From Model Quality to Token Economics
As enterprises move from experiments to production-scale AI agents, the conversation is shifting from raw model accuracy to operational cost. Two expenses dominate: GPU utilization and token spend. Traditional agent frameworks repeatedly reload context on every call, wasting compute cycles and inflating bills. Likewise, requests are often routed to expensive, overpowered models even when a lightweight model would suffice. This combination drives up both infrastructure and per-request inference costs, especially in long-running, multi-step tasks where context must persist across sessions. Infrastructure vendors and open-source projects are now targeting this “hidden tax” on agentic AI. Solutions such as MinIO’s MemKV and the OpenSquilla runtime focus on GPU utilization optimization, AI token cost reduction, and AI inference optimization through smarter handling of context memory cache and ML model routing. Together, they illustrate how architecture, not just bigger models, is becoming the key lever for sustainable AI deployments.

MemKV Turns Context into a Shared, Persistent Asset
MinIO’s MemKV attacks what it calls the AI “recompute tax” – the wasted GPU time spent rerunning calculations because context cannot be retained close to the hardware. By providing a petabyte-scale, flash-based context memory tier accessed over 800 GbE RDMA, MemKV lets GPUs reload prior context in microseconds instead of reconstructing it from scratch. Benchmarks published by MinIO highlight improvements in Time to First Token and Time Per Output Token, with MemKV delivering more than 95% better GPU utilization and around 50% lower cost per token. Architecturally, it enables stateless serving layers: session and agent state move into MemKV, so any GPU replica can resume a conversation mid-flight without sticky sessions. Context becomes durable, addressable state rather than “throwaway scratch,” aligning it more with database rows than transient cache entries and directly reducing structural drag in dense GPU clusters.
OpenSquilla’s Routing Stack Cuts Token Spend by Reusing Context
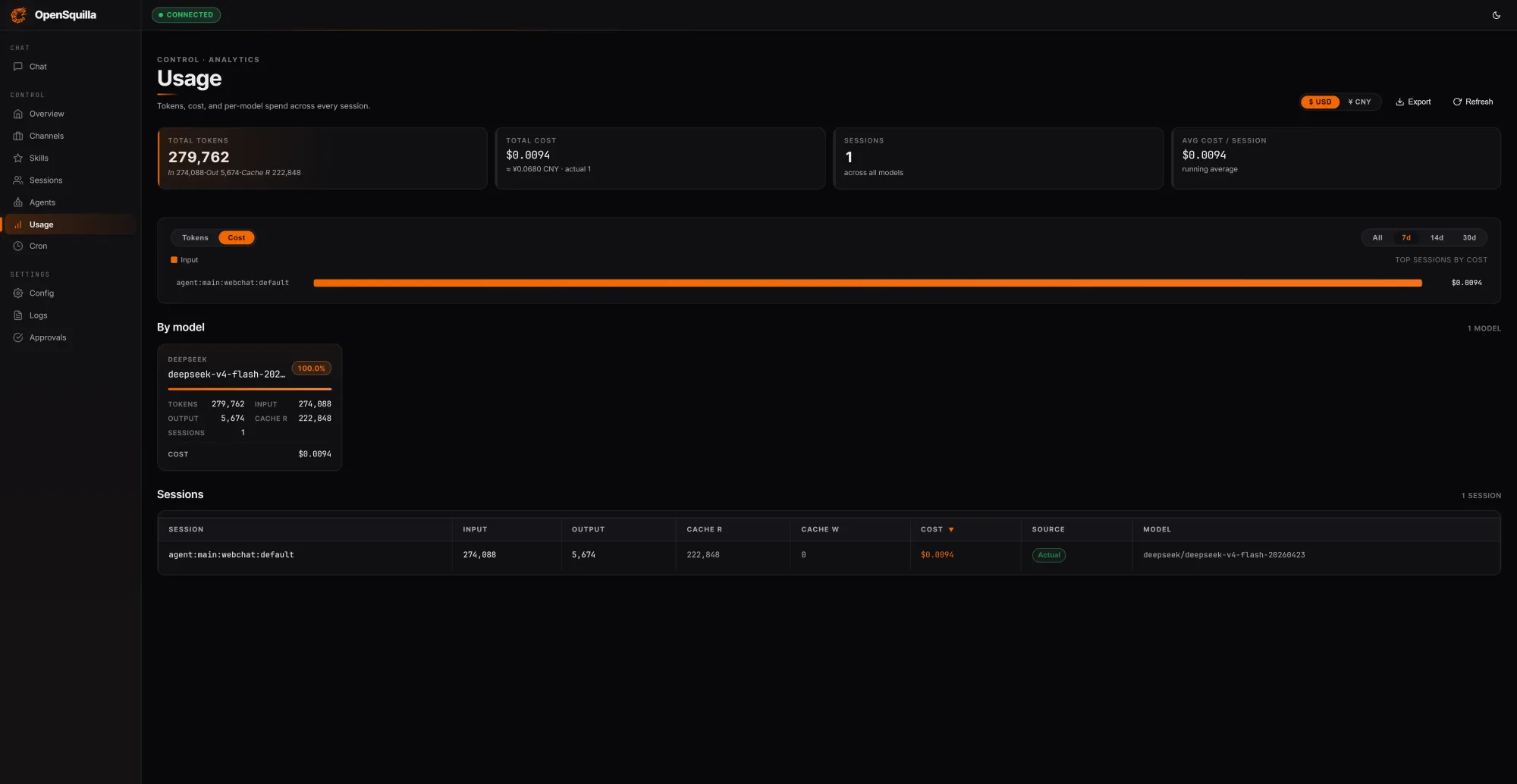
OpenSquilla approaches cost from the token side, starting from the observation that most agent runtimes overspend by reloading context and defaulting to heavyweight models. Its open-source, self-hostable agent runtime layers ML model routing on top of a rich context memory cache. In a local test session covering three prompts, OpenSquilla processed 279,762 tokens at a total session cost of USD 0.0094 (approx. RM0.044), with 222,848 tokens—about 80% of inputs—served from cache rather than recomputed. A routing classifier blends hand-crafted features like message length, presence of code blocks, and keyword patterns with embedding-based semantics to score request complexity. Simple tasks route to cheaper models, and deep reasoning is disabled for lightweight queries, avoiding unnecessary chain-of-thought expansions. Skills load on demand instead of being stuffed into every context window. According to OpenSquilla’s benchmarks, these combined strategies yield a 60–80% reduction in token spend versus a flat, single-model setup.
Four-Tier Memory and Sandbox Isolation for Safer, Smarter Agents
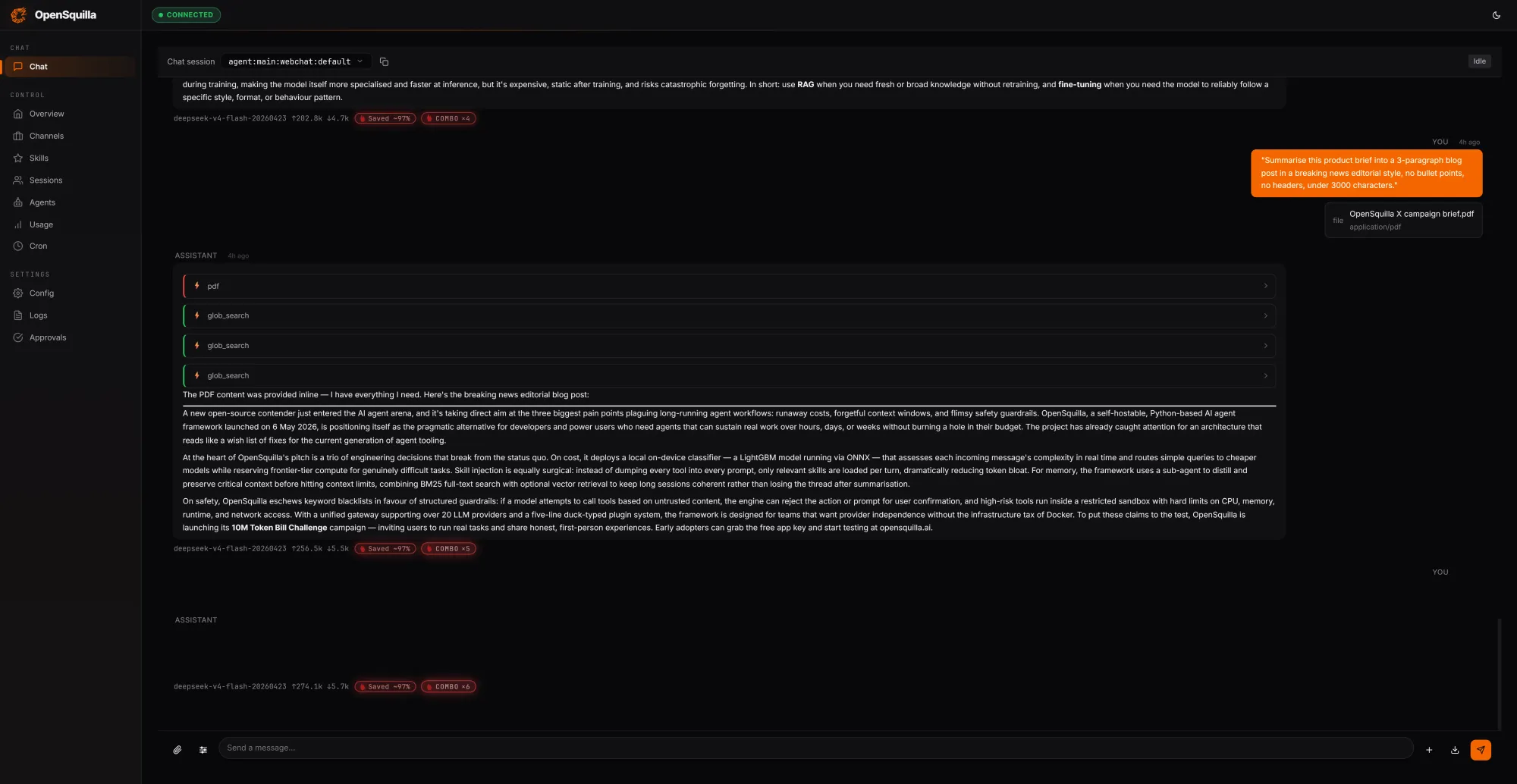
Beyond routing, OpenSquilla introduces a four-tier cognitive memory architecture inspired by human memory. Working memory holds the active task, episodic memory tracks experiences and causal links across sessions, semantic memory stores long-lived facts and rules, and raw memory serves as an audit trail and retraining corpus. Retrieval combines vector-based semantic search with BM25 full-text search running in parallel, with embeddings generated locally via ONNX inference to keep data on-device. Hot memory promotion surfaces frequently recalled items, while temporal decay lets stale information fade unless explicitly marked evergreen; a daily consolidation pass restructures memories into denser knowledge. Security is addressed through syscall-level sandbox isolation in production Linux environments, limiting the blast radius of agent actions. By marrying context memory cache strategies with robust isolation, OpenSquilla offers both performance and security improvements, particularly important for enterprises running long-horizon agents in sensitive environments.
Open-Source and Infrastructure Innovation Democratize Cost Optimization
Taken together, MemKV and OpenSquilla illustrate how AI infrastructure and open-source tooling are converging to tame the cost of agentic AI. MemKV minimizes recompute tax by turning context into a durable, shareable resource across GPU clusters, unlocking GPU utilization optimization at scale. OpenSquilla pushes AI token cost reduction through ML model routing, intelligent memory reuse, and an architecture that separates working, episodic, semantic, and raw memory for more efficient AI inference optimization. Both approaches encourage developers to treat context as first-class state rather than disposable data, enabling finer-grained control over what is stored, shared, or discarded. Crucially, OpenSquilla’s self-hostable and open-source model makes these techniques accessible beyond hyperscalers, giving enterprise AI teams practical tools to control token and compute costs. As agent workloads grow more complex, such context-aware, memory-centric designs are set to become the default rather than the exception.