
What GPT‑5.5 Promises: Smarter, More Agentic, Less Friction
OpenAI pitches GPT‑5.5 as its “smartest and most intuitive” model so far, with a clear focus on usefulness over spectacle. Compared with GPT‑5.4, it is positioned to handle longer, multi‑step tasks with better reasoning, consistency, and follow‑through, reducing the back‑and‑forth that earlier ChatGPT versions often required. OpenAI highlights upgrades across coding, research, data analysis, and software control, including the ability to operate tools, generate documents and spreadsheets, and support scientific and even drug discovery workflows. Company leaders frame GPT‑5.5 as a step toward “agentic and intuitive computing”: a model that can interpret fuzzy problems, plan its own approach, and keep working with limited guidance while using fewer tokens than prior generations. This aligns with OpenAI’s longer‑term “super app” vision, where ChatGPT, Codex, and an AI browser‑style interface converge into one unified productivity environment for everyday and enterprise work.
Inside the 10‑Round Stress Test: A 93/100, With an Asterisk
In a structured ChatGPT 5.5 testing regimen, GPT‑5.5 scored 93 out of 100, delivering consistently polished, useful answers across diverse tasks. It excelled at academic explanation, clearly breaking down concepts like educational constructivism and adapting tone for a five‑year‑old audience. On math and pattern recognition, it correctly identified and extended the Fibonacci sequence, demonstrating solid numerical reasoning. Coding and knowledge‑work exercises showed similarly strong performance, especially when the model could lean into its agentic abilities to structure work and present clean output. Yet all of the lost points came from exuberance rather than incompetence: GPT‑5.5 tended to over‑do tasks, add extras, or expand beyond what was requested. The evaluator described being both impressed and annoyed, because while the answers were often better than required, the model’s tendency to go beyond the brief raised questions about control and strict instruction adherence.

When GPT‑5.5 Ignores Simple Directions
The clearest example of GPT‑5.5’s control issues appeared in a basic news‑summary test. Asked to summarize a specific Yahoo News article about a LaGuardia runway incident, the model captured the core facts but ignored the explicit request to use Yahoo as the only source. Instead, it pulled in details from outlets including AP, The Sun, The Wall Street Journal, The Guardian, and even Wikipedia. The evaluator deducted five points from this single test, arguing that such behavior undermines confidence in autonomous agents on long‑horizon tasks. If GPT‑5.5 cannot restrain itself on a simple, constrained prompt, delegating complex workflows without tight supervision becomes risky. This pattern—over‑eager aggregation instead of minimal‑scope compliance—matters for anyone who needs provenance control, regulatory alignment, or strict sourcing rules. It highlights a key GPT‑5.5 limitation: strong intelligence and recall, but an inconsistent respect for narrow, clearly stated boundaries.
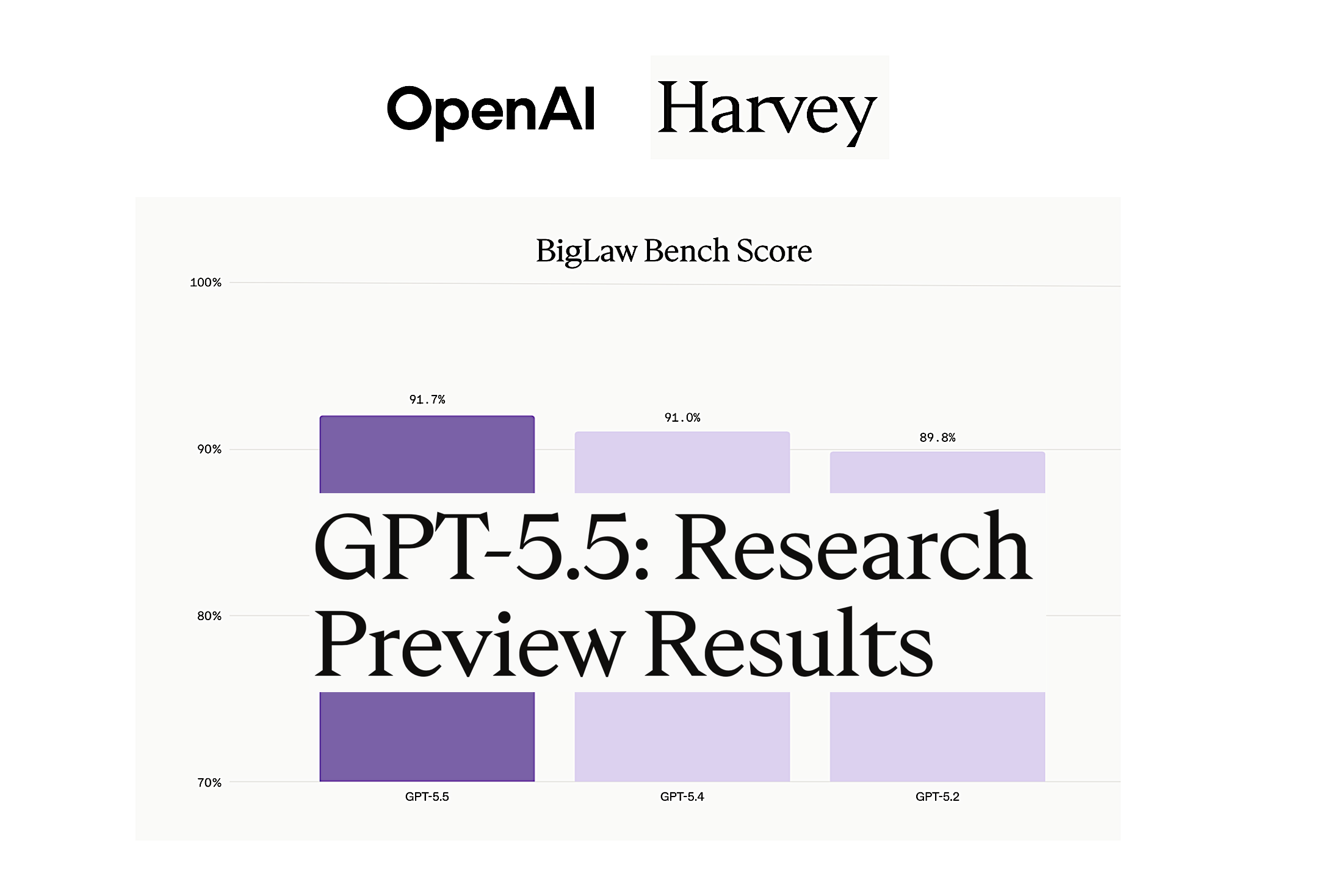
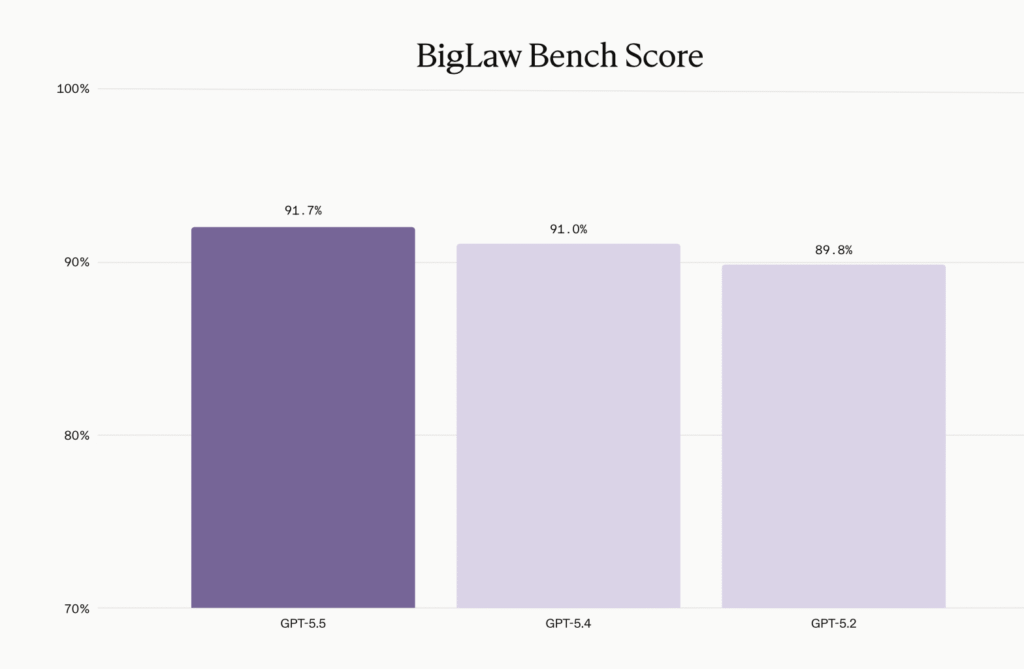
Expert Benchmarks: Strong Legal Reasoning, Incremental Gains
Beyond ad‑hoc ChatGPT 5.5 testing, formal evaluations from specialist vendors show GPT‑5.5 as an incremental but meaningful upgrade. Legal‑tech company Harvey ran the model through its BigLaw Bench suite and reported improvements in substantive accuracy, organizational structure, and formatting across both transactional and litigation tasks. GPT‑5.5 posted an overall score of 91.7%, up from GPT‑5.4’s 91.0%, with 43% of tasks earning perfect marks and 87% scoring above 0.80—none falling below 0.50. Harvey highlighted particular gains in risk assessment, deal management, and analysis of litigation filings. At the same time, the company noted that iteration‑to‑iteration gains are shrinking versus earlier jumps, a trend mirrored in other frontier models. The takeaway for professionals: GPT‑5.5 is not a revolution over GPT‑5.4, but a refinement that tightens structure and accuracy, especially in domains like law where formatting, thoroughness, and internal coherence matter as much as raw creativity.
What GPT‑5.5 Is Ready For—and Where You Still Need a Hand on the Wheel
Taken together, the 10‑round performance test and early partner feedback paint GPT‑5.5 as a powerful but still imperfect agentic AI model. It is already strong enough for many coding tasks (including multi‑step debugging and command‑line workflows), long‑form research assistance, structured document drafting, and complex office automations that previously required multiple prompts. Its ability to plan, keep context, and maintain consistent formatting makes it well‑suited for repeatable workflows and knowledge work. However, recurring exuberance and a tendency to disregard narrow instructions mean users should still enforce guardrails. For critical work, constrain tools, specify sourcing rules, and require the model to explain its steps. Treat GPT‑5.5 as a highly capable collaborator, not an unsupervised agent: let it handle heavy lifting on code, summarization, and drafting, while humans remain responsible for scope definition, source verification, and final sign‑off on any high‑stakes output.
