
CUDA 13.3 Release: A Focus on Easier High-Performance GPU Development
The CUDA 13.3 release is aimed squarely at making GPU kernel development faster to write and easier to optimize. NVIDIA is extending its CUDA Tile programming model to C++, giving developers a higher-level way to describe compute while still targeting cutting-edge hardware features. At the same time, the new CompileIQ framework turns compiler configuration into a tunable parameter, using AI-driven search to uncover better performance than generic compiler heuristics often deliver. The release also solidifies the CUDA Python ecosystem and upgrades the toolchain with official C++23 support, broader tensor interoperability, and refreshed math libraries and profiling tools. Together, these updates address a familiar pain point in GPU work: squeezing the last few percent of performance out of a small set of hot kernels without drowning in low-level details or trial-and-error compiler flag tuning.

Tile Programming in C++: A Higher-Level Model for GPU Kernel Development
CUDA Tile programming C++ brings tile-based abstractions directly into large, existing C++ GPU codebases, changing how developers think about GPU kernel development. Instead of manually orchestrating single instruction, multiple threads (SIMT) execution—choosing block sizes, managing per-thread work, and hand-tuning memory movement—developers express computation over tiles of multidimensional arrays. Kernels operate on these tiles, while CUDA Tile automatically handles parallelism within blocks, asynchrony, data movement, and other low-level concerns. Built on the CUDA Tile IR specification, this model is portable across NVIDIA GPU architectures and automatically taps into advanced hardware features like tensor cores, shared memory, and tensor memory accelerators without requiring explicit targeting. For developers, this means less boilerplate control code, more focus on numerical algorithms, and a clearer path to writing high-performance kernels that remain maintainable as hardware evolves.
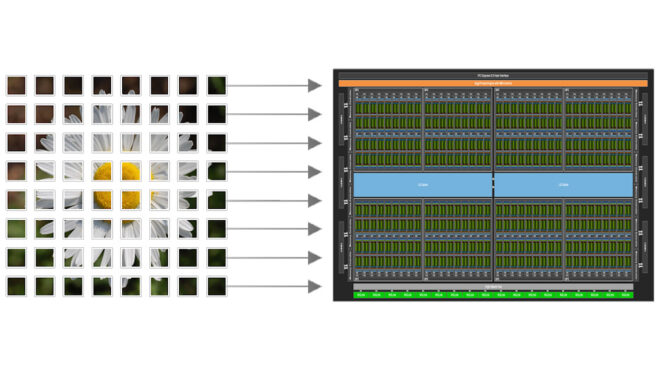
How Tile-Based C++ Kernels Simplify Performance and Portability
Tile programming C++ reframes GPU kernel design around data layout and mathematical intent, rather than thread bookkeeping. In the tile model, multidimensional arrays are the primary storage, tiles are subregions of those arrays, and kernels are functions that operate on tiles in parallel across blocks. Within each block, CUDA Tile C++ takes responsibility for mapping work to threads, scheduling asynchronous operations, and optimizing memory accesses. This approach reduces off-by-one errors and launch-configuration guesswork common in hand-written SIMT code. At the same time, because the implementation is built on a portable Tile IR, the same kernel source can adapt to different NVIDIA GPU generations while automatically leveraging new features where available. For teams maintaining large HPC or AI codebases, this helps decouple algorithmic code from hardware-specific tuning, enabling more aggressive refactoring and performance improvements with less risk of regressions.
CompileIQ Compiler Auto-Tuning: Turning the Compiler into a Performance Knob
CompileIQ in CUDA 13.3 introduces compiler auto-tuning as a first-class tool for performance engineering. Traditionally, NVIDIA GPU compilers rely on general-purpose heuristics for register allocation, instruction scheduling, loop unrolling, and other decisions, aiming for good performance across many workloads. However, the most critical kernels in modern applications—such as GEMMs in linear layers and attention blocks in large language model inference—dominate runtime, so even small improvements matter. CompileIQ treats the compiler as a tunable system, using evolutionary and genetic algorithms to explore different configurations and discover better-performing options for specific kernels. NVIDIA reports up to a 15% speedup on key kernels like GEMM and attention when using this framework. For teams already heavily optimized at the algorithmic level, compiler auto-tuning offers a new layer of performance gain without rewriting kernels from scratch.
CUDA Python 1.0 and Ecosystem Updates Round Out the Release
Beyond tile programming C++ and compiler auto-tuning, the CUDA 13.3 release strengthens the broader CUDA ecosystem. CUDA Python 1.0 marks a maturity milestone, committing to semantic versioning and clearer guarantees around API stability and deprecation paths. Core components like cuda.binding and cuda.core expose CUDA runtime and C APIs in a more Pythonic way, while supporting utilities such as cuda-pathfinder help locate installed CUDA components in Python environments. Additional features, including green contexts and process checkpointing, improve robustness for long-running workloads. On the C++ side, NVCC gains official C++23 support, CCCL expands tensor interoperability with DLPack and mdspan, and math libraries like cuBLAS, cuSPARSE, and cuSOLVER receive performance and capability updates. Combined with enhancements to Nsight profiling tools, these improvements help developers diagnose bottlenecks, iterate faster, and better exploit the new tile and auto-tuning capabilities introduced in CUDA 13.3.





