What Gemma 4 12B Is and Why It Fits on a 16GB Laptop
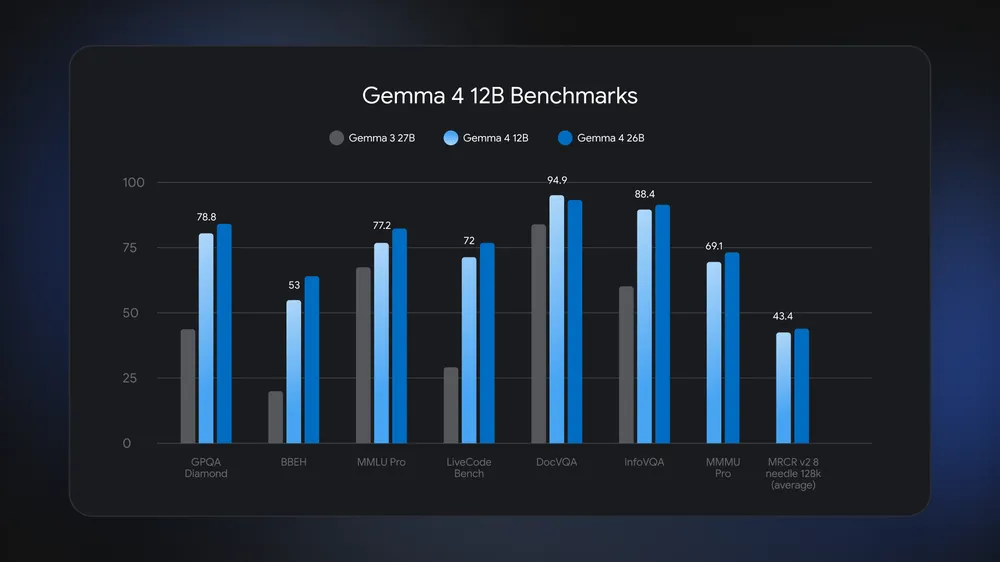
Gemma 4 12B is a 12-billion-parameter open-weights multimodal AI model that can run AI locally on a laptop, handling text, images, and audio in one unified architecture without dedicated encoders, and it is designed to fit into the memory and compute limits of consumer machines with 16GB RAM. Google positioned it between phone-class and workstation-class Gemma 4 variants, giving you far more capability than mobile models without needing a data center GPU. The 12B model uses roughly half the memory of the 26B Mixture of Experts while staying close to it on many benchmarks and beating Gemma 3 27B on tests like GPQA Diamond, MMLU Pro, and DocVQA. It processes images through a slim 35-million-parameter visual embedding module and handles raw 16 kHz audio directly, which cuts latency and memory use and makes it well suited for local AI agents on standard laptops.

System Requirements and Model Download for Gemma 4 12B
To run Gemma 4 12B locally, plan around the memory footprint first. The open-weights package is just under 18GB and requires a machine with at least 16GB of system RAM or VRAM, making it a realistic 16GB RAM AI model for many consumer laptops. You will also want several gigabytes of free disk space for model files and caches. According to Google DeepMind, Gemma 4 12B can run on “any laptop with 16GB of RAM” when properly configured. Download the model from trusted hubs such as Hugging Face or Kaggle, where it is released under the Apache 2.0 license. Grab a quantized variant if your laptop is tight on memory. Keep the files in a dedicated directory so LiteRT-LM or your chosen runtime can find the weights, tokenizer, and configuration needed for multimodal AI inference.
Setting Up LiteRT-LM for Faster Local Multimodal Inference
To get efficient multimodal AI inference on CPU-only laptops, install LiteRT-LM, Google’s optimized runtime built on LiteRT (formerly TensorFlow Lite). LiteRT-LM is designed for large language models under memory and compute constraints, and now brings native support for Gemma 4 Multi-Token Prediction drafters. Its quantization schemes and XNNPACK or MLDrift kernels help keep inference responsive even without dedicated AI hardware. The framework reduces costly data transfers by keeping work on one hardware block where possible and manages sessions so you can pause and resume long chats without recomputing everything. According to Google, LiteRT-LM with Multi-Token Prediction can speed up Gemma 4 decoding by up to 2.2x compared to earlier approaches. Once installed, point LiteRT-LM to your Gemma 4 12B weights, enable multi-token prediction in the configuration, and test a simple text-only prompt before moving to images and audio.

Running Multimodal Prompts: Text, Images, and Audio in One Model
After setup, you can run AI locally on your laptop with prompts that mix text, images, and audio through a single Gemma 4 12B instance. The encoder-free design means images are split into 48×48 pixel patches and fed into the model by a light 35-million-parameter visual module, while audio is chopped into 40-millisecond frames from raw 16 kHz waveforms and projected into the same space as text tokens. This lets you build local AI agents that describe screenshots, summarize photos of whiteboards, or answer questions about PDFs rendered as images. For audio, you can perform speech recognition, speaker diarization, or summarize meeting recordings without sending data to a server. Because everything flows through one backbone, latency and memory use stay lower than traditional multimodal stacks, which is crucial on a 16GB laptop without a discrete GPU.
Practical Agent Use Cases on a Consumer Laptop
With Gemma 4 12B and LiteRT-LM, you can build practical local AI agents that combine vision, audio, and tools on a single machine. One agent might read your screen, accept voice commands, and call local scripts for code execution, making it a helpful coding assistant that respects offline workflows. Another could watch a video lecture frame by frame while listening to the audio, then generate concise notes and answer follow-up questions. Because Gemma 4 12B runs as an open-weights model, you can fine-tune or prompt engineer it for specialized tasks like document question answering, multimodal customer support bots, or offline meeting summarizers. Its multi-token prediction support means responses arrive faster than many older on-device models, even on CPUs. For many users, this balance of speed, capability, and modest memory needs makes Gemma 4 12B a practical choice for everyday laptop-based AI.