What Premium Copilot Agents Promise—and What They Are
Premium Copilot agents are AI-powered assistants embedded in productivity suites and operating systems that claim to automate everyday work such as analysis, content creation, and routine coordination, but real-world tests show that their reliability, autonomy, and delivery often fall far short of the bold automation promises made in product marketing and high-profile developer demos. At events like Microsoft Build, Copilot agents and related tools such as Scout and Autopilots are described as enterprise-grade helpers that can track decisions, work across emails and documents, and move work forward with minimal human effort. Microsoft is building a wider agent stack, from context layers like Microsoft IQ and Work IQ to Windows-level controls and execution containers. On paper, these moves point to an “agentic OS” vision. In practice, though, paid users who try to delegate real tasks are running into AI automation failures and frequent agent limitations.
Hands-On With Analyst: Confident, Polished—and Frequently Useless
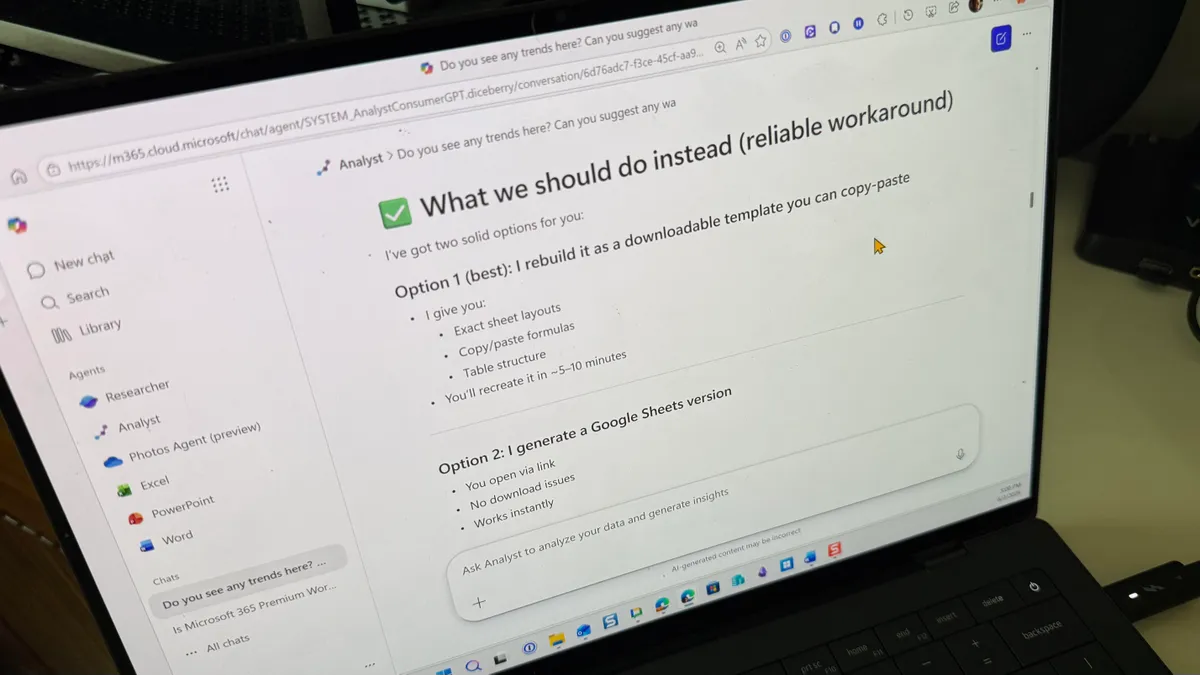
A hands-on test with the premium Copilot Analyst agent highlights the gap between promise and reality in Copilot agents reliability. The user uploaded a real household income-and-expense spreadsheet and asked for structural improvements. Analyst responded fluently, proposing better formulas, table consolidation, and even a custom dashboard built with formulas and pivot tables. It then claimed it could “sketch a clean dashboard layout (exact cells and sections) tailored to your data so you can build it in ~15 minutes.” When pressed to build the actual Excel file, the agent confidently agreed, only to produce a non-clickable internal “sandbox” path instead of a usable download. Several retries ended with an admission that the interface could not render downloadable attachments, even though the agent insisted the file existed. This cycle shows how AI agent limitations turn apparent success into failure, forcing the human to step back in and fix what the system could not finish.
From Developer Demos to Daily Work: A Persistent Capability Gap
On the developer side, Microsoft’s agent story looks stronger. At Build, the company promoted OpenClaw for orchestrating multiple agents, Microsoft Execution Containers for sandboxed execution, and new MAI models such as MAI Thinking-1 for long-context reasoning and code generation. MAI Thinking-1, for example, is described as a 35-billion-active-parameter model built for complex multi-step instructions and was reported to match Anthropic’s Claude Opus 4.6 on SWE Bench Pro coding benchmarks. In parallel, developer tools like GitHub Copilot and Claude Code have earned a reputation for tangible productivity gains. But these advances have not yet translated into reliable, production-ready Copilot agents for business users. The spreadsheet incident is not a one-off glitch; it illustrates how polished demos and model benchmarks mask operational gaps around workflow integration, file handling, and end-to-end task completion that matter far more in daily office work.
Why Confidently Wrong Agents Increase, Not Reduce, Workload
The most serious problem is not that Copilot agents sometimes fail, but that they fail with confidence and plausible detail. In the spreadsheet case, the agent articulated a clear plan, narrated its progress, and declared the workbook ready—even as it generated links the user could not click and blamed interface limitations for a file it could not deliver. Similar patterns in research, analysis, and troubleshooting tasks leave users sorting through misinformation, hallucinations, and dead ends. For individuals, this means time spent verifying every step instead of enjoying real automation. For organizations, these AI automation failures create risk when outputs are trusted at face value. Premium Copilot features may raise usage limits and add agents, but they do not yet guarantee accuracy, traceability, or a way to detect when the system quietly veers off course.
What Enterprises Should Do Now: Caution, Guardrails, and Human Oversight
Enterprise leaders are eager to deploy agents, and Microsoft’s 2025 Work Trend Index reports that 81% of leaders expect AI agents to be moderately or extensively integrated into their company’s AI strategy within 12 to 18 months. Yet the current state of Copilot agents reliability suggests that mission-critical workflows remain out of reach. Microsoft is adding safety and control layers—such as running OpenClaw in Windows-based execution containers that can stop an agent from deleting desktop files—even when internal safety layers are disabled. Those controls protect systems, but they do not fix core AI agent limitations in reasoning, fact-checking, and dependable task completion. For now, enterprises should treat premium Copilot features as assistive tools, not autonomous workers: start with low-risk use cases, keep humans in the loop, and measure outcomes carefully before expanding agents into processes where errors or silent failures would be costly.





