
What Claude Opus 4.8 Is and Why It Matters
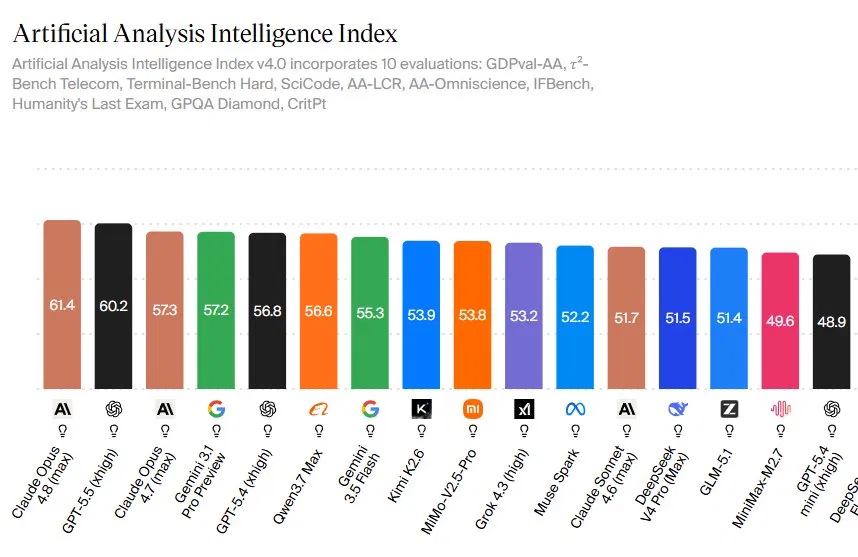
Claude Opus 4.8 is Anthropic’s newest flagship large language model that raises AI capability and practical usability for developers by reducing code flaws, improving decision-making in complex tasks, and delivering much faster responses without a price increase over the previous version. On the Artificial Analysis Intelligence Index v4.0, Opus 4.8 scores 61.4, ahead of GPT-5.5’s 60.2 and Opus 4.7’s 57.3, signaling a new leader in AI model performance comparison. The index blends ten demanding benchmarks, including GDPval-AA for real-world tasks, SciCode, and Humanity’s Last Exam, giving a broad view of model competence across coding, reasoning, and tool use. For engineering teams, the message is clear: this is not only a higher-scoring model in tests, but one designed to run more of the work in production-like settings with fewer manual corrections and less babysitting.
Benchmark Results: From Intelligence Index to GDPval-AA
On headline metrics, Claude Opus 4.8 posts a 61.4 score on the Artificial Analysis Intelligence Index, edging GPT-5.5’s 60.2 through steady gains rather than a single standout test. Anthropic’s internal data shows a SWE-Bench Pro score of 69.2% for agentic coding, compared with 58.6% for GPT-5.5, and strong results on Humanity’s Last Exam and OSWorld-Verified for computer use. The most important Claude Opus 4.8 benchmark, however, may be GDPval-AA, which approximates economically valuable work across 44 occupations. Here, Opus 4.8 reaches 1890 Elo, sitting 121 points above GPT-5.5 and 137 points over Opus 4.7. Artificial Analysis notes that this corresponds to an implied 67% win rate against GPT-5.5 xhigh, a significant practical edge for businesses that care about completed tasks, not only test scores.
Code Quality Improvements: 75% Fewer Bugs for Developers
For software teams, the standout change is code quality. Anthropic says Claude Opus 4.8 is four times less likely to let code flaws pass unnoticed than Opus 4.7, a 75% reduction in undetected issues. On SWE-Bench Pro, Opus 4.8’s 69.2% score outperforms GPT-5.5 and Gemini 3.1 Pro, reflecting better handling of realistic bug fixes and repository-scale changes. Anthropic also reports gains in agentic coding from 64.3% to 69.2%, and improved performance in agentic financial analysis and tool-assisted reasoning. Early testers describe the model as more candid about uncertainty and “more honest about its progress,” with fewer unsupported claims and lower measured deception rates. In practice, this means fewer silent failures, clearer error surfacing, and more reliable automated refactors. For developers using Claude Code, these code quality improvements can translate to less time spent debugging AI-generated patches and more time focusing on architecture and product behavior.
Speed, Cost, and Turn Efficiency in Real Workloads
Performance is not only about raw intelligence scores; it also depends on how quickly and efficiently a model finishes work. Opus 4.8’s standard mode launches at the same price as Opus 4.7, while internal efficiency improves: on GDPval-AA it uses 15% fewer turns and 35% fewer output tokens than its predecessor. Yet it still needs around 30% more turns than GPT-5.5 to complete similar tasks, an important detail for high-volume, cost-sensitive deployments. Anthropic addresses latency and cost with Fast Mode, which runs the same model at about 2.5x the speed and costs one-third of the standard mode. Developers can trigger it in Claude Code with the /fast command, making it suitable for LLM speed tests, exploratory coding, or rapid feedback loops, while reserving full-effort runs for complex production changes and critical analyses.
New Workflow Features and the Road Ahead for Developers
Beyond raw benchmarks, Anthropic is shipping workflow features that change how developers use the model. Dynamic Workflows, in research preview inside Claude Code, let Opus 4.8 plan work and run hundreds of parallel subagents in a single session, enabling codebase-scale migrations across hundreds of thousands of lines. Effort Control adds a slider that lets users tune how much computation Claude applies per response; low effort favors speed and rate limits, while Opus 4.8 defaults to high effort to balance quality. Together with the AI model performance comparison wins on GDPval-AA and the Artificial Analysis Intelligence Index, these tools mark a shift toward agentic, multi-step development workflows rather than single prompts. For teams, the upgrade is less about a shiny new model name and more about everyday gains: fewer bugs, faster iterations, and AI systems that can own larger pieces of the software lifecycle.





