Open-source AI models are moving from backup option to first choice
Open source AI models are cost-effective language models that release their weights for anyone to download, fine-tune, and deploy, giving enterprises more control than closed commercial AI alternatives while reaching similar or better performance on standard AI model benchmarks. The latest example is GLM-5.2 from Z.ai, an open-weight 700+ billion-parameter system focused on autonomous coding and long engineering tasks. Its weights ship under the permissive MIT licence, so companies can run it via Hugging Face, Z.ai’s API, or entirely on their own infrastructure without lock-in. This model also supports a stable one-million-token context window, which means teams can feed entire codebases or long documents without chopping them into small chunks. Together, open weights, long context and strong scores on public benchmarks are pushing many teams to question whether paying premium rates for closed models still makes sense.

GLM-5.2 tops open-weights and challenges premium models on key benchmarks
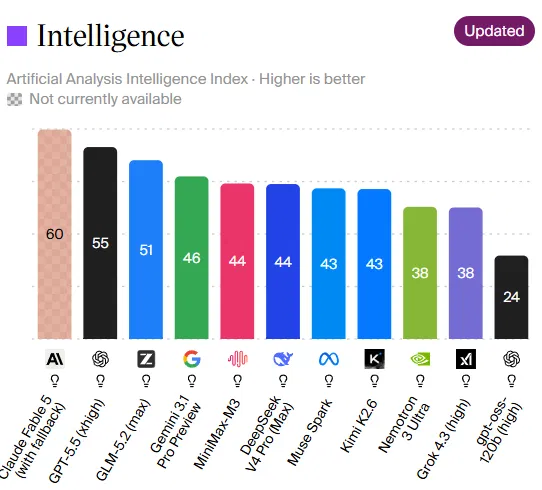
GLM-5.2’s performance story starts with the Artificial Analysis Intelligence Index v4.1, where it scores 51 points and ranks fourth overall behind Claude Fable 5, Claude Opus 4.8, and GPT-5.5, while leading all open-weights models by seven points. A separate report notes that “GLM-5.2 scored 62.1 on SWE-bench Pro, ahead of GPT-5.5’s 58.6,” underlining its strength in practical software engineering tasks. On FrontierSWE, which measures long-horizon coding, it reaches 74.4%, within a point of Claude Opus 4.8 and above GPT-5.5. Tool-use and reasoning numbers also look strong: 76.8 on MCP-Atlas and 54.7 on Humanity’s Last Exam with external tools. In long-running engineering tasks, it scores 34.3% on PostTrainBench and 13% on SWE-Marathon, edging GPT-5.5 even if Claude Opus still leads. For web and interface work, GLM-5.2 also takes first place on the crowdsourced Design Arena benchmark with an Elo score of 1,360.
Costs and control: why enterprises are eyeing GLM-5.2 over commercial AI alternatives
The headline comparison from testing communities is that GLM-5.2 can beat GPT-5.5 Pro on several coding and tool-use tasks at roughly one-sixth of the cost per request, while remaining competitive with Claude Opus 4.8 on long software projects. Because GLM-5.2 is an open-weight, MIT-licensed system, enterprises gain options beyond pure API usage: they can deploy it in their own data centres, constrain it inside regulated environments, or fine-tune specialised versions for internal workflows. The new IndexShare architecture also cuts per-token compute by 2.9 times at full one-million-token context, which matters directly for infrastructure bills. Executives are noticing. Vercel’s CEO called GLM-5.2 “almost shocked” level good at coding and said, “This changes things,” while Box’s CEO described open weights achieving state-of-the-art results as “pretty remarkable” for the broader AI ecosystem and cost structure.

VibeThinker-3B shows how tiny models can rival frontier systems
While GLM-5.2 proves open-weight giants can compete with premium offerings, VibeThinker-3B shows how small models can match much larger systems on hard reasoning. Built on a 3-billion-parameter base, it hits 94.3 on AIME 2026 and can climb to 97.1 with Claim-Level Reliability Assessment, placing it in the same range as DeepSeek V3.2 despite having about 224 times fewer parameters. On coding, it scores 80.2 Pass@1 on LiveCodeBench v6 and achieves a 96.1% acceptance rate on unseen LeetCode weekly and biweekly contests, passing 123 of 128 first-attempt submissions and outperforming GPT-5.2, Doubao Seed 2.0 Pro, Kimi K2.5, and Claude Opus 4.6 under the same test conditions. The researchers argue that verifiable tasks such as mathematics and programming compress well into small networks, even if broader factual knowledge still favours much larger general-purpose models.

What this open-source surge means for your AI budget and stack
Enterprises now face a very different calculus when choosing between open source AI models and closed commercial AI alternatives. GLM-5.2 sits ahead of all Google models on the Artificial Analysis Intelligence Index and offers open weights plus a million-token context window, while VibeThinker-3B matches or exceeds flagship systems from Google, OpenAI, Anthropic, and DeepSeek on multiple reasoning and coding benchmarks. For many teams, that means they can treat open models as default options for coding agents, internal copilots, and long-context document tools, cutting per-request costs and vendor risk. Closed models still matter for broad knowledge and high-stakes deployments, but the gap is narrowing instead of widening. In practice, more organisations are likely to adopt hybrid stacks: open-weight workhorses for routine workloads and a small set of premium APIs reserved for edge cases where they still hold a clear advantage.