AI co-scientists: Powerful in theory, distrusted at the bench
AI co-scientists are software systems that combine large language models with laboratory data and automation tools to propose, set up, and interpret experiments as a digital partner for human researchers in the wet lab. Despite heavy investment, most scientists still see them as distant from day-to-day bench work. A Pistoia Alliance survey of 300 industry leaders found that while 54% see AI delivering value in regulatory submissions and reporting, only 1% report any value in the wet lab, highlighting how far wet lab AI adoption lags. Many teams rely on public generative tools for documents, yet hesitate to let models influence physical experiments. This AI trust in science gap is shaped by two issues: where vendors draw the boundary between general-purpose LLMs and lab data systems, and how well these systems connect to real automation hardware and reliable experimental outcomes.

Sapio and Potato: Embedding LLMs inside lab data workflows
One camp in AI co-scientists keeps the language model close to the existing data backbone. Sapio Sciences wraps Anthropic’s Claude models inside its electronic lab notebook so scientists query experiments through natural language or voice instead of complex filters. What started as a chat interface has become an agent that can reach across email, ELN records, and reports via the Model Context Protocol, while keeping the ELN as the system of record. This architecture aims to boost AI trust in science by letting the LLM see structured assay data but keeping critical actions under human review, echoing the Pistoia Alliance observation that “nothing goes directly from a transformer model to an agency.” Vendors like Potato take a similar stance, acting as connective tissue between fragmented data sources and analysis tools, prioritizing control and audit trails over full autonomy.

Google and OpenAI: Model-first approaches that meet lab reality
A second camp starts from the model and pushes outward toward science. Google DeepMind’s Co-Scientist combines six specialized agents that generate and debate hypotheses in an Elo-style tournament before surfacing the strongest ideas, a very model-centric view of discovery. OpenAI’s GPT-Rosalind positions itself as a reasoning engine that plugs into computational pipelines rather than a full wet lab agent. These architectures maximize LLM capabilities for literature, simulation, and design, but they still depend on separate systems to turn suggestions into lab work. That separation partly explains why wet lab AI adoption sits at 1%, even as document analysis and reporting thrive. Without tight lab automation integration or direct hooks into ELNs and inventory systems, the boundary between model output and experimental execution remains wide, forcing scientists to manually translate suggestions into protocols they can trust and run.
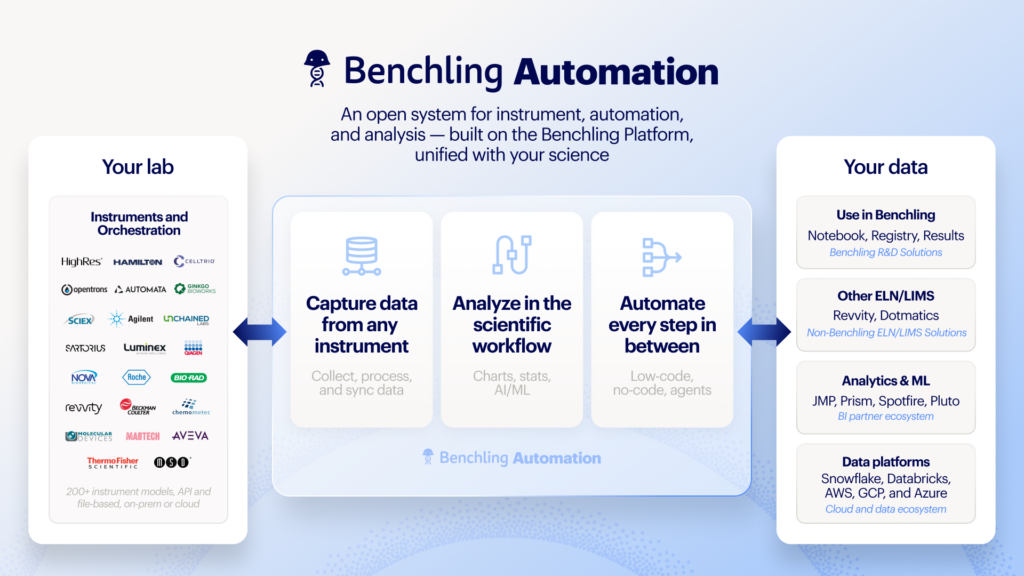
Benchling’s bet: Lab automation integration as the trust engine
Benchling argues that AI co-scientists earn trust only when they can act on the physical lab, not just the data lake. Its AI Scientist concept centers on closing the loop between hypothesis, experiment design, lab automation integration, and results. Benchling already sits at the core of workflows in more than 1,300 biotechs, and it is wiring that position into one-click ordering with CRO partners, a Model Hub for discipline-specific models, and tighter interfaces to workcells and external robotic labs. Co-founder Ashu Singhal frames the problem as a “big wet lab problem”: repetitive assays should run on workcells, standard studies can go to CROs, and ad hoc experiments remain on the bench. In this view, AI co-scientists must know which bucket a protocol belongs in, automatically route it, and then read back structured results, making the model accountable to real-world outcomes.

From architecture to evidence: What it will take to win scientists
Architectural choices alone will not close the AI trust in science gap. Scientists want conversational tools, data interpretation, and discipline-specific prediction, but they also want proof that AI-driven decisions improve real experiments. Trust will depend on whether AI co-scientists can run side-by-side with humans in controlled studies, show higher experimental success rates, and document every step from prompt to pipette in the same systems they already use. Lab automation integration will matter as much as clever reasoning, because it ties models to physical constraints like plate layouts, reagent inventories, and robot schedules. For now, pharma companies enforce a strong rule that human review separates transformer output from external systems. Vendors that shift that line without compromising safety—and can demonstrate better wet lab performance over time—are most likely to unlock meaningful wet lab AI adoption.





