What Padding Waste Looks Like in Real LLM Inference
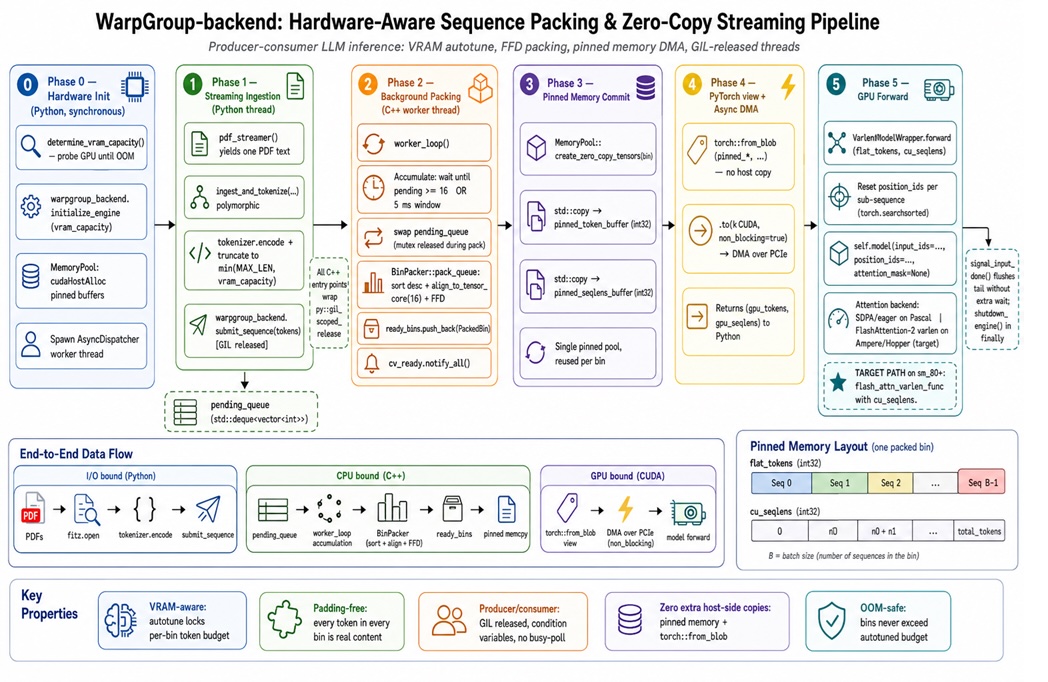
Hardware-aware sequence packing is an LLM inference optimization technique that eliminates redundant padding by concatenating variable-length sequences into a single packed batch while preserving their logical boundaries for attention, reducing GPU memory usage and avoiding wasted compute on pad tokens. In a typical transformer pipeline, variable-length requests are padded to match the longest sequence in the batch so GPUs can work on neat rectangles. When one prompt is 60 tokens and another is 2,000, every shorter input gets inflated up to 2,000 with zeros. The GPU then spends a significant share of its FLOPs and memory bandwidth on pad tokens that never affect the model’s output. This padding overhead reduction problem matters at production scale, where “most of your GPU’s work is fake” and a large portion of your serving capacity evaporates into useless multiplications on zeros.
From Rectangles to Packed Ribbons: The Sequence Packing Technique
The core sequence packing technique replaces padded rectangles with a single “token ribbon” plus metadata. All sequences in a batch are concatenated into one long 1‑D array, and variable-length attention kernels (such as FlashAttention‑2’s varlen function) keep tokens from different requests isolated. Instead of padding every input to the maximum length, you pack many short sequences next to longer ones until you hit a token budget per batch. This is a bin‑packing problem: given a bin capacity in tokens, fill it with sequences so remaining slack is minimal. First‑Fit Decreasing works well in practice: sort sequences by length, then drop each into the first bin with enough room. The result improves GPU memory efficiency by raising the ratio of real tokens to total processed tokens and keeps more Streaming Multiprocessors busy with useful work.
Making Packing Hardware-Aware: VRAM Limits and 16-Token Alignment
To work in production, sequence packing must respect GPU hardware behavior instead of assuming a fixed, safe batch size. Usable VRAM for inference depends on model size, activation and KV‑cache footprint, allocator fragmentation, and runtime quirks, so the bin capacity needs to be measured, not guessed. A practical approach is a "GPU job interview": keep probing with larger packed sequences until the device runs out of memory, then back off by a margin and treat that as your budget. On modern NVIDIA hardware, tensor cores also prefer sequence-related dimensions that are multiples of 16 (sometimes 8) for efficient tiling. Aligning sequence lengths upward, such as rounding 137 to 144 tokens, improves kernel efficiency even in a packed setting. Combined, empirical VRAM sizing and 16‑token alignment turn sequence packing from an abstract algorithm into a hardware‑aware LLM inference optimization.
Why a C++ Backend Matters for Packing at Scale
Packing logic in the Python hot path hits a wall because of interpreter overhead and the global interpreter lock, which throttles true parallelism. In high-throughput systems, you want Python handling tokenization and request orchestration while a C++ backend performs bin packing and memory management in parallel. According to the WarpGroup-Backend author, a C++ packing engine combined with variable-length attention and pinned-memory transfers delivered 2.08× throughput on an H100 and 5.89× on a GTX 1080, with no out-of-memory crashes. The backend runs sorting, bin packing, and ribbon construction in background threads, hands batches to the GPU via async DMA, and leaves Python free to keep feeding the queue. That separation turns packing from a bottleneck into an invisible stage and makes padding overhead reduction a reliable gain rather than a source of new latency.
Integrating Sequence Packing into Production LLM Inference
To apply sequence packing in production, treat it as a scheduling layer between requests and the model. First, estimate your safe per‑batch token budget with an empirical VRAM probe. Second, represent incoming prompts by token length and stream them into a C++ packing service that uses First‑Fit Decreasing with alignment to form near‑full bins. Third, use a variable-length attention kernel so the model can process the packed ribbon without inter‑request leakage. Finally, monitor GPU utilization and throughput to tune alignment, safety margins, and queueing policy. This pattern echoes radio network schedulers that pack variable user traffic into fixed resources. For large-scale inference workloads, the payoff is straightforward: more real tokens processed per second on the same hardware, fewer OOM events, and a serving stack where GPUs spend far less time “eating air” and far more on useful generation.





