What Claude Opus 4.8 Is And Why Benchmarks Matter
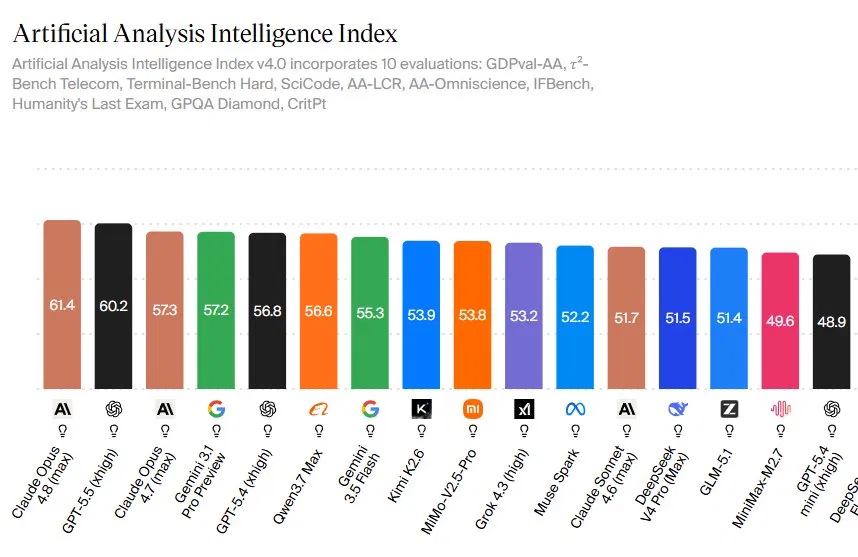
Claude Opus 4.8 is Anthropic’s latest flagship large language model, designed for long, autonomous work sessions, and evaluated on a wide range of coding, reasoning, and real-world task benchmarks to measure how it compares with rival AI systems. Artificial Analysis’ new Intelligence Index v4.0 puts Opus 4.8 at the top with a score of 61.4, ahead of GPT-5.5’s 60.2 and Opus 4.7’s 57.3. That index aggregates 10 demanding evaluations, from Humanity’s Last Exam for multidisciplinary reasoning to CritPt and GPQA Diamond for high-end question answering. The narrow headline gap hides a wider story: Opus 4.8 builds a lead by scoring slightly higher in category after category, rather than relying on a single standout test. For buyers and builders comparing AI model performance, this benchmark spread has turned into a new reference point for AI benchmark comparison and GPT-5.5 vs Claude debates.
Inside The Artificial Analysis Intelligence Index Lead
Artificial Analysis’ Intelligence Index is a composite snapshot of frontier AI capability, blending 10 diverse evaluations that stress different skills. Opus 4.8’s 61.4 score reflects strength across GDPval-AA, τ²-Bench Telecom, Terminal-Bench Hard, SciCode, AA-LCR, AA-Omniscience, IFBench, Humanity’s Last Exam, GPQA Diamond, and CritPt. One quotable data point from the index era: Anthropic’s flagship now leads the pack, while GPT-5.5 trails by 1.2 points and Gemini 3.1 Pro Preview sits at 57.2. The top two models have now separated from a tightly packed mid-tier of Qwen3.7 Max, Gemini 3.5 Flash, Kimi K2.6, and MiMo-V2.5-Pro, which cluster between 53 and 57. For practitioners, this means AI benchmark comparison is no longer about a single leaderboard; instead, rankings hinge on consistent performance across agentic coding, reasoning-heavy exams, and long-horizon tasks that capture how these systems behave under pressure.
GDPval-AA: Real-World Tasks Where Opus 4.8 Pulls Ahead
If the Intelligence Index shows breadth, GDPval-AA tests depth in real-world work. Developed by Artificial Analysis using the Stirrup harness, GDPval-AA simulates economically valuable tasks across 44 occupations and 9 industries using web and shell access. Claude Opus 4.8 debuts at the top of this benchmark with an Elo score of 1890, a 137-point jump over Opus 4.7 and a 121-point lead over GPT-5.5 in second place. That margin translates to an implied win rate of about 67 percent against GPT-5.5 xhigh in head-to-head comparisons, a decisive advantage rather than a statistical blip. These results echo Anthropic’s broader focus on agentic work: Artificial Analysis notes that Claude Code already accounts for around 4 percent of public GitHub commits, and Anthropic has shown 16 parallel Claude instances autonomously building a C compiler from scratch.
How Opus 4.8 Performs Across Coding, Reasoning, And Tools
Beyond GDPval-AA, Anthropic’s internal benchmarks highlight where Claude Opus 4.8 gains ground on GPT-5.5 and Opus 4.7. On SWE-Bench Pro for agentic coding, Opus 4.8 scores 69.2 percent, up from Opus 4.7’s 64.3 percent and well above GPT-5.5’s 58.6 percent and Gemini 3.1 Pro’s 54.2 percent. On Humanity’s Last Exam, it reaches 49.8 percent without tools and 57.9 percent with tools, leading all rivals. OSWorld-Verified shows similar strength in agentic computer use, where Opus 4.8 hits 83.4 percent versus GPT-5.5’s 78.7 percent and Gemini 3.1 Pro’s 76.2 percent. It also tops Finance Agent v2 at 53.9 percent for agentic financial analysis. The main exception is Terminal-Bench 2.1, where GPT-5.5 leads with 78.2 percent and Opus 4.8 sits at 74.6 percent, still ahead of its predecessor and Gemini.
Turn Efficiency, Fast Mode, And What This Means For Users
Performance gains arrive with a nuanced efficiency story. On GDPval-AA, Opus 4.8 uses about 15 percent fewer turns per task and 35 percent fewer output tokens than Opus 4.7, showing cleaner internal performance. Yet it still takes around 30 percent more turns than GPT-5.5 to reach its higher Elo, which matters for high-volume, cost-sensitive agentic workflows. On a score-versus-turns scatter plot, that leaves Opus 4.8 outside the ideal upper-left quadrant where GPT-5.5 sits closer. Anthropic counters this with product design: Opus 4.8 launches at the same price as Opus 4.7 and adds a Fast Mode that runs the same model about 2.5 times faster at one-third the standard cost. For teams comparing GPT-5.5 vs Claude Opus 4.8, the trade-off is clear: higher AI model performance and real-world win rates, offset by more turns but softened by a cheaper, faster configuration.





