost in many enterprise AI deployments because it forces GPUs to redo expensive dense attention work instead of reusing previously prefetched memory. In a typical workflow, every question about a long report triggers a full prefill pass from token one, so ten queries over a 100-page document can mean processing the equivalent of a thousand pages of identical content. This prefill phase dominates time-to-first-token and drives up GPU utilization without improving accuracy. Mainstream serving stacks are designed for independent prompts, not shared analytical graphs, so they treat each request as a stateless session, discarding KV state that could have powered many follow-on tasks and multi-agent LLM pipelines.
Taliesin: A Memory Engine That Remembers So GPUs Do Less
Corbenic AI’s Taliesin targets this waste by saving and restoring LLM memory instead of recomputing it. When a model prefill pass populates the KV cache for a long context, Taliesin captures that state and can reload it later, byte-identical, on the same or a different server. Corbenic reports that on a $0.69-per-hour graphics card, long-context tests that took over two minutes from scratch were restored in under seven seconds, yielding a 21× speedup with no loss of accuracy. In a relay between an Ampere A6000 and an Ada Lovelace RTX 4090, Taliesin moved AI memory across GPU generations and produced 64 of 64 identical output tokens, backed by SHA-256 hashes for public verification. For enterprises, this kind of memory engine turns repetitive document-prefill work into a one-time cost that can be reused across sessions, teams, and workloads, improving LLM inference optimization and enterprise AI efficiency without changing model weights.

KV Snapshot Sharing: Prefill Once, Fan Out to Many Agents
While Taliesin focuses on cross-session memory reuse, SwarmKV shows how KV snapshot sharing optimizes multi-agent LLM pipelines inside a single workload. In default stacks like vanilla llama.cpp, each analytical agent rereads the same document, rebuilding the KV cache from scratch. SwarmKV replaces that with a snapshot-based architecture: run prefill once, serialize the KV cache with llama_state_get_data, copy it into per-branch host buffers using memcpy, then restore it for each agent with llama_state_seq_set_data before decoding. On a seven-year-old GTX 1080, this C++ orchestrator made a two-agent pipeline about 1.95× faster end to end and cut the second agent’s activation latency by around 52×, removing 8,685 ms of redundant compute. Because prefill cost grows with prompt length while KV state transfer scales linearly, moving bytes is far cheaper than recomputing attention. This pattern—“compute once, fan out”—matches decades of telecom broadcast engineering and now underpins efficient KV cache sharing in agentic LLM inference.
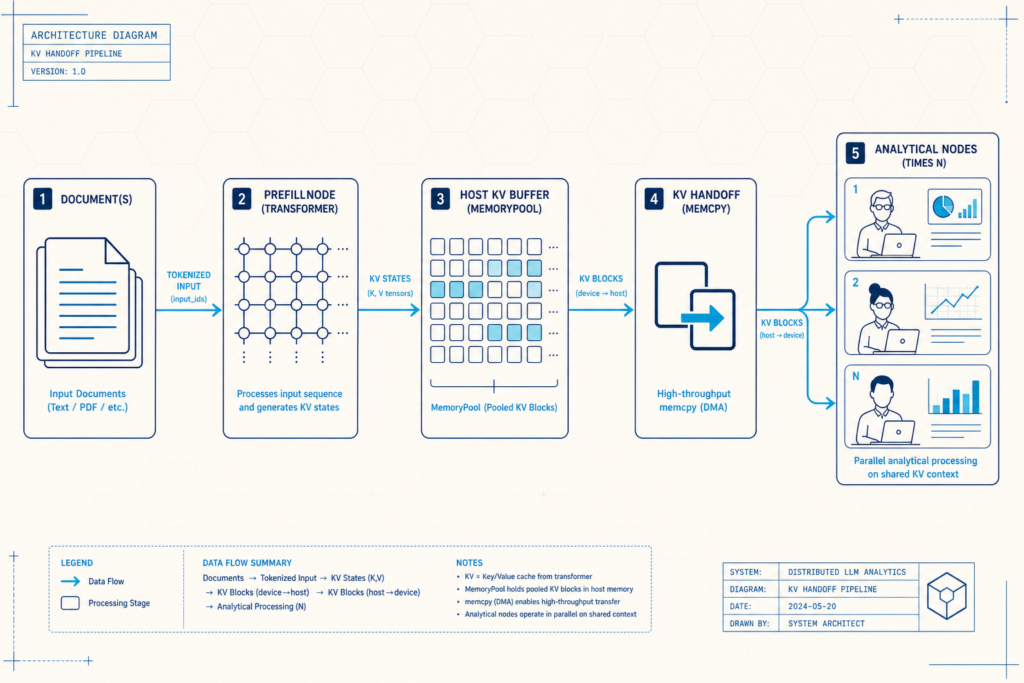
From Systems Hack to Enterprise Strategy: Cutting Context Recomputation Costs
The shared lesson from Taliesin and SwarmKV is that the largest LLM inference optimization opportunities are often systems-level, not algorithmic. Both approaches stop treating LLMs as stateless black boxes and instead treat the KV cache as reusable infrastructure. Memory engines provide durable, cryptographically verifiable snapshots that can move across machines and GPU generations, while snapshot-based C++ runtimes focus on intra-pipeline reuse with copy-on-fork semantics. For enterprises running fleets of long-context models and multi-agent LLM pipelines, these techniques shift the cost structure: the dense prefill becomes a shared asset, not a per-request tax. This reduces context recomputation costs, lowers GPU hours, and shortens time-to-first-token without retraining models or changing user prompts. As future work adds time-slicing, GPU-based retrieval, and persistent agent state, the same design principle will likely hold: broadcast shared state once, let many consumers reuse it, and treat any repeated prefill as a bug, not a feature.