AI Agent Deployment and the Cost of “Blowing Things Up”
AI agent deployment is the process of designing, integrating, and operating autonomous or semi-autonomous software agents within an organization’s existing technology stack so they can use enterprise data, workflows, and governance to automate work at scale. Many vendors are telling enterprises that to do this, they must rebuild their architecture, move all data into a new cloud platform, and overhaul business processes. Hyland CEO Jitesh Ghai calls this “blowing things up” and argues it is both unnecessary and improper. The rip-and-replace playbook introduces new silos, long migration projects, and double spending on overlapping tools. In regulated industries, it also adds risk: every new stack must be secured, audited, and trained on complex, unstructured data. Instead of chasing a fresh AI infrastructure strategy from scratch, enterprises are starting to question whether the real value lies in deeply connecting agents to the systems they already own.

The Case for Enterprise Stack Integration, Not Reinvention
Ghai’s core argument is that context for AI agents lives inside current systems, not in a brand-new architecture. “If you want context, you have to meet an organization where it is, not reinvent yourself as a new organization,” he says. Enterprise stack integration means connecting agents to content management systems, line-of-business apps, and existing data stores rather than centralizing everything in a single new platform. That approach respects permissions, records of authority, and local business logic that evolved over years. It also avoids forcing every business process through one vendor’s interface. With context treated as the real moat, platforms like OpenText, Box, and Hyland are racing to become the layer that understands documents, metadata, and workflows already in place. For enterprises, this integration-first model can reduce disruption while keeping control over where agents run and how they access sensitive information.
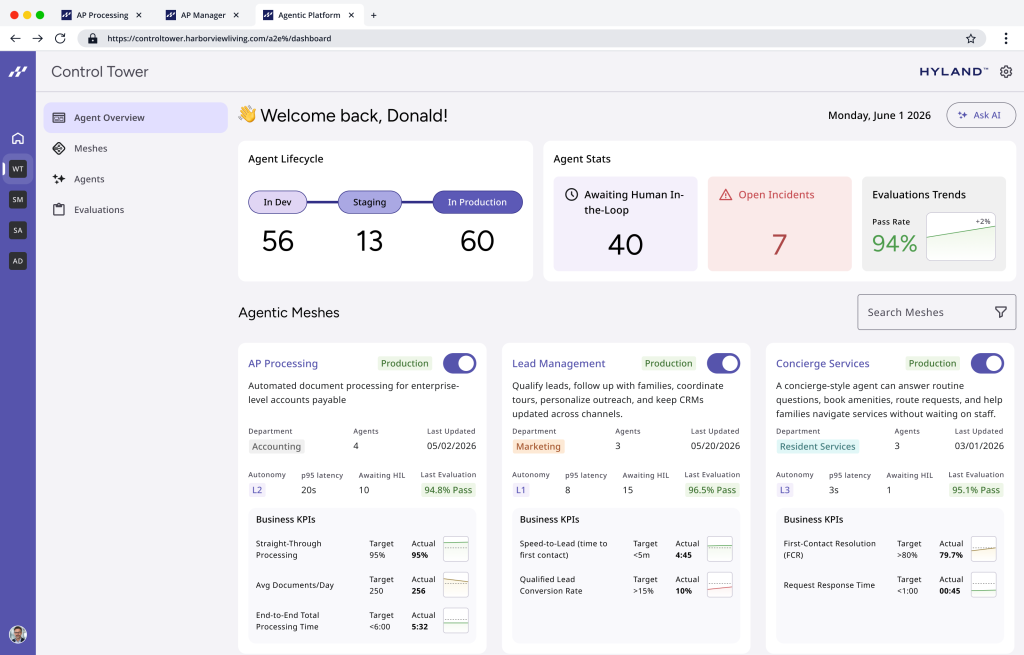
Enterprise Context Engine and Agent Mesh as Integration Pattern
Hyland’s Enterprise Context Engine and Enterprise Agent Mesh show how an agent platform architecture can sit on top of, rather than replace, existing stacks. The Context Engine federates content from current systems through the Content Innovation Cloud, adds AI to structure unstructured documents, and builds a knowledge graph aligned to industry ontologies in healthcare, insurance, financial services, education, and government. According to Hyland, many AI initiatives fail because vendors underestimate the complexity of underlying data and its industry-specific meaning. The Agent Mesh then connects agents to this governed context layer, with a Control Tower planned to give observability into decision paths and compliance. Agent Lifecycle Management tracks each agent from design to retirement, with an Agent Library and an Agent Passport defining identity, capabilities, and guardrails before production. This pattern keeps context and governance close to where data already lives while enabling new agent experiences.

From Human ETL to Content-Powered Agents
A major economic argument for integrated AI agent deployment is the reduction of what Ghai calls “human ETL” work. Knowledge workers in regulated industries spend large portions of their week extracting, transforming, loading, and interpreting information locked in documents because unstructured content could not previously be given reliable structure. Hyland estimates that these tasks consume between 20% and 40% of workers’ time and that 70% to 90% of enterprise data is unstructured, much of it sitting in content management systems. Large language models and contextual knowledge graphs can automate labeling, classification, and relationship detection so agents can assemble case files, summarize histories, or surface missing data with minimal human intervention. Instead of replacing entire workflows, content-powered agents remove the administrative parts, allowing existing systems of record to stay in place while workers focus on exceptions, judgment calls, and direct customer work.
Best Practices for an AI Infrastructure Strategy That Preserves Investments
Enterprises looking to avoid costly architectural mistakes can follow several practical principles. First, design an AI infrastructure strategy around context and governance layers that sit above current applications, rather than locking into a single monolithic agent platform. Second, prioritize enterprise stack integration through headless APIs so agents can read and act on content without forcing users into new interfaces; Hyland’s headless mode for its Content Innovation Cloud is one example. Third, introduce Agent Mesh and lifecycle management patterns that catalog every agent, define guardrails through artifacts like an Agent Passport, and centralize observability in a Control Tower. Finally, start with targeted, pre-built agents in high-value processes instead of enterprise-wide process redesign. This incremental, integration-first approach preserves existing investments, reduces change management overhead, and delivers faster returns while still setting a path to an agentic enterprise.





