From Market Squeeze to In-House Bet
Cursor’s launch of Composer 2.5 marks a strategic pivot from relying on third‑party models toward owning its core coding agent. After being overshadowed by Claude Code and Anthropic’s rapidly expanding enterprise footprint, Cursor has faced a squeeze: it was effectively competing with a vendor it also paid for inference, while Claude undercut or matched it on price. Yet Cursor’s own scale is still substantial, with billions of accepted code lines per day and widespread enterprise adoption. The question now is whether Composer 2.5 can reset the narrative. Rather than chasing raw model size, Cursor positions this release as an agentic upgrade: a smarter, more reliable coding assistant that can sustain long, complex refactors. In a market increasingly focused on autonomous coding tools instead of traditional IDE features, Composer 2.5 is Cursor’s attempt to prove that targeted tuning and ownership of the stack can restore its competitive edge on both capability and cost.

Targeted Reinforcement Learning and 25x Synthetic Training
Composer 2.5 keeps Moonshot’s Kimi K2.5 base but dramatically extends post‑training, betting that smarter fine‑tuning beats swapping foundations. The model was trained on 25 times more synthetic tasks than its predecessor, exposing it to richer, more varied coding scenarios before touching real developer workloads. A key innovation is targeted reinforcement learning with localized textual feedback: instead of a single reward at the end of a long run, Cursor injects corrections precisely where the model missteps, such as a faulty tool call. Those localized hints then act as teacher signals, sharpening credit assignment for complex, multi‑step jobs. Cursor also emphasizes improved behavioral calibration, teaching the model to follow nuanced instructions, maintain consistent coding style, and communicate in a developer‑friendly way. Together, these changes are designed to push planning depth, tool use reliability, and long‑horizon reasoning without changing the underlying model family or sacrificing latency.
Benchmarking Against Opus 4.7 and Other Developer Tools
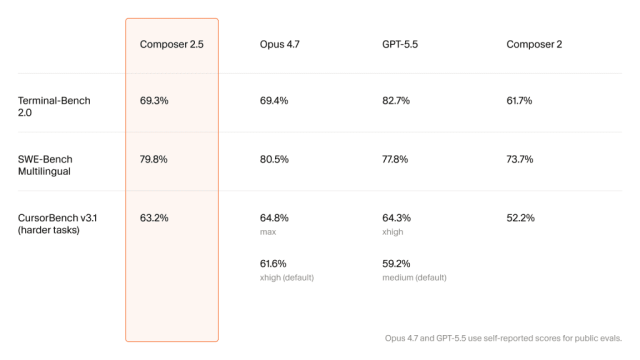
On headline developer tool benchmarks, Cursor Composer 2.5 positions itself squarely against premium rivals. On SWE‑Bench Multilingual it scores 79.8%, landing just behind Opus 4.7’s 80.5% and ahead of GPT‑5.5’s 77.8%. On Terminal‑Bench 2.0, it closely tracks Opus 4.7 with 69.3% versus 69.4%, while GPT‑5.5 pulls ahead. Cursor’s own harder‑task benchmark, CursorBench v3.1, paints a nuanced picture: Composer 2.5 scores 63.2%, compared to Opus 4.7’s 64.8% at its max setting, but above Opus 4.7’s default xhigh setting at 61.6% and GPT‑5.5’s 59.2%. These results suggest that for multi‑step, agent‑style coding tasks, Composer 2.5 can match or exceed some default configurations of top‑tier models. However, Cursor itself stresses that live multi‑file refactors, repeated tool calls, and repository‑scale edits remain the ultimate test of whether these benchmark wins translate into real‑world developer productivity.
AI Coding Cost Efficiency: Up to 10x Gains
Where Composer 2.5 most aggressively differentiates itself is AI coding cost efficiency. Standard pricing is set at USD 0.50 (approx. RM2.30) per million input tokens and USD 2.50 (approx. RM11.50) per million output tokens, with a faster default variant priced at USD 3.00 (approx. RM13.80) input and USD 15.00 (approx. RM69.00) output. Cursor highlights up to 10x better cost efficiency on complex coding tasks versus comparable frontier models, backed by an effort‑curve chart showing Composer 2.5 achieving around 63% on CursorBench at under USD 1.00 (approx. RM4.60) per task. At that point, competing models like Opus 4.7 and GPT‑5.5 reportedly cost several dollars more for similar or worse results. For teams running large volumes of long‑running coding jobs, these economics could significantly reduce monthly AI spend while keeping capability in the same performance band.
A Claude Alternative for Cost-Conscious Developers
Composer 2.5 is clearly positioned as a Claude alternative on both capability and pricing, particularly for developers sensitive to AI usage bills. Claude Code’s growth and Anthropic’s structural pricing advantage forced Cursor to respond with something more than UI polish, and Composer 2.5 is that response: an in‑house agent trained heavily on synthetic tasks, tuned for long‑horizon reliability, and priced aggressively. For buyers comparing developer tool benchmarks, Composer 2.5 now offers performance in the same conversation as Opus 4.7, but at significantly lower per‑token costs. The remaining questions are practical: How does it behave over multi‑hour refactors? Does it maintain project‑wide consistency and safe tool use? With immediate availability inside Cursor and a larger, more compute‑intensive model already in the works, Cursor is signaling that it intends to compete not just on experience, but on the hard metrics of capability, affordability, and sustained task performance.