From AI Curiosity to CI/CD Crisis
An AI deployment pipeline is the automated system that moves AI code and models from development through testing to production, handling frequent changes, model versions, and environment-specific checks so teams can release reliable updates at high speed. In the last few years, AI moved from experimental playgrounds to the core of everyday software delivery. One source reports AI adoption among developers rising from 76% in 2024 to 90% in 2025, while another notes that 78% of organizations already used AI in 2024. At the same time, the cost of running powerful models has collapsed, removing many of the old barriers to entry. When everyone has access to capable, cheaper models, the scarce resource is no longer algorithms. It is the CI/CD infrastructure that can keep up with the flood of changes those models enable.
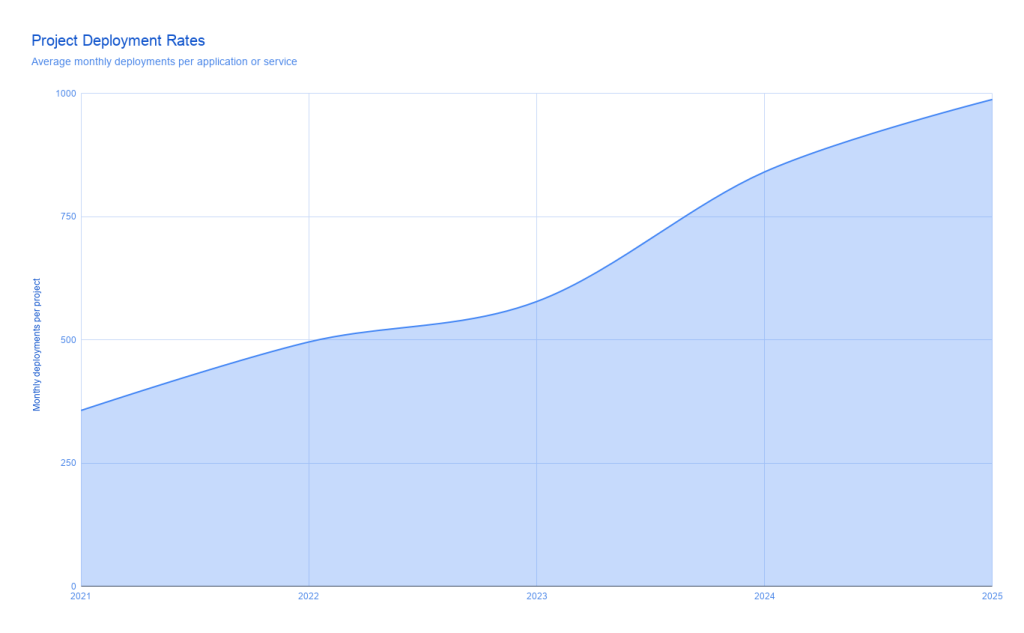
1,000 Deployments a Month Needs Different Plumbing
High-performing teams are now averaging close to 1,000 deployments per application each month across dev, test, staging, and production. One source reports project deployment rates rising from 357 per month in 2021 to 988 in 2025, a 175x competitive gap over teams still shipping once a week. Since the end of 2025, those rates have already pushed past the 1,000-per-month mark. This is continuous deployment AI in practice: dozens of production pushes every working day, not the occasional release train. At this tempo, traditional CI tools and manual approvals buckle. AI model deployment automation must handle not only code changes but model retrains, feature store updates, and configuration drift in real time. If your AI infrastructure bottleneck sits in a queue of weekly releases, you are invisible against teams firing features, experiments, and model tweaks into production many times per day.
Legacy Pipelines Were Built for Monthly Releases
Most legacy CI/CD infrastructure assumes slow, linear workflows: code freezes, lengthy test cycles, and synchronized monthly releases. That model breaks when AI teams deploy 1,000 times a month. Each model version may involve new prompts, data slices, or safety constraints that must be validated across environments. Traditional pipelines rarely treat models as first-class artifacts with their own lifecycle, registry, and rollback paths. They also struggle with the compound effect of many small changes, where four environments and a modest failure rate still mean dozens of daily production pushes. According to Octopus Deploy data, deployment rates increased between 17% and 46% each year from 2021 to 2025, and those gains compound. Without automated quality checks, policy enforcement, and model-aware rollbacks, organizations hit an AI infrastructure bottleneck: they cannot safely increase release frequency, so they slow or suspend AI upgrades to protect stability.
Execution, Not Algorithms, Is Now the Competitive Edge
Open-weight and smaller models have narrowed the gap with proprietary systems, and inference costs have dropped sharply. One report notes that the price of querying a GPT-3.5-level model fell more than 280-fold between late 2022 and late 2024. With access to capable AI now widespread, the moat is shifting from model ownership to execution quality. Companies that treat AI as a side project, limited to pilots and demos, are quietly choosing to fall behind. The leaders rebuild workflows around AI: they redesign deployment pipelines, embed AI into core processes, and measure cycle time, error rates, and software velocity. In this world, the decisive advantage comes from CI/CD infrastructure that supports continuous deployment AI at scale. The question is less “Which model should we choose?” and more “How fast can we safely ship the next better version?”
How to Modernize Your AI Deployment Pipeline
Fixing the AI deployment pipeline starts with treating models like any other critical software artifact. Teams need versioned model registries, automated promotion rules across environments, and clear rollback procedures tied to both code and weights. Continuous testing must expand beyond unit and integration checks to include data quality, bias tests, and prompt behavior. Monitoring must track model drift, failure rates, and business metrics so each deployment becomes another arrow aimed at the product bullseye. Equally important, ownership must be unambiguous: cross-functional teams spanning engineering, data science, and operations should own the full release path. Continuous deployment AI is not about forcing more code out of teams; it is about building pipelines where small, safe, and frequent changes are the default. The companies that invest in this deployment automation now will be the ones able to turn AI ideas into production value at market speed.





