What Gemma 4 12B Is and Why It Matters
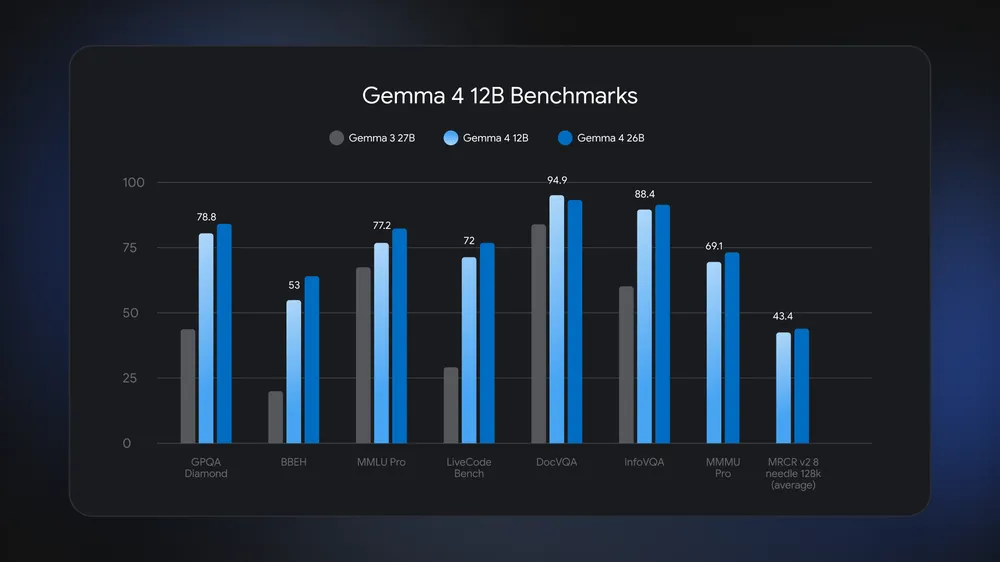
Gemma 4 12B is a 12-billion-parameter, encoder-free, local multimodal AI model from Google DeepMind that can run text, image, audio, and code workloads entirely on consumer laptops with 16GB of memory, combining near–flagship performance with a dramatically smaller memory footprint and no need for dedicated AI hardware or cloud services. Unlike earlier Gemma releases that targeted either phones or high-end workstations, Gemma 4 12B fills the middle ground. According to Google DeepMind, it runs on any laptop with 16GB of system RAM or VRAM while using about half the memory of the larger Gemma 4 26B Mixture-of-Experts model, yet it stays close on benchmark scores and surpasses Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA. It is released under the Apache 2.0 license, and weights of roughly 18GB are already available on Hugging Face and Kaggle, which lowers the barrier for both developers and hobbyists to experiment with an on-device AI model.

Encoder-Free Architecture: Multimodal AI Without the Overhead
Most multimodal models bolt separate vision and audio encoders onto a language backbone, which adds hundreds of millions of parameters, latency, and memory usage. Gemma 4 12B replaces this with an encoder-free architecture that feeds non-text inputs directly into the language model, making laptop AI inference much lighter. For images, a small 35-million-parameter embedding module slices inputs into 48×48 pixel patches and projects each patch into the model’s hidden dimension using a single matrix multiplication plus positional embeddings. That design removes the 27 vision transformer layers and roughly 550 million parameters found in the medium Gemma 4 variants, while preserving spatial information. Audio goes even further: raw 16 kHz waveforms are split into 40-millisecond frames and mapped straight into the same vector space as text tokens, with no separate encoder. This tight integration cuts memory use and latency, yet still enables image understanding, video analysis, speech recognition, and speaker diarization on a standard 16GB laptop.

Agentic, On-Device Workflows for Developers and Power Users
Because Gemma 4 12B accepts text, images, and audio directly, it is well suited to agentic AI workflows that must coordinate several steps and tools locally. Developers can build assistants that read a document screenshot, listen to a voice query, call external tools or APIs, and generate code or plans in one continuous loop, all running on-device without a cloud round trip. Google reports that Gemma 4 12B clearly outperforms Gemma 3 27B on complex reasoning benchmarks such as GPQA Diamond and MMLU Pro, which matters for multi-step tasks like debugging code, summarizing long videos, or orchestrating tool calls. The model’s ability to process long audio and video clips, as shown in a demo that analyzed a five-minute keynote by reading 313 frames alongside audio, points to use cases like meeting assistants, offline transcription, and searchable video notes. For consumers, this means more private assistants, creative tools, and coding helpers that work even when the internet connection is slow or unavailable.
LiteRT-LM and Multi-Token Prediction: Making Laptops Feel Fast
To keep local multimodal AI responsive on modest hardware, Google pairs Gemma 4 with the LiteRT-LM runtime. LiteRT-LM, built on LiteRT (formerly TensorFlow Lite), is an optimized environment for on-device AI model execution across Android, iOS, and the web. Its orchestration layer focuses on memory efficiency, aggressive quantization, and minimized CPU–GPU transfers, all aimed at faster laptop AI inference. A key part is native support for Multi-Token Prediction (MTP) drafters. Gemma 4 12B is the first Gemma 4 model to ship with MTP enabled by default, using spare compute to predict multiple future tokens at once and then verifying them. According to Google, LiteRT-LM can deliver up to 2.2× faster decoding for Gemma 4 E4B and 1.6× for E2B compared with standard decoding, while prefill and decode reach 1.8× to 3.7× the speed of frameworks such as llama.cpp, MLX, Cactus, and ONNX. The same techniques apply when running Gemma 4 12B locally, helping long, multimodal conversations feel more fluid on 16GB machines.
What This Shift Means for Mainstream Users
Gemma 4 12B shows how an encoder-free architecture and tuned runtime can turn everyday laptops into capable local multimodal AI workstations. Without needing a dedicated accelerator, users with 16GB RAM machines can run image analysis, audio transcription, code generation, and tool-driven agents locally, avoiding recurring cloud costs and keeping sensitive data off remote servers. For developers, Apache 2.0 licensing and sub-18GB weights open a path to ship offline-first applications that handle complex reasoning and multimodal inputs. LiteRT-LM’s session management and memory-saving tricks, such as careful handling of embeddings and quantized weights, further extend what is possible on constrained hardware. As more APIs in Swift and JavaScript arrive, integrating Gemma 4 12B into desktop apps, browsers, and mobile experiences should become easier. The net effect is that local multimodal AI moves from a niche reserved for high-end rigs to something that works on the laptops many people already own.





