Why AI Agent Cost Reduction Is Becoming an Infrastructure Problem
The economics of agentic AI are shifting from model accuracy to how efficiently systems handle context and computation. Teams deploying long-running AI agents quickly discover that token bills and GPU time, not just model quality, determine whether projects are viable. Token optimization and smarter GPU utilization now sit at the core of competitive AI operations. Instead of throwing larger models and more accelerators at every workflow, developers are rethinking how agents remember, route, and reuse work. This is where open-source AI tools are starting to change the equation. By exposing low-level controls over memory and routing, emerging projects let smaller teams implement cost strategies that used to require proprietary infrastructure and large budgets. Two recent examples—OpenSquilla on the runtime side and MinIO’s MemKV in the data layer—show how open architectures can directly translate into lower token consumption, less recompute, and more predictable operating costs for AI agents.
OpenSquilla: Smarter Routing and Memory to Cut Token Spend
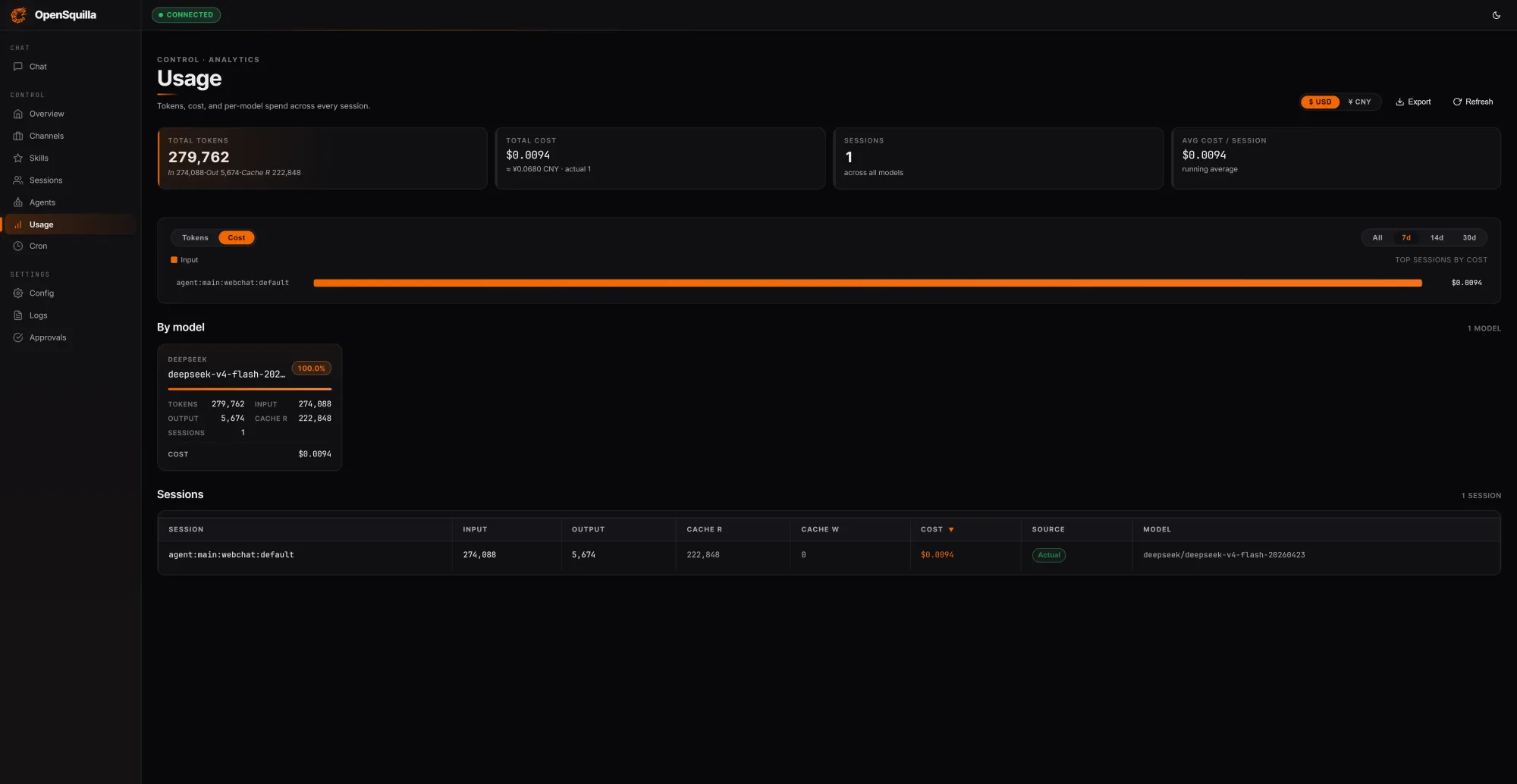
OpenSquilla’s open-source AI agent runtime is built explicitly for token optimization. In tests on three prompts totaling 279,762 tokens, it served 222,848 tokens from cache—about 80% of all input—demonstrating how aggressive context reuse can shrink token costs for long-horizon tasks. Instead of pushing every request through a single expensive model, an ML classifier scores each query by complexity, using signals like message length, presence of code, and semantic embeddings. Simple questions route to cheaper models, and deep reasoning is disabled for lightweight tasks, avoiding unnecessary chain-of-thought generations. Skills load on demand rather than being bundled into every context window. These design choices allow OpenSquilla to report 60–80% token spend reduction versus flat, single-model setups, directly improving AI agent cost reduction. With built-in quota hooks and per-call cost tracking, teams can monitor token optimization in real time and automatically throttle workloads before budgets are exceeded.
Human-Like Memory Architecture as a Cost Lever
Beyond routing, OpenSquilla tackles cost reduction through a four-tier cognitive memory design that mimics human memory rather than typical stateless prompts. Working memory holds the current task, episodic memory captures experiences and causal links across sessions, semantic memory stores stable facts and rules, and raw memory acts as a long-term audit and retraining base. Retrieval blends vector-semantic search with BM25 full-text search, running in parallel for better recall quality. Embeddings are computed locally via ONNX inference, so teams keep data on-device and avoid extra calls to external providers that consume tokens. A hot-memory promotion mechanism automatically surfaces frequently used items, while temporal decay lets stale information fade unless marked evergreen. Daily consolidation turns scattered memories into denser knowledge. Together, these mechanisms reduce the need to resend large histories on every turn, lowering token footprints while preserving the long-term context that agentic AI depends on.
MemKV: Eliminating GPU Recompute Tax for Better Utilization
On the infrastructure side, MinIO’s MemKV targets a different but related cost center: GPU utilization lost to recompute. As agents perform multi-step reasoning, context often evaporates near the GPU because local memory cannot hold it, forcing models to redo prior calculations. MinIO labels this the “recompute tax,” a structural drag on dense GPU clusters. MemKV introduces a flash-based context memory layer with microsecond retrieval over 800 GbE RDMA, designed to provide persistent, shared state across GPU clusters. Benchmarks published by the company highlight more than 95% better GPU utilization and roughly 50% lower cost per token by reducing redundant computation. By turning context into durable, addressable state—more like a database row than a cache entry—MemKV enables “context-as-a-service.” Any replica can resume a conversation mid-flight without sticky sessions, allowing schedulers to route work to whichever GPU is free while still reusing previously computed context.

Democratizing Token Economics for Startups and Mid-Market Teams
Taken together, OpenSquilla and MemKV illustrate how open-source AI tools are pushing cost optimization techniques down to smaller teams. Previously, fine-grained token optimization, memory tiering, and cluster-wide context sharing were the domain of well-funded enterprises with custom infrastructure. Now, mid-market organizations and startups can pair an open-source agent runtime that aggressively reduces token spend with an open context store that curbs recompute and boosts GPU utilization. For agentic AI, where value emerges from long-running, multi-step workflows, reducing both token consumption and recompute overhead directly impacts viability. Lower cost per token, better TTFT and TPOT, and fewer idle GPUs make it feasible to run more agents, on more tasks, for longer durations. As the industry shifts from model benchmarks to token economics, open, composable infrastructure is becoming the key enabler for teams that want advanced AI agents without enterprise-scale budgets.