Why Padding Overhead Is Killing Your LLM Inference
LLM inference optimization is the practice of restructuring model execution, batching, and memory use so that every GPU operation advances useful tokens instead of wasting work on padding or idle compute. Standard LLM batching pads each request to the length of the longest sequence in the batch, which means GPUs perform huge numbers of multiplications on zero tokens that do not affect the output. This padding overhead burns compute cycles and memory bandwidth, inflates latency, and increases cloud bills, especially when one very long sequence forces thousands of shorter ones to expand. In one C++ backend case study, padding-heavy Python pipelines were described as paying a chef to cook an empty plate, because much of the apparent load was fake work on zeros. Eliminating that fake work is the single biggest low-hanging fruit in modern LLM inference optimization.
From Rectangles to Ribbons: Hardware-Aware Sequence Packing
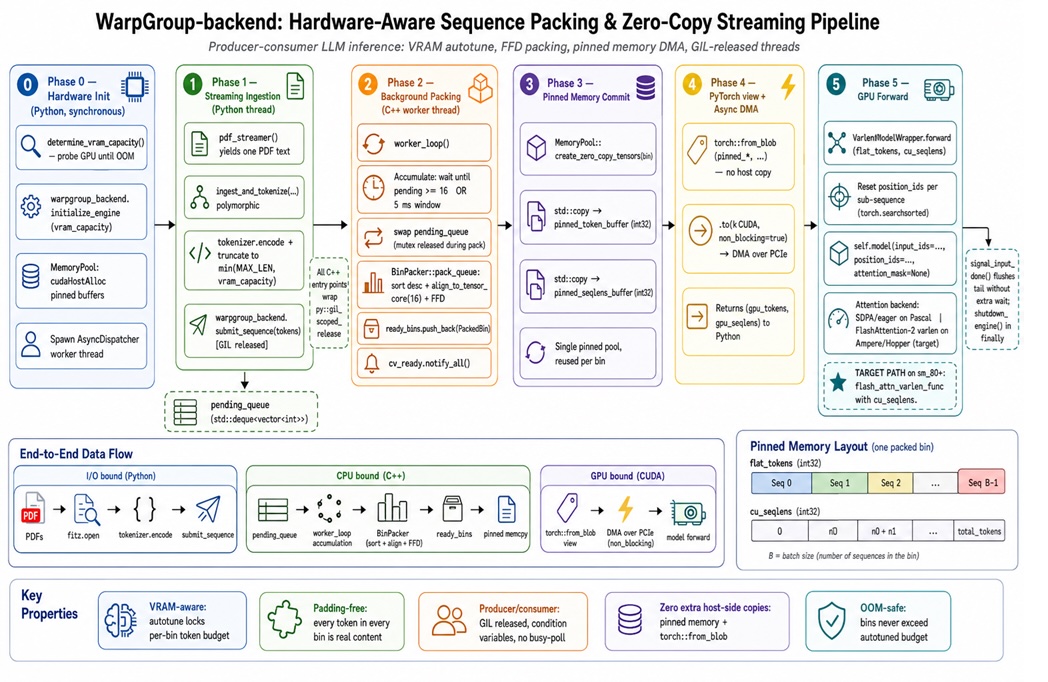
To eliminate padding overhead, you must stop treating ragged text as a rectangle and start treating it as a 1‑D ribbon plus offsets. GPU sequence packing groups variable-length sequences into bins where the limit is total tokens, not the longest sequence. You concatenate all tokens in a bin into a flat array and provide the attention kernel with segment boundaries so tokens only attend within their own sequence. FlashAttention‑2’s variable-length kernel is designed for this pattern, and modern inference stacks use similar ideas under the hood. The key twist is hardware-aware scheduling: NVIDIA tensor cores prefer sequence dimensions aligned to tile sizes (often multiples of 16), so practical packers round each sequence length up (for example, 137 to 144) before binning. That small alignment cost recovers efficiency in GEMMs, memory coalescing, and warp tiling, turning irregular text into GPU-friendly work units.
Why C++ Backends Matter for Real-Time Throughput
Packing sequences is conceptually simple but performance sensitive: it needs to keep up with tokenization and GPU kernels without becoming the new bottleneck. Python’s global interpreter lock makes it difficult to run tokenization, bin packing, and GPU feeding in parallel threads. A C++ backend avoids this limit by doing sequence packing, VRAM-aware bin sizing, and pinned-memory transfers off the Python hot path. One such backend reported up to 2.08× throughput on an H100 and 5.89× on a GTX 1080 by combining GPU sequence packing with hardware-aware bin sizing and asynchronous dispatch. The pipeline measures usable VRAM, fills bins using a first-fit decreasing strategy, and streams them over DMA while the model runs. This design turns LLM inference into a steady producer–consumer flow instead of a start‑stop pattern constrained by the host runtime.
Throughput at Scale: From Open Backends to UltraSpeed APIs
Removing padding and aligning work with GPU hardware pays off most at scale, where small percentage gains compound into big savings. When thousands of concurrent users share a fleet of GPUs, reducing fake work frees capacity for more tokens per second or higher-quality models. According to Xiaomi, the MiMo‑V2.5‑Pro UltraSpeed mode co-designed with TileRT reaches over 1,000 tokens per second on general-purpose GPUs, about ten times faster than standard MiMo‑V2.5‑Pro API access. That kind of jump depends on careful co-design of model, kernels, and scheduler so GPUs never sit idle or grind on padding. For in‑house systems, C++ sequence packers offer a similar path: replacing rectangular padding with hardware-aware scheduling and bin packing can unlock multi‑x throughput gains while avoiding out-of-memory crashes, making large-scale LLM deployment both faster and more cost-effective.





