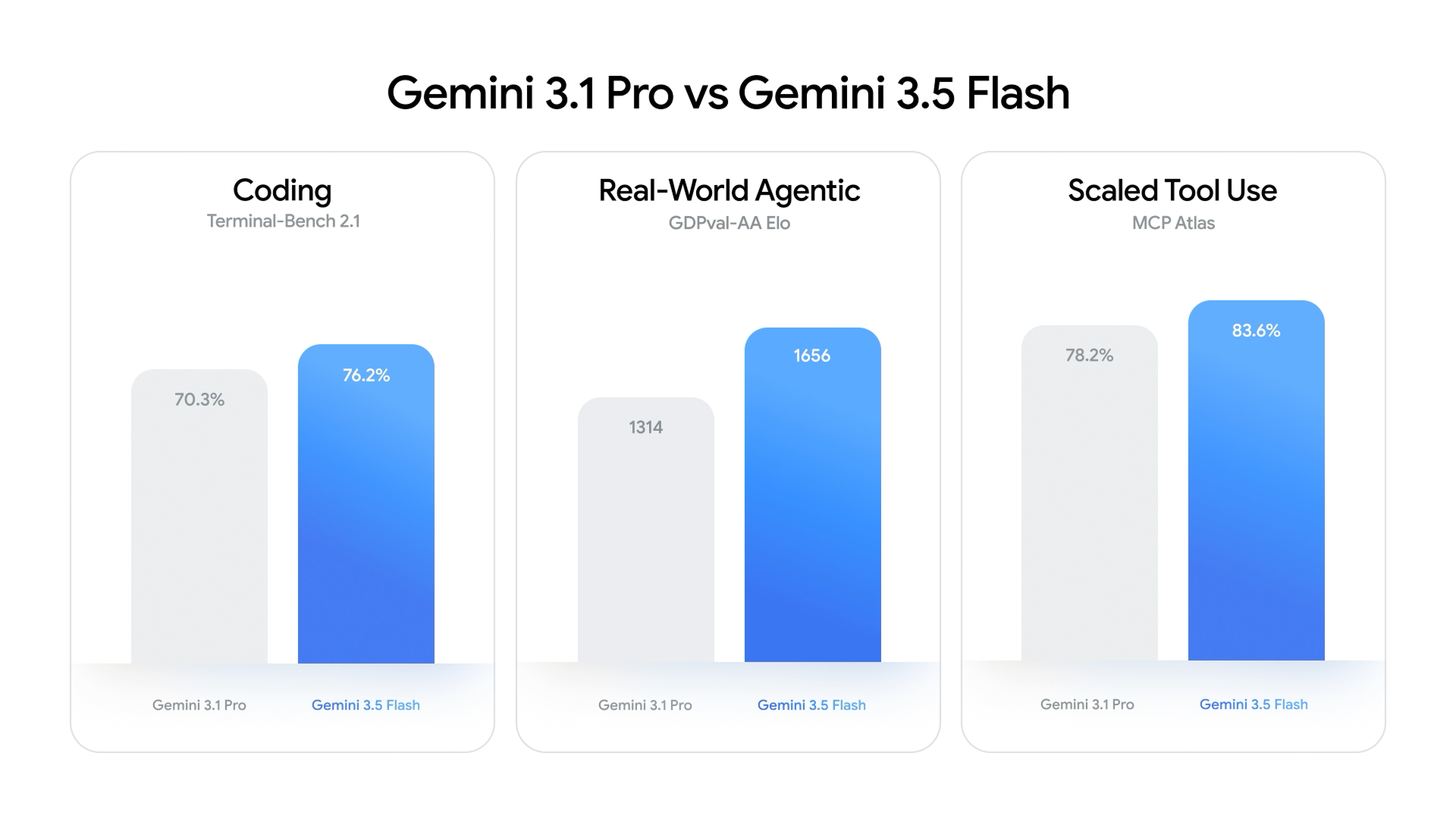
A Flash-Tier Model That Overtakes Pro-Class Performance
Gemini 3.5 Flash marks a turning point in AI model design: a speed- and cost-optimized “Flash” model now outperforms Google’s own recent Pro flagship on key AI model benchmarks. Announced at Google I/O as the first member of the 3.5 family, it was built primarily for real-world agentic and coding tasks rather than pure leaderboard glory. Yet the results show a clear leap. On the Terminal-Bench 2.1 coding benchmark, Gemini 3.5 Flash reaches 76.2%, ahead of Gemini 3.1 Pro’s 70.3%. In the GDPval-AA Elo benchmark for agentic behavior, it scores 1,656 versus 3.1 Pro’s 1,314, signalling a step-change in how well it can operate autonomously. This inversion—where a Flash-tier model eclipses a months-old Pro release—signals a more compressed cycle of capability gains and a blurring line between “efficient” and “flagship” frontier AI models.
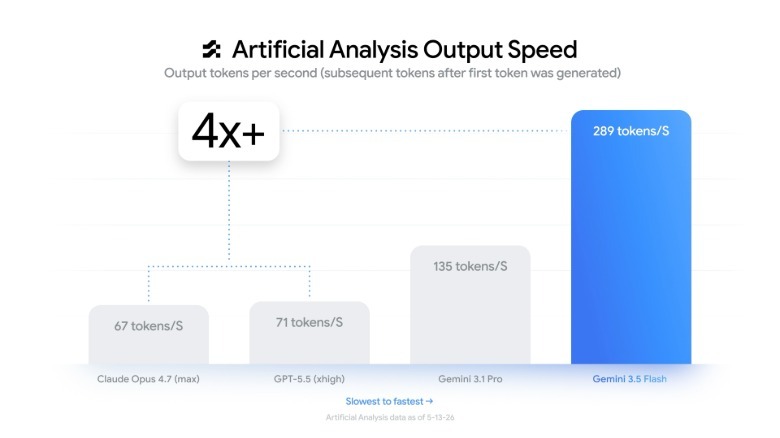
Speed Breakthrough: 289 Tokens Per Second Changes the Economics
If raw capability puts Gemini 3.5 Flash on the map, speed is what reshapes how developers think about deployment. Google says the model delivers around 289 output tokens per second, roughly four times faster than other frontier AI models. That level of throughput means multi-step agents, iterative coding tools, and interactive assistants can respond in near real time, even when orchestrating complex workflows. For teams running large numbers of concurrent agents, faster completion times translate directly into lower latency and a different cost profile at scale. Long-horizon tasks that previously took weeks of incremental automation can now finish in a fraction of the time under supervision. The model’s speed-to-intelligence ratio removes much of the traditional tradeoff between quality and responsiveness, making Gemini 3.5 Flash a practical default choice for many production workloads rather than a niche “fast but weaker” option.
Coding Task Speed and Agentic Strength Take Center Stage
Gemini 3.5 Flash is particularly tuned for coding task speed and agentic reliability. On coding, it not only beats Gemini 3.1 Pro on Terminal-Bench 2.1 but is positioned by Google as rivaling larger flagship models on multiple dimensions. Beyond raw code generation, the model can plan across large codebases, decompose problems into sub-tasks, and deploy subagents to work in parallel. That makes it well-suited for refactors, migration projects, and complex debugging that previously demanded sustained human oversight. On the agentic side, the GDPval-AA and MCP Atlas benchmark gains suggest stronger real-world decision-making and more robust tool use at scale. Google notes that partners in domains like banking and fintech are already using it to automate multi-week workflows. For developers, these improvements translate into agents that can not only write functions faster, but also reliably execute multi-step workflows end to end.
A New Pattern: Lightweight Models Surpassing Recent Flagships
The Gemini 3.5 Flash release illustrates a broader shift: model generations are improving so quickly that lightweight variants are overtaking recent flagships within months. Gemini 3.1 Pro debuted with strong AI model benchmark results and competitive pricing relative to peers, yet the 3.5 Flash tier now outperforms it in coding, tool use, and agentic metrics while delivering significantly higher throughput. Earlier, Gemini 3.1 Flash-Lite had already shown that speed and efficiency could coexist with respectable reasoning. With 3.5 Flash, the distinction between “Pro for quality” and “Flash for speed” is narrowing further. For developers, this compresses upgrade cycles and complicates long-term planning: design choices made around a Pro model’s strengths may be outpaced by a Flash successor in a single quarter. The practical implication is to assume rapid capability turnover and architect systems to swap models with minimal friction.
What Gemini 3.5 Flash Means for Model Selection and Product Design
For teams building agents, IDE copilots, or high-volume automation systems, Gemini 3.5 Flash becomes a compelling default. It combines frontier-level intelligence with actionable speed, making it well-suited as the core engine for long-horizon workflows, interactive coding tools, and consumer agents. Google is already standardizing on it for the Gemini app, AI Mode in Search, and the Gemini Spark personal agent, indicating confidence in its balance of capability and latency. At the same time, Google notes that an upcoming Gemini 3.5 Pro will still lead on deep reasoning and high-context tasks. The strategic takeaway is to think in terms of a two-tier stack: use Flash where coding task speed, concurrency, and agentic throughput matter most, and reserve Pro-class models for fewer, high-value reasoning calls. In this emerging pattern, speed-first models no longer feel like compromises—they are becoming the workhorses of real-world AI products.